flex/bison是对lex/yacc的开源实现,可以方便地进行编译器构造。MSVC下的flex和bison有着win_flex和win_bison这两个封装,用起来比较方便。
本文就使用flex和bison进行编译器构造时出现的一些问题进行说明,并讨论一些进阶技巧,例如重定向输入流,处理大小写不敏感代码串,yymore,代码定位,错误信息及恢复,start condition,扩栈,push parser,glr-parser,%define指令,常见语法和错误处理方法以及flex/bison生成代码分析等。
在VS2015下配置
在Sourceforge上下载 win flex-bison插件。下载后解压,将custom_build_rules文件夹按照右击项目->生成依赖项->生成自定义->查找现有的->选择custom_build_rules文件夹并添加确定。由此可以创建以.l结尾的flex文件和以.y结尾的bison文件。为了能够编译,还需要讲win_flex和win_bison复制到.l和.y所在目录下面。同时工具->选项->项目和解决方案->生成并运行可以选择输出的详细级别,改成普通之上可以得到flex和bison的编译输出信息。
flex使用说明
如何重定向输入流yyin
可以使用yy_scan_buffer函数重定向输入流,这个函数实际上调用了void yy_switch_to_buffer函数设置static YY_BUFFER_STATE * yy_buffer_stack的栈顶YY_CURRENT_BUFFER_LVALUE
下面的语句是一个完整的重定向输入流的模板,也可以参考这里的不使用yacc的模板
1 | // std::string in_str 被扫别识别的字符串 |
需要注意一点的是,buffer必须以”\0\0”结尾,原因是在生成文件*.flex.cpp中,函数yy_scan_buffer的部分代码如下:
1 | YY_BUFFER_STATE yy_scan_buffer (char * base, yy_size_t size ) |
可以看出base[size-2]和base[size-1]是有用途的。
顺便看一下yy_scan_buffer返回的typedef struct yy_buffer_state *YY_BUFFER_STATE类型
1 | struct yy_buffer_state |
可以发现这个结构储存了flex解析上下文。
如何实现迭代读取
不同于bison,flex中的yylex函数默认只返回int,用来表示识别出的终结符号的类型。但是我们有时需要返回更多东西,例如终结符号本身,终结符号的位置和长度等。
我们不能直接改变yylex的定义,因此可以用next_token封装yylex。假设要实现函数int next_token(std::string in_str, int start),能够识别非终结符[start, end],它的长度是内置变量yyleng,所在行是内置变量yylineno。
首先必须要能够记录当前读取后的位置。flex是不自带这个变量的,所以必须在每个规则的识别之后自动记录此时的读取位置,方法就是定义一个全局变量pos,并在每次识别后增加yyleng。事实上我们希望next_token能够返回一个结构FlexState,这个结构能够包含识别出的终结符号本身(如+、-、变量名var_name、整数或浮点数0.5之类的),识别出终结符号的类型(META_INTEGER、META_FLOAT等),长度,行号以及位置。我们定义一个FlexState结构来组织这些信息。调用层次如下:
next_token调用yylexyylex进行词法分析,如果满足某一模式(pattern)(也就是正则表达式),那么调用规则对应的处理语句(也称为动作(action),正则表达式对应的大括号内部的C代码)- 使用函数
int make_term_flex在规则对应的处理语句内构造FlexState并返回。 - next_token返回上步构造好的
FlexState类型的全局变量flex_state
特别地,如果还使用bison,因为bison直接调用yylex而不是自己设计的next_token获得词法分析的结果,所以处理语句必须返回用%token定义的YY_前缀的非终结符记号,由yacc的yyparse来返回你需要的YYSTYLE类型的值。鉴于这种情况,需要额外开一个flex_state的全局单例,在模式的处理语句中定义一个update_flex函数来更新flex_state。
