本文作为一个专题来讨论TCP可靠传输的实现,其中部分论述迁移自TCP的流量控制和拥塞控制。
tcpdump 介绍
下面表示分组序号是111,报文中包含0字节。这个报文是一个 SYN。
1 | S 111:111(0) |
注意虽然长度为0,但 SYN 和 FIN 都占用一个序号。
序号
ACK序号表示下一次期待收到的序号,是最末尾的字节数+1。
需要注意的是SYN和FIN报文,即使没有payload,也会占用一个序号,这就有点类似于sizeof空struct一样。
连接的建立
Listen和Accept
Listen的(本地ip, 本地port, 远程ip, 远程port)四元组一般是(*, 本地port, *, *)。我们可以通过netstat查看到出于Listen状态的端点。
当连接建立后,四元组就确定了,通过netstat可以看到一个Established的条目。
Accept在三次握手完成之后才会返回。
Backlog
- 三次握手完成的连接,会进入一个队列,这个队列有一个backlog用来维护它的长度
- 当新的SYN到来时,也要根据这个队列的长度判断是否接受这个SYN,如果不接受,那么也不返回RST,因为我们可能只是暂时不能接收
同时打开和同时关闭
普通连接是:
- 客户端发送 SYN
- 服务端监听并回复 SYN+ACK
- 客户端回复 ACK
同时打开是:
- 双方都主动发 SYN,然后都收到对方的 SYN,再都回复 SYN+ACK,最后都确认 ACK。
同时打开的情况下,其实还是产生一个连接。TCP 协议栈会根据四元组识别并合并这两个连接请求,从而只建立一个连接。
重传机制
基本问题
- 为什么要重传?
显然,因为 TCP 是可靠传输协议。 - 如何判定需要重传哪个包?
最基础的判定依据是超时。超时时间称为 RTO,即 Retransmission Timeout。RFC 793 推荐 RTO 和 RTT 成比例,其中 RTT 指往返时间,也就是发送报文段到报文段被确认的时间。
指数退避
重传多义性问题
假设当超时发生时,RTO 进行退避,导致分组以更高的 RTO 进行重传,然后收到一个 ACK。那么这个 ACK 是对第一个发送的分组,还是第二个发送的分组呢?
Karn 算法规定,当超时和重传发生时,并不更新 RTT。因为我们无法判断这个 ACK 是对第一次传输,还是第二次重传的回复:
- 也许第一次的包被丢弃了,ACK 是第二次的回复。
- 但同样,也可能第一次的包没有被丢弃,ACK 就是第一次回复。
RTT 以及 RTT 的测量
根据在“重传多义性问题”中的论述,如果发生了重传,其实计算 RTT 就没有意义。
从图中看到,重传计时器是“全局唯一”的。例如在传输报文4的时候,因为在传输报文3的时候,计时器已经被启动,所以这个报文段不会被用来计算 RTT。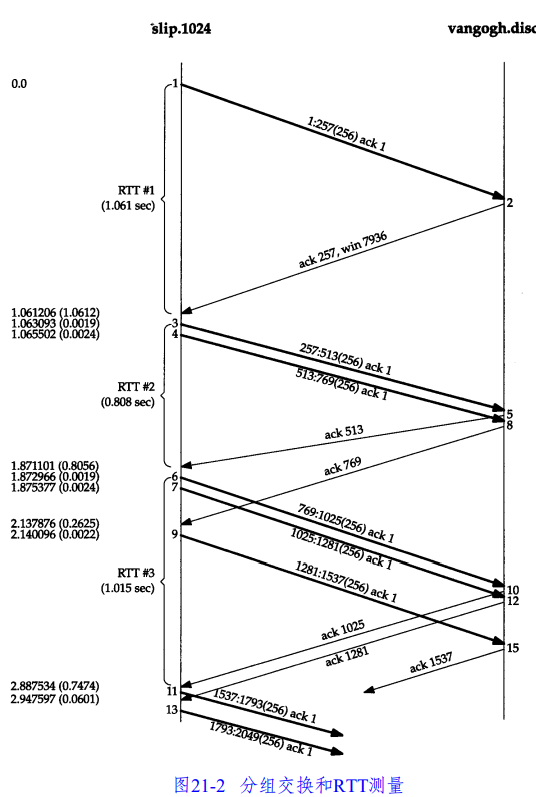
在我 ATP 中也实现了 Karn 算法。
重传定时器
tcp_syn_retries
tcp_synack_retries
tcp_retries2
为什么是三次重复的ACK
为什么至少收到三次重复的 ACK 而不是两次,才会被认为可能发生了丢包呢,并重传呢?
