在比较早的时候,我使用腾讯文档记录一些数据库的论文。但我越来越无法忍受腾讯文档的 bug 等不便利。因此我打算将这些文章转移到博客中,即使它们中的部分的完成度并不是很高。
这篇文章中,包含 CStore、Kudu、Masstree 和 Ceph。
CStore
C-Store 引入了一个混合架构,包括一个针对频繁插入和更新优化的写存储组件 WS 和一个针对查询性能优化的读存储组件 RS。这也是 TiFlash 列存的 Delta Merge 架构的来源。
按照 projection 存储,一个 projection 对应了一个表的一个或者几个列。
每个 projection 有自己独立的 sort key。不同的 projection 之间,用 join indexes 来维护它们的对应关系。
每个 projection 会水平分区为多个 segment,每个 segment 有自己的一个 sid。
每个 segment 分为 RS 和 WS。storage key 用来表示在 segment 上的一行。定义 storage key:
- 在 RS 上,直接按序存储,通过遍历获得 index
- 在 WS 上,每次插入获取一个 storage key,大于 RS 上的最大值
从上面看到,(sid, storage key) 可以唯一索引一个 key,它可能在 RS 上,也可能在 WS 上。
在 WS 上,projection 上的每一列用 B tree 来存,是按照 storage key 来排序的。所以还要额外维护 sort key -> projection key 的映射关系。
【Q】为什么 WS 上也不按照 storage key 自增来处理呢?这样就不需要一个 B tree 了啊。这是因为同一个 Segment 中不同列里具有相同 SK 的数据属于同一个 Logical Tuple,所以实际上是做不到递增的。为什么要这样设计呢?原因是 join indexes 就可以只维护每个 projection 上每一行到 (sid, storage key) 的映射关系就行了。如下图所示
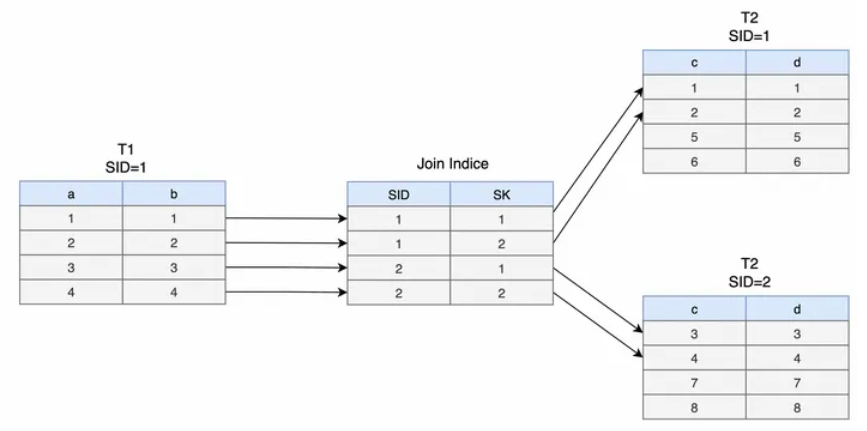
从实现上来讲,当一个 tuple 到 WS 的时候,为它分配一个 storage key 也是很自然的。
对于只读查询来说,如果允许其读取过去任意时间的快照(其实就是 Time Travel Query),代价是非常大的。C-Store 维护了一个高水位(High Water Mark,HWM)和一个低水位(Low Water Mark,LWM),这两个水位其实对应了只读查询可读取的时间范围的上限和下限。
CStore 的 MVCC 是以 epoch 为单位的。epoch 的粒度应该是比较大的。我们可以读 epoch e 上的事务,当 epoch e 上的所有事务都被提交完毕。
RS 的存储有优化:
1.排序列+Cardinality 较少:run length 编码
2.排序列+Cardinality 较多:bitmap 编码
3.非排序列+Cardinality较少:delta encoding
4.非排序列+Cardinality较多:正常存储
Kudu
https://kudu.apache.org/kudu.pdf
Hadoop 系统中的结构化数据的两种存储方式:
- 静态数据
使用 Avro 行存或者 Parquet 列存来存储,但它们对 UPDATE 单条记录,或者随机访问并不友好。 - 可变数据
存在 semi-structed 仓库中,类似 HBase 或者 Cassandra。
这些存储有很低的读写延迟,但是相比静态数据,其顺序读写的带宽不高,从而不适用于 OLAP 或者机器学习。
一种折衷的方案是像 Cloudera 的一些用户一样,数据和修改流式写入 HBase,再定期导出为 HDFS 上的 Parquet 文件。但这样的架构会有以下问题:
- 应用端要写复杂的代码维护两套系统。
- 要跨系统维护一致性的备份、安全策略、监控。
- 更新进入 HBase 到最终能被查询到的延时可能很久。
- 实际场景中经常有要修改已经持久化到 HDFS 的文件的需求,包括迟来的数据,或者修正之前的数据。文件重写是高开销的,还可能要人工介入。
Kudu 从一开始就想要 high-throughput sequential-access storage systems(HDFS) 的好处,也想要 low-latency random-access systems(such as HBase or Cassandra) 的好处。Kudu 是选择成为一个 happy medium 选择。In particular, Kudu offers a simple API for row-level inserts, updates, and deletes, while providing table scans at throughputs similar to Parquet, a commonly-used columnar format for static data.