关于bison的说明:bison提供了符号在代码串的定位功能,详见本文的bison部分。
yymore
yymore是一个flag,表明保留当前的结果yytext,等到读入下一个字符串时进行连接。例如当前读到的yytext是a,下一个字符是b,调用yymore以后下一次的读取yytext就会变成ab。调用yymore函数只会设置一个flag,并不立即读取下面的字符并进行拼接。
注意区分yymore和没有return的处理语句的关系。首先flex在编译时直接将处理语句大括号内的部分复制到yylex函数中的某个位置,所以return实际上是return的yylex函数。没有return只是yylex函数继续运行,进行下一轮的扫描;但是yymore是设置一个flag,表明不要清空yytext,依旧可以return返回,虽然这样做没有意义。
事实上处理语句不return是个相当有用的特性,有了这个并不需要yymore,只需要在全局记录一下本次的yytext到字符串s,在下一次查看yytext是否为空串,如果不是,返回s + yytext即可。而由于不返回了,所以在写处理语句于并不能利用函数来复用代码,而必须使用宏,同一个处理语句既可能return,有可能不return。
下面给出一段代码和运行结果以供参考:
1 | %{ |
运行结果
111 // 输入
1
yytext 1
11
yytext 11
111
yytext 111
222 // 输入
2
2
2
233 // 输入
2
33
常常希望在bison中使用yymore去处理区分else和else if的情况,然而往往每次的yytext并没有和上次叠加,原因主要有两点:1. 规则中出现了return。2. 空格没有yymore,导致打断。
使用flex处理非正则的文法
有一些特殊的词法,例如匹配的括号属于2类文法,flex所依赖正则表达式并不能正确处理这样的文法。而无论是手撸词法分析,或是直接放到语法分析阶段(可能造成归约冲突)并不是一个好办法。
对于简单的情况,可以给flex“打洞”,拿出这些特例进行处理。例如可以在识别出某些开始符号后,从当前位置调用某个外部函数进行处理并返回外部函数处理的结果。这样的限制是不能处理比flex单元更小的词法单元,如果flex中有一条匹配[0-9A-Za-z_]的规则,那么要使用这种方法处理[0-9A-Za-z]的规则是不行的,需要配合yyless(n)来回退yylen - n个字符。并且最重要的一点是外部函数处理过的那一段字符串仍然会被flex程序处理,这当然可以通过yyrestart来强行解决,但是有下面更好的办法。
根据StackOverflow上的一篇回答,可以通过start conditions这个功能处理这个问题。
要使用start condition,首先要使用%s或者%x来声明,其中%s表示使用这个start condition时还可以同时接受普通规则;而%x,x表示exclusive,表示使用这个start condition时忽略所有的普通规则。
现在使用%x format定义了名字是format的start condition,可以在规则前加上<format>来说明这个规则属于format condition,那么这条规则只有在使用BEGIN(format)开启format condition之后才能被匹配到。使用BEGIN(0)可以退出当前的condition,回归普通模式。
下面给出一个样例:
1 | %{ |
输出结果是
111format(222)333 // 输入
normal: 111
format: 222
normal: 333
在实际处理fortran的format语句过程中,还遇到了Syntax Error的错误,产生在将整个format语句作为一个YY_FORMAT_STMT终结符return,后来发现这是因为我在word_parse函数中处理format前缀时调用get_flex_external_context().begin_external_scanner("format");来开启start condition之后并没有return YY_IGNORE_THIS所致,因为这个format前缀仍然是作为普通规则而不是start condition处理的。加上C++本身的“不是所有路径都返回值”导致的UB错误。