考虑 N-1、N、N+1、N+2 包,我们计算收到 ACK = N 的数量。注意 ACK 表示下一个要发的 seq,所以如果 ACK = N,说明目前只确认到 N-1。
首先考虑乱序情况,为了简便表示,我们直接省略 N,而用 delta 值来记录:
- -1 0 1 2
收到1个。 - -1 0 2 1
分别收到0/1/1/3。故收到1个。 - -1 1 0 2
分别收到0/0/1/3。故收到2个。 - -1 1 2 0
分别收到0/0/0/3。故收到3个。 - -1 2 0 1
分别收到0/0/1/3。故收到2个。 - -1 2 1 0
分别收到0/0/0/3。故收到3个。
容易看到,乱序的情况下,什么时候收到 N 这个包决定了收到重复的 ACK = N 的数量。因此,全部六种顺序中,有1/3的情况 N 会在最后一个收到。那么3包乱序的情况下,收到3个重复 ACK 的概率是2/(6-1)=0.4。
同理可得,如果只考虑2包乱序,那么收到2个重复 ACK 的概率就是 1/2。根本无法做区分。
下面考虑丢包的情况。很简单,因为一直没收到 N,所以 ACK 一直是 N:
- -1 1 2
分别收到0/0/0。三个 ACK。 - -1 2 1
分别收到0/0/0。三个 ACK。
可以发现在丢包的情况下,一定收到三个重复的 ACK。
如果收到三个重复的 ACK,可以执行快速重传算法,在TCP的流量控制和拥塞控制中有讲解。
重新分组
TCP 是一个流式的协议,所以当一个分组超时并且重传时,TCP 不一定要重传相同的分组。它可以重新分组,并发送一个更大的报文段(当然不能超过 MSS),从而提高性能。
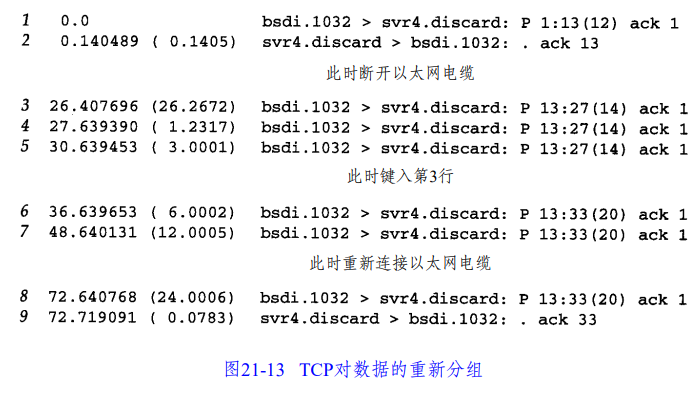
连接管理
保活定时器
需要请用 SO_KEEPALIVE。
从TCP对长连接的管理上来讲,服务器通常会对其的对端启用保活定时器,以避免在对端意外崩溃下连接的浪费。我们看到TCP是非常珍惜服务器端的连接资源的,这还体现在TCP往往鼓励客户端主动关闭,从而让客户端而不是服务端等待2MSL。
TCP规定当连接在两个小时之内无任何动作,则服务器向对端发送探测包。根据客户端的状态会分为四种情况:
- 当客户端和网络都正常时,那么服务器能够得到正常响应,于是复位保活定时器。
- 当客户主机崩溃,比如在关闭或重启中时,客户端没有响应,服务器会等待10次75秒的超时,直到关闭连接
在这过程中,可能收到 ICMP 的 unreachable 报错,这对 TCP而言是个软报错。 - 当客户主机从崩溃中恢复后,服务器将受到来自客户端的RESET。
- 当客户端正常运行,但网络异常,类似网络分区状况,这种情况类似2。