综述
Write
Read
Kudu 只提供一个 Scan 操作。Scan 操作支持两种 predicate:comparisons between a column and a constant value,
and composite primary key ranges。
用户可以为一个 scan 指定 projection。因为 Kudu 的盘上存储是列存,所以指定 projection 能够显著提高效率。
Consistency Model
The default consistency mode is snapshot consistency. 这里应该说的类似 Snapshot Isolation 吧。
A scan is guaranteed to yield a snapshot with no anomalies in which causality would be violated.
As such, it also guarantees read-your-writes consistency from a single client.
Timestamp
不像 HBase 或者 Cassandra 一样将时间戳作为 first-class 的对象。
Partitioning
类似于大多数的水平分布的数据库系统,Kudu 里面的 table 也是 partition 的,Kudu 和 Bigtable 都把它们称作 horizontal partitions tablets。每个 row 会被映射到一个 partition 上。对于需要吞吐量的大表,Kudu 推荐一个机器上有 10-100 个 tablet,每个 tablet 可以有 10GB 大小。
Bigtable 只提供 key-range 形式的分区,Cassandra 基本只会使用 hash 分区,Kudu 同时支持两种分区方式。
The partition schema is made up of zero or more hash-partitioning rules followed by an optional range-partitioning rule:
- Hash Partition 将 tuple 中的某些 column 连接起来组成 binary key,然后计算这个串的 hash 值。
比如DISTRIBUTE BY HASH(hostname, ts) INTO 16 BUCKETS会将指定的这些列连接起来,然后计算结果的 hash,并 mod 下 bucket 的总数。 - Range Partition 将 tuple 中的某些 column 连接起来组成 binary key,然后用 order-preserving encoding 来确定所处的 range。
Replication
Kudu 的 Leader 会负责用本地的 Lock Manager 去串行化 Concurrent 的操作,选择对应的 MVCC 时间戳,并且 propose 到 Raft 上。Raft 层复制的是每个 tablet 的逻辑日志,比如 insert、update、delete 等。
Kudu 说 there is no restriction that the leader must write an operation to its local log before it may be committed,所以能够保障很好的延迟。这里指的应该是 Raft 的 commit,也就是说只要有 quorum 的节点持久化日志就行,Leader 未必要持久化对应的日志,其实也是对 Raft 的优化。
此外,它还列出了两点和 Raft 有关的优化,这里略过。
再次强调,Kudu 并不是复制 tablet 的物理日志,而是 operation log。它的目的是在各个 Replica 之间解耦,从而得到下面的好处:
- 避免所有的 replica 同时经历物理层的开销较大的操作,比如 flush 或者 compaction。这可以降低 client 在写入时感受到的 tail latency。后续还可以实现 speculative read requests,从而减少读的 tail latency。
当然,我觉得这也有坏处,例如各个 Replica 之间的 Snapshot 不太好做了。实际上也是 TiKV 做的时候面临的取舍。 - 有机会及时发现某个 replica 被 corrupt 了,从而即使进行修复。
针对 Raft 的成员变更,主要引入了 Pre Voter,我理解类似于 Learner 追进度的方式来保证不损失可用性。
Master
这里讲述的 Kudu 的 root service 的实现。主要包括的功能有:
1.作为 catalog manager,记录所有的 table 和 tablet,以及对应的元信息,比如 schema、replication level 等。处理 DDL。
2.作为 cluster coordinator,记录存活的 server,并进行 rebalance。
3.作为 tablet directory,记录每个 tablet 在哪些 server 上分布。
所以 Master 的工作量还是蛮大的,既要管理数据库的 schema,又要管理集群,又要管理数据分区。
catalog manager
Master 会管理一个专有的 tablet。它会在内部将 catalog information 写到这个 tablet 里面,同时也会有一个 full write-through 的 cache 在内存里面。Kudu 并不担心占用太多内存,如果后面确实占用了,就把它放到一个 paged cache 里面。
The catalog table maintains a small amount of state for each table in the system. In particular, it keeps the current version of the table schema, the state of the table (creating, running, deleting, etc), and the set of tablets which comprise the table.
- first writing a table record to the catalog table indicating a CREATING state
- Asynchronously, it selects tablet servers to host tablet replicas, creates the Master-side tablet metadata
- Sends asynchronous requests to create the replicas on the tablet servers
a. If the replica creation fails or times out on a majority of replicas, the tablet can be safely deleted and a new tablet created with a new set of replicas.
b. If the Master fails in the middle of this operation, the table record indicates that a roll-forward is necessary and the master can resume where it left off.