bison的定位功能
bison提供了获取终结符行号和光标位置的功能。可以使用@n访问第n个文法符号的first_line、first_column、last_line、last_column属性,所以如果只需要这四个属性,可以不定义自己的struct,而使用bison提供的YYLTYPE。
1 | typedef struct YYLTYPE |
但是我仍然建议自己处理定位信息,这样的好处是在词法分析阶段就可以对源语言中与目标语言关键字冲突的符号进行转义,而不影响语法分析阶段对代码的定位。例如如果fortran中声明int变量,那会和C++中的int类型声明产生冲突,这个问题宜在词法阶段直接替换解决,但是这会带来长度的变化,因此需要单独维护原来文本的长度。
重命名yylex
我们知道bison会调用yylex来获得tokenizer返回的结果,而yylex是有flex直接生成的。有时候我们不希望直接把yylex函数产生的原始结果喂给bison,而是进行加工。这时候我们可以自己定义yylex函数,而给flex自动生成的函数进行重命名
#define YY_DECL int pure_yylex(void)
此时我们就可以自定义yylex函数了,bison会调用我们自定义的yylex函数,而我们的yylex函数可以通过pure_yylex去调用flex进行分析。
特殊情况的处理
- 读入字符不属于任意规则
如果不加处理,这个字符会被保留,例如,www如果定义了[A-Za-z]规则但没有定义,www规则会直接返回,www,但是匹配长度还是3。虽然可以再次截取出正确的字符,但是显然这是没有必要的。因此可以在最后为任意字符.加上规则。 - 到达读入字符串尾端
此时yylex函数返回0,这是为了配合bison端的yyparse函数设置的 - 用正则表达式表达字符串
\"(\\.|[^"])*\"
在flex的正则表达式语法中,方括号内部引号自动转义 - yymore_used_but_not_detected
需要在l文件第一部分使用%token yymore显式说明需要yymore函数。 - 根据manual,可使用一些语法来指定大小写不敏感的规则,但是要求flex的版本要高于2.5.3,配置时,在项目属性页选择Flex Files->FlexOptions->Case-insensitive mode
- 找不到入口点(main函数)
注意要将flex生成的cpp文件添加进MSVC项目中 - 多条适配规则
当有多条规则的模式被匹配到时,yylex会选择匹配长度最长的那条规则,如果长度相等,则选择排在最前面的规则。
bison使用说明
可以参考Bison的帮助文档或者Lex and YACC primer或者YACC文档
部分元素的意义
%left、%right、%token、%nonassoc
%token用来声明一个终结符号的类型(META_INTEGER、META_FLOAT等),这个函数将被放到.tab.h文件中供flex程序引用,上文提到的yylex返回的int值,实际上就是在这里定义的。
此外,%left和%right用来描述运算符的优先级和结合性。考虑二义性文法:E : E + E| E - E| E * E| E / E| i,考虑1 + 2 * 3,解析完2之后直接归约或者进行移进产生了冲突。当然我们可以写成以下的无二义性文法避免+-和*/之间的移进归约冲突,当然这样带来了比较多的归约步骤,E : E + T| E - T| T T : T * F| T / F| F F : i因此我们规定每个操作符的优先级,方法是较上行的%left(%right,%nonassoc)定义比较下行的%left(%right,%nonassoc)定义优先级要低,这样解决了不同操作符的优先级问题,而且相对于引入TF终结符,我们可以少定义一些非终结符和产生式(参加下例)。
但是对于1-2+3,分析程序仍然是不知道按照(1-2)+3还是1-(2+3)归约。因此对于同优先级的符号,用%left和%right来规定结合性。
%nonassoc表示当前操作符op是没有结合性的,也就是说不可能出现x op y op z的这种情况。yylval,%type,YYSTYLE,%union