对于 delete 或者 change,会先 propogate 到相关的 tablet server,然后 Master 再写自己的存储。
A similar approach is used for other operations such as schema changes and deletion, where the Master ensures that the change is propagated to the relevant tablet servers before writing the new state to its own storage. 对于所有的情况,Master 发往 tablet server 的消息都是幂等的,这样在故障重启的时候,可以被重复发送。
因为 catalog 表也是存放在专有的 tablet 里面的,所以 Master 也会用 Raft 去复制持久化的状态,到 backup master 上。目前,backup master 只是作为 Raft follower,不处理 client 请求。当当选后,会扫描 catalog 表,加载内存中的 cache,并开始作为 active master 存在。
cluster coordinator
每个 tablet 会记录所有 Master 节点的地址。启动之后会开始向这些 master 不断汇报自己上面的 tablet。第一次汇报是全量,后面的是增量。
Kudu 有个关键设计,就是尽管 Master 是 catalog 的 source of truth,但是它只是集群状态的 observer。集群中的 tablet server 会提供比如 tablet replica 的位置信息、Raft 相关、schema version 等信息。tablet 的相关变化也是通过 raft log 记录的。因此 Master 可以借助于 raft log 的 index 去比较 tablet state 的新旧。
Tablet server 承担了更多的责任,每个 tablet 的 Leader replica 负责检查有没有 crash 的 follower。发现后会发起配置变更将这个 follower 移除,并在配置变更完成后通知 Master。Master 负责选择新 replica 所在的 server,然后让 Leader replica 发起新的一轮配置变更。
tablet directory
client 会直接请求 Master 询问 tablet 的位置信息,也会缓存很多最近的信息。当缓存的信息陈旧,则会被拒绝,此时需要重新联系 Master 要最新的 Leader。
Master 会将所有的 table partition range 存在内存中,所以请求变多,回复依然还是比较快。即使 tablet directory 变成瓶颈,Kudu 也可以返回陈旧的 location 信息。这里原因是客户端会失败,从而重试。所以论文中说 this portion of the Master can be trivially partitioned and replicated across any number of machines. 我理解是可以从 Master 的其他副本读,但这里实际上的瓶颈不应该是内存么?
Tablet storage
RowSets
Tablet 的下层结构是 RowSets。分为 DiskRowSets 和 MemRowSets。RowSets 的 range 可能重复,但如果一个 row 存在,那么一定只在一个 RowSets 中。
一个 Tablet 只有一个 MemRowSet。这一部分包括 flush 无需赘述。
MemRowSets
MemRowSets 是一个类似 Mass tree 的 B 树。但有一些优化:
- 不支持从树上删除元素。Kudu 也是通过 MVCC 来逻辑删除。
- 同样也不支持任意地 inplace 地修改树上的 record
作为代替,允许不改变值大小的修改,这样方便进行 CAS 操作。
允许 CAS 的目的是方便构建下面提到的链表。 - We link together leaf nodes with a next pointer, as in the B+-tree. This improves our sequential scan performance, a critical operation.
链表一般被用来链接 B+ 树的叶子节点,从而提高扫表效率。 - 并不完全实现 trie of trees,而是只使用一棵树。因为并不需要考虑极端的随机访问。
为了提高扫描性能,使用更大的 internal 和 leaf 节点大小,到 256 bytes 大小。
MemRowSets 是行存,因为内存结构,所以性能也是可以接受的。为了在行存下依然能够提高 throughput,Kudu 使用 SSE2 memory prefetch 指令,去 prefetch one leaf node ahead of our scanner。他还会 JIT-compile record projection operations。这些做法对性能提升很高。
最终插入到 B-tree 里面的 key 会根据每行的 PK,使用 order-preserving encoding 编码,从而只需要 memcmp 就可以实现比较。因此,在树上遍历会更加快。因为 MemRowSet 本来也是 sorted 的,所以也能提供有效率的扫描。
DiskRowSet
DiskRowSet 被分成若干个 32MB 大小的文件,目的是确保它不会太大,从而支持后面要将的 Incremental compaction。
一个 DiskRowSet 被分成两部分,base data 和 delta store:
base data
base data 是列存。
每个 Column 被单独存储。它们按照连续的 block 的方式被写入磁盘。一个 Column 本身被分成很多个小 page 来存储,从而保障随机读。有一个 B 树索引用来根据 row 的 offset 来查找它所在的 page。
Column page 的编码支持字典,bitshuffle 等格式。可以指定进一步的压缩方法。
除了 flush 指定的那些 Column 之外,还会写一个 PK 索引列,用来存储每个 PK 的编码后的 PK(应该就是前面说的 order-preserving encoding)。
还会存储 Bloom filter。
delta store
因为列存在 encode 之后就难以 inplace 更新了,所以更新和删除通过 delta store 来记录。
delta store 可以是 DeltaMemStores 或者 DeltaFile:
- DeltaMemStore 是一个和上面一样的 B 树。
- DeltaFile 是一个二进制编码的 column block。
delta store维护了 (row offset, timestamp) tuple 到 RowChangeList 的映射。其中 row offset 就是一个 row 在 row set 中的 index。timestamp 就是 MVCC 时间戳。RowChangeList 表示对一个 row 的变更,是一个二进制编码的 list。
在处理 update 时,首先查找 PK 列,然后可以通过它的 B 树索引来获得对应行所处的 page。然后通过查找这个 page 可以获得对应的 row 在整个 DiskRowSet 中的 offset。然后就可以根据这个索引插入一条更新的数据了。
因为 Delta Store 是以 row-offset 作为主键,所以相比于 Primary key 这个过程会更快。这就是为什么插入时要费那么多功夫去获取 row-offset,可以理解为 Kudu 在 Insert/Read 的性能平衡中更倾向于优化 Read 性能。
Compaction
Delta Compaction
因为 delta 并不是列存,所以当有很多 delta 被 apply 到 base data 的时候,scan tablet 的速度就会变慢。因此 Kudu 的 background maintenance manager 会定期扫描,寻找有大量 delta 的 DiskRowSets,然后调度一个 delta compaction operation,将这些 delta 数据 merge 到 base data 列中。
In particular, the delta compaction operation identifies the common case where the majority of deltas only apply to a subset of columns: for example, it is common for a SQL batch operation to update just one column out of a wide table. In this case, the delta compaction will only rewrite that single column, avoiding IO on the other unmodified columns.
RowSet Compaction
Kudu 也会定期将不同的 DiskRowSets 压缩到一起,这称为 RowSet compaction。这个过程会执行一个 keybased merge of two or more DiskRowSets,产生一个有序的 row 的流。然后就不听 next 这个流,从而写回到 DiskRowSet 里面。这里写回的 DiskRowSet 同样是 32MB 的大小。
RowSet compaction has two goals:
- We take this opportunity to remove deleted rows.
- This process reduces the number of DiskRowSets that overlap in key range. By reducing the amount by which RowSets overlap, we reduce the number of RowSets which are expected to contain a randomly selected key in the tablet. This value acts as an upper bound for the number of Bloom filter lookups, and thus disk seeks, expected to service a write operation within the table.
Scheduling maintainance
- 如果 insert 负担变重,则调度偏向于处理“flush”,也就是将 MemRowSets 写成 DiskRowSets。
- 如果 insert 负担减轻,则偏向于处理 rowset compaction 或者 delta compaction。
- Because the maintenance threads are always running small units of work, the operations can react quickly to changes in workload behavior. For example, when insertion workload increases, the scheduler quickly reacts and flushes in-memory stores to disk. When the insertion workload reduces, the server performs compactions in the background to increase performance for future writes. This provides smooth transitions in performance, making it easier for developers and operators to perform capacity planning and estimate the latency profile of their workloads.
Reference
Masstree
Intros
这里首先强调了,尽管可以 scale out,但是单机的性能依然很重要。然后 This paper presents Masstree, a storage system specialized for key-value data in which all data fits in memory, but must persist across server restarts. Within these constraints, Masstree aims to provide a flexible storage model.
它的 key 的长度是任意的,支持 range 查询。很多 key 可以共享前缀,从而提高性能。对于比较大的 value 也有优化。它使用了一些 OLFIT 和 rcu 的办法来处理并发:
- 查询不使用锁或者 interlock 指令,所以它不会 invalidate shared cache line,并且和大多数 insert 和 update 是平行的。
- update 只会锁相关的 tree node,树的其他部分不受影响。
Masstree 中所有的 core 都使用一棵树,从而避免 load imbalances that can occur in partitioned designs。相比于其他的将一棵树分开存储的设计,能够彻底解决 imbalance 的问题。
这棵树是 a trie-like concatenation of B+-trees。对 long common key prefixes 特别友好,遥遥领先。查询耗时主要由 total DRAM fetch time of successive nodes during tree descent 来决定。因此,Masstree 使用一个较大的 fanout 从而减少树的深度。同时 fetch 多个 nodes,从而 overlap fetch latencies。另外还会精心设计 cache line 以减少每个 node 需要的 data。
结构
几点挑战:
- Masstree must efficiently support many key distributions, including variable-length binary keys where many keys might have long common prefixes.
- for high performance and scalability, Masstree must allow fine-grained concurrent access, and its get operations must never dirty shared cache lines by writing shared data structures.
- Masstree’s layout must support prefetching and collocate important information on small numbers of cache lines.