前面说到yylex返回值是一个int,这对于语法分析是足够的,但是对于之后的语义分析是不够的。例如对于属性文法E.val->T1.val + T2.val,我们还需要语法分析时候顺便把属性也提取出来,相比扩充状态栈,yacc提供了一个YYSTYPE类型的全局变量yylval。这个YYSTYPE的类型是个宏,可以自定义,相比flex的yylex函数只能返回int显得方便了很多。
同时,对于不同的属性,bison可以直接给出parse之后的类型。例如对于浮点123.4,yacc能够解析出123.4。这是因为bison通过%union来列出yylval返回值类型,通过%type规定对于什么非终结符返回什么类型。例如,1
2
3
4
5
6
7
8%union{
int intval;
double floatval;
char word[20];
}
%type <intval> YY_INTEGER
%type <floatval> YY_FLOAT
%type <identname> YY_WORD这里%union实现上就是C++中的联合
union。union不同于struct,它的所有成员时分复用存储空间,因此一个union的大小等于所有成员大小的最大值。和reinterpret_cast一样,union可以用来规避C/C++中的类型检查,实现强制转换,使用union相对使用void*避免了较多的reinterpret_cast。%start
%start用来标注开始符号,这是可选的<<EOF>>
顾名思义,用来匹配文件结尾
bison的二义性问题解决方法
bison的默认parser是LR parser,虽然LR文法是不能出现移进归约冲突和归约归约冲突的,但这不意味着bison的LR parser不能处理部分二义性问题。
悬挂
if-else问题
bison在处理移进归约冲突的解决办法是默认移进。处理归约归约冲突的办法是默认使用先出现的产生式。因此bison中使用stat:YY_IF exp YY_THEN stmt | YY_IF exp YY_THEN stmt ELSE stmt是默认没有问题的
当然也可以使用运算符优先级来解决这个问题%nonassoc IFX %nonassoc ELSE stmt: YY_IF exp stmt %prec IFX | YY_IF exp stmt YY_ELSE stmtelse if问题
可以考虑将else if合并成一个YY_ELSEIF终结符
部分语法的翻译方法
换行符和空规则
bison中的空规则类似下面的形式
nonterminal : non_empty
{}
| /* empty */
{}
空规则的意义在于必须要在处理语句内{}处理更新$$,不然$$是不确定的,可能是上一次的结果。
注意如果没有显式指定处理语句,bison默认情况下把$1的值拷贝给$$。
在许多语言中,换行符用来分开两个语句stmt,而一个语句不一定占用一行,因为一个语句可以是一个表达式exp,也可以是一个复合语句,如if_stmt,do_stmt等。如果不能正确处理换行符,可能会出现各种各样的Syntax Error。比较好的做法是,定义一个suite
stmt : /* 在结尾不要带上换行符 */
| /* stmt可以是空语句 */
suite : stmt end_of_stmt suite
| stmt
这实际上类似于处理参数表的方法。
注意往往还有一种写法是
stmt : exp end_of_stmt
suite : stmt suite
| stmt
program : suite
这样写的坏处是容易出现list : item list这样的语句,这样的语句会给语法带来很大的不确定性,例如上面的产生式中suite是和stmt归约到新的suite还是直接归约到program是不确定的,并且在出现连续的空行的时候往往不能正确匹配。
控制结构
可以参照这里提供的例程
终结符
对于ascii码表中的字符终结符,如+,*等运算符,这些字符会在yylex以自身ascii码的形式返回(如果定义了相应规则或者.规则)。而一些非字符形式的终结符,例如C++中的生存空间符号::,则需要通过%token(%left,%right)定义。这也是为什么%token(%left,%right)生成的终结符对应的index从258开始的原因(避开ascii表)。