其中 2 和 3 就是 Masstree 的 cache craftiness,即缓存友好性。
Masstree 是一个 trie 树,trie 树的每个节点是一个 B+ 树。trie 树的 fanout 是 2^64,也就是 8 个 bytes。通过 trie 的目的是利用 long key 的 shared prefix。通过 B+ 树 是支持 short key,以及 fine-grained concurrency。B+ 树的 fanout 是中等的,所以能有效利用内存。
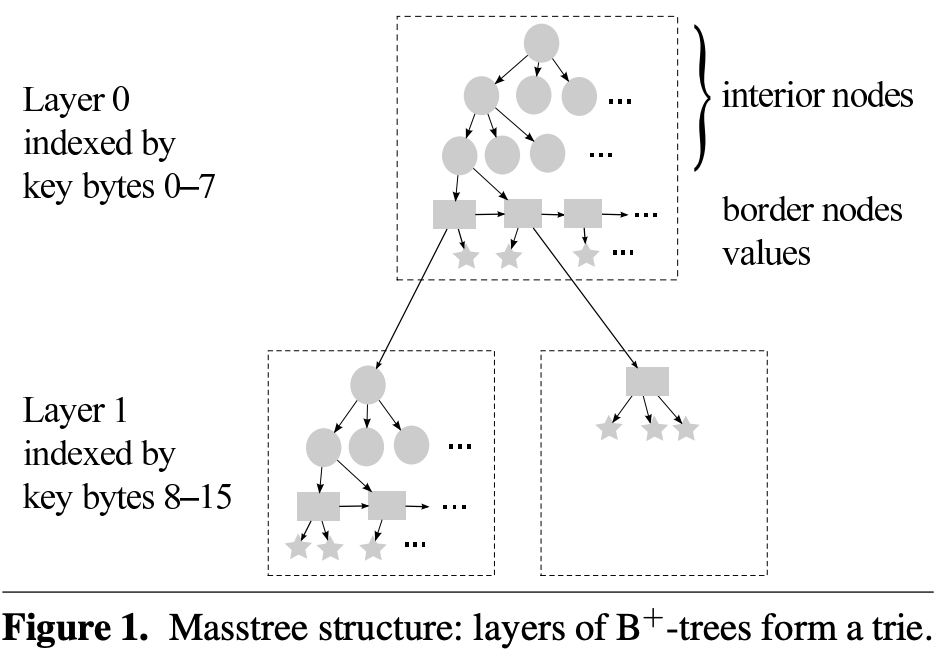
每个 B+ 树都会有至少一个 border node 也就是图中的矩形节点,以及 0 个或多个 interior node 也就是图中的圆形节点。border node 中按照传统的 B+ 树的方式组织 leaf nodes 也就是图中的五角星节点。可以看到 B+ 树的 border node 用来连接到下一层的 trie node,也就是一棵新的 B+ 树上。
Masstree 用一种比较 lazy 的方式去生成更深的层:
- Keys shorter than 8h+8 bytes are stored at layer ≤ h.
- Any keys stored in the same layer h tree have the same 8h-byte prefix.
- When two keys share a prefix, they are stored at least as deep as the shared prefix.
Masstree creates layers as needed (as is usual for tries). Key insertion prefers to use existing trees; new trees are created only when insertion would otherwise violate an invariant. 比如 “01234567AB” 会被存在 root layer 中,直到插入一个 “01234567XY” 之后会产生一个新的 layer。新的 layer 中会有一个 B+ 树,其中存放 AB 和 XY。
复杂度分析
- 查询复杂度和 B 树相同。对于 B 树,需要检查 O(log n) 个 nodes,进行 O(log n) 次比较。假设 key 的长度是 O(l),所以总的比较开销是 O(l logn)。Masstree 要在 O(l) 层中比较,每层比较的开销是 O(log n),所以总的代价也是 O(l logn)。但如果有公共前缀那么 Masstree 的代价就是 O(l + log n) 了。
- Masstree’s range queries have higher worst-case complexity than in a B+-tree, since they must traverse multiple layers of tree.
Layout
Figure 2 展示了节点的定义。这里面大量的 15 说明这里使用了 fanout 为 15 的 B+ 树。node *child[16] 中的 node 既可以是 border node,也可以是 interior node。
所有的 Border node 被链接,从而能够实现快速 remove 和 getrange 操作。keyslice 用 64 位 integer 数组表示字符串,相当于是 64 * ceil(n / 8) 代替 8*n,这能提高 13-19% 的效率。后面讲如何处理 ‘\0’。然后,A single tree can store at most 10 keys with the same slice, namely keys with lengths 0 through 8 plus either one key with length > 8 or a link to a deeper trie layer. 这个也好理解,因为如果有第二个 key 的话,比如上面的 01234567XY,就必须分裂了。我们保证所有 slice 相同的 key 会存在同一个 border node 中。这个设计简化了 interior node,它不必包含 key 的长度。也简化了并发操作的复杂度,带来的一点代价就是在节点分裂时需要做一些检查。
下面讲如何维护 border node 上的 suffix,这些 suffix 最多有 15 个。这里的做法是自适应地 inline 存,或者放在单独的内存块上面。目的是节省内存。总而言之这一块讲得是比较模糊的。
Masstree prefetches all of a tree node’s cache lines in parallel before using the node, so the entire node can be used after a single DRAM latency. Up to a point, this allows larger tree nodes to be fetched in the same amount of time as smaller ones; larger nodes have wider fanout and thus reduce tree height.
Nonconcurrent modification
Concurrency overview
主要包含细粒度的锁,以及 optimistic concurrency control。
细粒度的锁指的是 update 操作只需要 local lock。OCC 指的是读操作并不需要锁,也不会写全局的共享内存。这里应该指的是引用计数之类的东西,会导致 reader 竞争 read lock。
因为 reader 并不会 block 并发的 write 操作。所以可能会读到中间数据。因此,writer 在写之前会将一个 dirty 位标记。在写完之后,再自增 version。Reader 会在读取这节点前记录 version,并在读取后再次比较 version 和 dirty 位。
这里,根据更新的种类是 insert 还是 split,会更新 version 中的不同区域。version 的 layout 如下所示。

The biggest challenge in preserving correctness is concurrent splits and removes, which can shift responsibility for a key away from a subtree even as a reader traverses that subtree.
Writer–writer coordination
通过自旋锁来维护,这个锁在 version 里面的 locked 位上。
但是节点上的一些字段是被其他节点的锁来保护的,比如:
- parent 指针收到父节点的锁保护
- border node 的 prev指针受到左边 sibling 的保护
这能减少 split 操作的时候需要 acquire 的锁的数量。比如当某个中间节点 split 的时候它不需要子节点的锁,就可以替他们修改 parent 指针了。
但尽管如此,当节点 n 分裂的时候,还是需要: - n 自己的锁
a.目的是避免被并发修改。 - n 的新的 sibling 的锁
a. 从后面来看,这里指的就是获取新分裂出来的 n’ 的锁。n’ 的 prev 是 n。
b. 要不要获取分裂前的 prev 的锁,防止 prev 同时分裂? - n 的 parent 的锁
a. 防止父节点被其他线程分裂,从而让新分出来的节点 attach 错了 parent。
b. 从后文来看,更重要的原因是便于因为 parent 可能也满了,所以需要同时分裂 parent。
Writer–reader coordination
基本上就是对之前的 OCC 的一些展开的论述。
这里说了,universal 的 before-and-after version 检查能够让 reader 发现任何并发的 split,但也会影响性能。有一些性能优化措施,比如让某些操作比如 update,实际上可以避免更新 version。
Update
主要将通过对齐 version 的 alignment,让对它的写是原子的。
所以 update 操作不需要更新 version。
Update 操作时,writer 不能直接把旧的值删除掉,因为此时可能还有 reader 在读。这个是通过 RCU 来解决的。其实这里类似的方法还有 hazard pointer 等。
Border inserts
阅读本章前,可以回顾下 Figure2 的 keyslice 实现。
Border nodes 结构中的 permulation 字段是一个 uint64_t,其最低的 4 个 bit 组成 uint4_t 用来表示 key 的数量。因为 B+ 树的 fanout 是 15,所以正好。高 60 个 bit 组成了 uint4_t[15],用来索引每一个 key 的实际位置。
在插入时,会加载 permutation,并且重新组织 permutation 字段,匀出一个没有使用的 slot,存储正确的插入位置。
这个操作大部分时候需要一个 compiler fence,在一些机器上需要在写 kv 和写 permutation 中间加一个 memory fence。
New layers
在阅读本章前,可以先看下 Figure2 的 link_or_value 的实现。
插入 k1 到某个 border node,如果发现其中还有个冲突的 k2(这里冲突的含义看前面),那么就创建一个新的 border node 即 n'。将 k2 插入 n' 上的合适的 keyrange 上,并且将 k2 在 n 中的 value 替换成一个 pointer,这个 pointer 指向 next_layer 这一棵新的 B+ 树。然后,它可以解锁 n,并且继续插入 k1。此时 k1 会插入到新层的 n' 上。
这里的过程只涉及到一个 key,也就是 k1,所以并不需要更新 n 的 version 或者 permutation。我们回顾上文,会比较明白为什么之前这么设计了。
这个场景下需要注意的点是,reader 需要区分 value 和 pointer。因为 pointer 和 layermarker 是分别存放的。首先 writer 要把 key 标记为 UNSTABLE 状态,然后 reader 检查到这个标记的时候就会 retry。然后 writer 会写入 layer pointer 指针,最后把 key 标记为 LAYER。
这里的 UNSTABLE 或者 LAYER 啥的,根据上文,是由 keylen 这个字段来区分的。
Splits
Split 相比非 Split 操作,需要将一些 key 移动到另一个 node 中。所以 get 操作很容易就会丢掉这些被转移了的 key。所以,writer 需要去更新 version 里面的 split 字段。
Split 操作用了 hand-over-hand locking。这个实际上就是同时持有 cur 和 next 的 lock。在 Masstree 里面就是较低层的节点被 lock,并且被 mark 为 splitting。然后依次再更高层上在做同样的工作。这里认为 root 是最高的层。
不妨考虑下面的场景,B 需要分裂出一个 B’ 新节点。其中虚线箭头表示要被迁移到 B’ 上的 pointer。
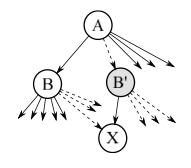
行为如下:
- B 和 B’ 都被标注为 splitting
- 包含 X 在内的孩子们被转移到 B’ 上
- 锁 A,并且标记为 inserting
- 将 B’ 插入到 A