当然也可以自己来定义终结符号的类型所对应的值,好处是,我们可以用值的大小表示优先级关系(虽然bison中可以用%left等语句来规定),可以用正负表示一个操作符或者一个操作数或者关键字。出于此,可以直接在%token YY_INT META_INTEGER给YY_INT赋值,而不是由Bison决定。特别注意不要重定义0,这是yylex和yyparse的结束记号。
自定义类型的yylval
yylval的类型是YYSTYPE,可以用它来保存bison中的非终结符,统一起见,flex程序中的终结符也可以封装成YYSTYPE类型。考虑到在解析过程中,bison程序通过直接调用int yylex()方法来从flex程序中获得终结符号,所以flex中程序获得的一些额外信息可以通过yylval向bison程序传递。
在自定义类型YYSTYPE为non-trivial类型后,会出现不能自动扩栈等问题,应当谨慎使用。
tldp文档提供了两种方案
#define YYSTYPE structXXX
可能出现错误缺少类型说明符 - 假定为 int。注意: C++ 不支持默认 int。,经查看,源码中有:1
2
3/* for90.tab.h */
// YYSTYPE is not defined, YYSTYPE_IS_DECLARED is not defined解决方案是不在.y和.l文件中
#define,而是在一个.y和.l文件共同#include的头文件中#define。使用%union将struct包起来
使用这种方案不需要#define YYSTYPE,同样查看源码:1
2
3
4
5
6
7
8
9/* for90.tab.h */
typedef union YYSTYPE
{
/* Line 387 of yacc.c */
FlexState fs;
/* Line 387 of yacc.c */在以上步骤之后要确认这个union的定义是有的。
可能会出现如下问题:错误 C2280 “YYSTYPE::YYSTYPE(void)”: 尝试引用已删除的函数。对应代码为:1
2
3
4
5/* The semantic value of the lookahead symbol. */
YYSTYPE yylval YY_INITIAL_VALUE(yyval_default);
和
/* The semantic value stack. */
YYSTYPE yyvsa[YYINITDEPTH];
这两个函数/数组定义要求union实现构造函数和析构函数,但是这个是不行的。后来发现union中成员必须是trivial的,也就是包含构造函数/析构函数/拷贝构造函数/赋值运算符/虚函数的类成员,在union中都是不被允许的,所以改成union的成员改成对应的指针就可以了。
实现non-trivial的YYSTYPE
根据Type-Generation,似乎可以通过%define api.value.type来解决这个问题,但是需要bison 3.0的版本,win_bison似乎并不支持
如果使用的是win_bison的话,最好的方法是将YYSTYPE改成对应的指针形式。这可能会带来一些内存管理上的更改,之前的RAII似乎不能够使用了,此外shared_ptr和unique_ptr也不是trivial的(但是是standard layout)
左递归和右递归的选择
对一些分析方法(如自上而下的不带回朔的递归下降法)来说,左递归不是省油的灯,例如LL1递归下降分析法直接要求消除左递归。
例如LR(1)这样的移进-归约形式的分析方法允许左递归,左递归(产生式右部第一个符号时非终结符)是有弊有利的。
右递归文法可能会占用比较大的栈空间,因为首先要将所有的项都压入堆栈里,然后再归约。
大多数时候,左递归和右递归可以交换使用。例如处理else if的产生式可以写成:
1 | elseif_stmt : YY_ELSE YY_IF exp YY_THEN stmt |
对于参数表更简单:
1 | argtable : exp |
它的右递归形式
1 | argtable : exp |
这样的文法并不能处理
1 | 1, a = 2 |
这样的文法,因为1不是keyvalue
但是无论是左递归还是右递归,由于bison不支持EBNF,所以语法分析树总是往深度方向生长的,所以最好的做法是每一次处理item op list这样的规则时,将结果得到的树压平,注意压平操作要分左递归和右递归,否则顺序可能会有问题。