- 将 A、B 和 B’ 都解锁,这里指掉那些 flag 状态。增加 A 的 vinsert,以及 B 和 B’ 的 vsplit
下面需要假设一个并发的 findborder(X) 操作,它尝试从 node A 开始寻找某个 key 所在的 border 节点。下面要证明这个操作要么会找到 X,要么就会重试。
首先,假设找到了 B’,那么它就可以找到已经被移动到 B’ 的 X,但这个时候 B’ 还没有被链接到 A 上,也就是说 B’ 还没有被 publish。
反过来,假设找到了 B。并且因为在 handle-over-hand validation 中,先加载 child 的 version,再double check parent 的 verison,所以我们在将 A 设置为 inserting 之前就已经记录下 B 的 version 了。我们还可以推断 B 的 version 是在 step1 之前被记录的,这是因为如果发现 B 在 splitting 状态,那么就会重试。这样的话就有两个可能:
1.如果在 step1 前,findborder 就完成了,那么就肯定能读到 X。
2.否则,B.version ⊕ v 这个操作就会失败,因为看到了 B的 splitting 状态。这个 splitting 状态需要到 step5 才会被清理,但这个时候 vsplit 又会变了。这里还需要注意,vsplit 和 splitting 都是在 verison 上的,所以这个更新无疑是原子的。

reader 处理 split 和 insert 的方式是不同的。insert 会在当前节点 retry,而 split 需要从 root 开始retry。
这里,因为 B 树的 fanout 是比较大的,并且这一块代码没什么锁,跑起来应该挺快,这也意味着并发的 split 实际上并不常见。在测试中,每 10^6 个请求中才有一个因为并发 split 从而需要从 root 开始 retry。相比之下,并发 insert 就会频繁很多,而它们也很容易在本地被处理,这也是为什么 masstree 将两个分开存储的原因。
get

Border node 因为彼此之间有 link,所以可以借助于 link 来处理 split。这里的规则是总是把右边部分分出去创建新 node。
Masstree 还有下面的规定:
1.B+ 树中的第一个 node 是 border node。他不会删除,除非整棵树都被删掉了。它始终是整棵树中最小的节点。
2.每个 border node 管理区间 [lowkey(n), highkey(n))。Split 或者 delete 操作可能修改右区间,但是不会修改左区间。
所以,get操作可以始终通过和下一个 border node 的 lowkey 比较来找到自己要找的 node。
Remove
首先回忆之前的 border insert,在里面并没有更新 vinsert。在这里的场景中我们会介绍和 remove 操作组合起来的时候,因为 remove 也不修改 version 所以可能出现错误。我理解这有点像像是 ABA 问题。
考虑下面的场景,get 操作和 remove 操作重叠了,所以 remove 操作不能 gc 掉 k1 和 v1,不然就影响了 reader。这里应该是对应了前面的 RCU?
相应的,remove 操作是修改 permutation。但如果后续有一个 put操作,刚好把 key 也放到了 i 上。这就会导致 get 返回 v2 了。所以当已经删除了的 slot 被重用的时候,也要更新 vinsert。

Ceph
对 Ceph 的简单介绍
Ceph 文件系统 CephFS 是一种基于 Ceph 分布式对象存储 RADOS 的 POSIX 兼容文件系统。它旨在为各种应用程序提供高性能、高可用性和可扩展的文件存储解决方案。
架构:
- RADOS(Reliable Autonomic Distributed Object Store):CephFS 构建在 Ceph 的分布式对象存储 RADOS 之上,RADOS 提供了可靠的数据存储和管理功能。
- 元数据服务器 MDS:CephFS 使用一个可扩展的元数据服务器集群来管理文件系统的元数据。这些元数据服务器负责协调客户端对文件系统的访问,并维护元数据的一致性。
- 客户端:CephFS 客户端可以直接与 RADOS 交互,进行文件数据的读写操作,无需通过中间网关或代理,从而提高了性能和可扩展性。
OSD 是 Ceph 的基本存储单元,全称为 Object Storage Daemon。每个 OSD 进程通常对应于存储集群中的一个物理或虚拟存储设备,如硬盘或 SSD。其功能如下:
- 存储:OSD 将数据以对象的形式存储在本地文件系统中,并通过网络提供访问。
- 复制:根据 Ceph 的配置(如副本数),OSD 负责将数据复制到多个节点上,以确保数据的冗余性和安全性。
- 恢复:在硬件故障或节点失效的情况下,OSD 可以自动检测并恢复数据,确保数据的完整性和可用性。
- 均衡:OSD 会与其他 OSD 协作,动态均衡集群中的数据存储负载。
MDS 并不是 Ceph 块存储和对象存储必须的组件。因为元数据也存在 OSD 中。这个组件对 Ceph 文件存储 CephFS 是必要的。
Placement Group 中包含多个 OSD。引入 PG 这一层其实是为了更好的分配和定位数据。
Ceph(CephFS)
Ceph: A Scalable, High-Performance Distributed File System (OSDI, 2006)
Introduction
目前有一些依赖对象存储的设计,其中对象存储设备,即 object storage device 也被称作 OSD,元数据服务器即 metadata server,也被称作 MDS。现在并不是读 block 了,而是读更大的 named objects,并且这些 object 的大小也未必要相同。底层的 block 分配由设备处理。Clients typically interact with a metadata server (MDS) to perform metadata operations (open, rename), while communicating directly with OSDs to perform file I/O (reads and writes), significantly improving overall scalability.