不过拍平操作往往伴随着很大的性能损失,所以最好为自己的YYSTYPE写好复制构造函数。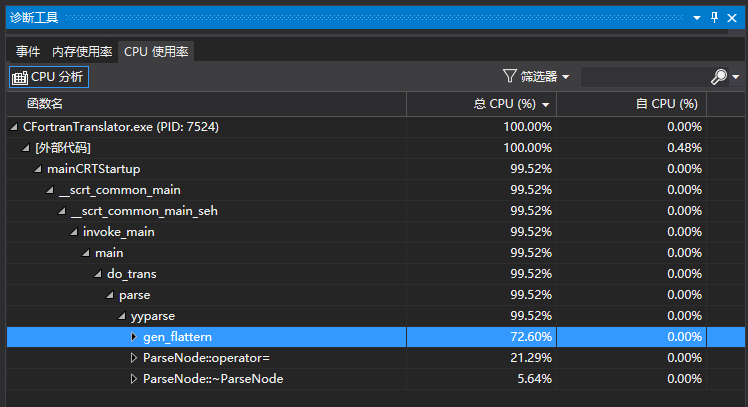
bison常见错误及调试方法
使用debug模式调试
1 |
注意yymsgp是const char*,所以如果重新定义yyerror参数要注意。
1 |
|
此外还可以在项目属性页选择Flex Files->FlexOption或对应的Bison标签页中开启DEBUG模式。
使用output文件分析语法冲突
在bison生成的时候可以在输出中看到类似的语句:
1 | 1> BisonTarget: |
这表明有132个移进归约冲突和33个归约归约冲突,这在二义性部分已经有相关的论述
当出现冲突的时候可以使用bison -v xxx.y命令来查看具体的冲突。该命令会生成一个xxx.output文件
在output文件中,所有因为冲突无用的产生式会被中括号[]括起,通过分析,可以解决一部分的冲突
m4sugar.m4
win_bison: …\data/m4sugar/m4sugar.m4: cannot open: No such file or directory
这个文件在和custom_build_rules文件夹同层的data文件夹中,所以注意是否将data文件夹加入路径
yylex identifier not found
注意在y文件中第一部分extern yylex声明。
memory exhausted错误
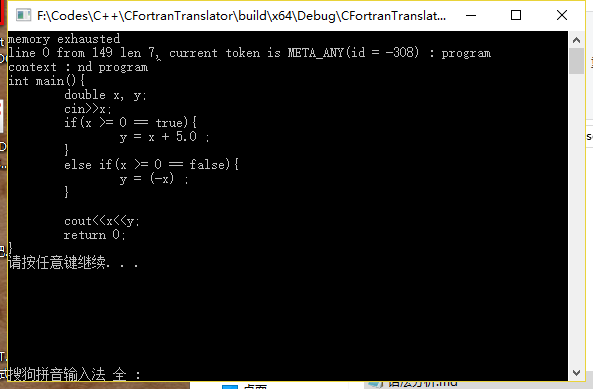
首先检查语法是否出现冲突,通常出现在语法嵌套比较深,从而出现间接的无限递归的情况。例如:
1 | suite : stmt |
需要去掉wrapper的suite分支
其次可以通过扩栈来解决,栈的大小可以通过#define YYMAXDEPTH来指定(默认10000),但是bison只有当确定对象是trivial的时候才会去扩栈:
#ifndef YYSTACKEXPANDABLE
# if (! defined __cplusplus \
|| (defined YYSTYPE_IS_TRIVIAL && YYSTYPE_IS_TRIVIAL))
# define YYSTACKEXPANDABLE 1
# else
# define YYSTACKEXPANDABLE 0
# endif
#endif
所以更好的方式是使用#define YYINITDEPTH来规定初始栈的大小(默认200)
bison生成代码.tab.cpp分析
有的时候会出现可能会导致Syntax Error,检查tab.cpp中的代码,发现
1 | if (yychar <= YYEOF) |
其中yycheck[yyn] != yytoken这个条件是不满足的。
这个时候就需要查看bison对.y文件经过编译结果,也就是.tab.cpp文件。其中有一些数组对debug来说比较重要,要了解这些数组的用途,对于LALR(1)文法应当理解。
bison的GLR parser
有的时候语法冲突是很难解决的,这时候与其去死扣语法,不如使用bison提供的GLR parser
加上%define %glr-parser可以使用GLR parser。
flex/bison和antlr比较
ANTLR(Another Tool for Language Recognition)顾名思义是另一个生成工具,相比bison是LALR/GLR,ANTLR是LL/ALL/SLL的,不过它对传统的LL文法解析做了优化。例如ALL算法能够在LL遇到多个可能分支的时候对每个分支启动一个DFA直到产生匹配,而这种DFA也是可以缓存的。此外,ANTLR能够解决一些直接左递归。
ANTLR在解决冲突时和bison差不多,例如它规定了优先级按照规则的先后顺序而优先匹配,也可以指定符号的结合性。非常好的是ANTLR提供了在语义层面解决冲突的方法。
ANTLR还支持Channel,也就是处理类似注释这种与上下文无关,但有可能出现在任何地方的非终结符,在flex+bison中,我是在词法分析阶段抽出来做的,而ANTLR可以发送给通道,并在目标代码生成时进行处理。ANTLR还可以解决上面需要借助flex中的start condition才能解决的同一代码文件中不同语言和不同语言版本(例如我遇到的Fortran77/90混杂)的问题,也就是借助于语义或者mode语句。