这样的架构依然不能解决 MDS 本身的扩展性,元数据没有做 partition。在设计上依旧依赖 allocation lists 和 inode tables,并且不愿意下推一些决策给 OSD。
Ceph 的设计基于的假设是 PB 级的存储实际上是动态的:
- 大的系统是基于增量构建出来的
- 节点 failure 是通常情况
- workload 的强度和特征总是在变化
Ceph 将 file allocation tables 替换称为 generating function,从而解耦数据和元数据,这个函数也就是后面的 CRUSH 函数。这样 Ceph 就能同时考虑 OSD 了,具体优化的场景包括:
- data access 的 distribution
- update serialization,这里指的应该是维护各个 update 操作之间的关系
- failure detection
- recovery
Ceph 用了一个分布式元数据集群来提高元数据访问的 scalability。
Overview
Ceph 对 scalability 的要求包括几个方面:
- 整个系统的 capacity 和 throughput
- 每个 client 的性能
- 每个目录和文件的性能
这里包括大量并发读写同一个文件,或者读写同一个目录。
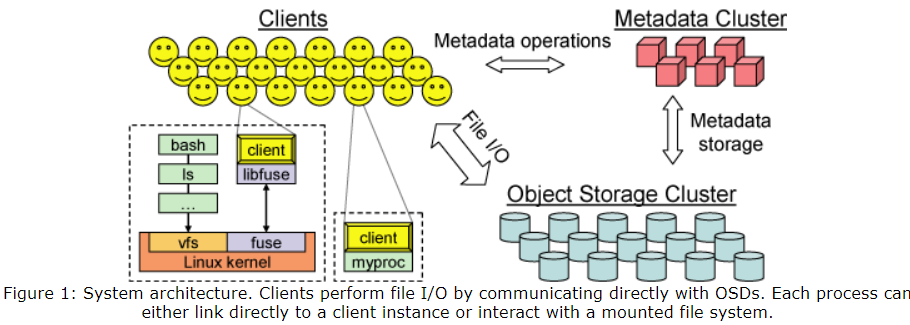
Decoupled Data and Metadata
元数据相关的工作包括 open、rename 等。
对象存储一直以来都是将底层 block 的分配权给各个设备处理的,并且它们也已经将 per-file block list 替换为更短的 object list。但是 Ceph 直接去掉了 allocation list。为了替代,文件中的数据被分成一系列固定命名规则(predictably named)的对象,并且通过一个 CRUSH 函数被映射到具体的设备中。这有个显然的好处,就是组成一个文件的所有对象的名字和位置可以被计算得到,而不需要从某个中心化的地方查询了。
Dynamic Distributed Metadata Management
Ceph utilizes a novel metadata cluster architecture based on Dynamic Subtree Partitioning.
这个算法可以将维护目录树的任务分发给很多个 MDS 来处理。我理解就是一种 partition 策略帮助减轻单个 MDS 节点的负担。
Reliable Autonomic Distributed Object Storage
OSD 来处理数据迁移、replication、failure detection 和 failure recovery。对于 MSD 来说,它们好像就是一个单节点的存储。
Client Operation
File IO and capabilities
当进程需要打开文件时,client 会发送一个请求给 MDS 服务器,后者遍历自己的目录层级,然后将文件名翻译成 inode。如果一切顺利,MDS 会返回诸如 inode 等信息。并且还会包含 striping strategy。
striping strategy 指的是文件是条带化存储的,一个文件可以对应到若干 object 上。
客户端的 capability 分为 read、cache read、write 和 buffer write。后续也会支持管控。
Ceph 的 striping strategy 中为了避免 file allocation metadata,object name 只包含 inode number 和 stripe number。然后就借助于 CRUSH 去将它们映射到 OSD 上。比如说,只要一个 client 知道 inode number、layout 和 file size,它就可以定位到文件对应的所有对象。
Client Synchronization
POSIX semantics sensibly require that:
- reads reflect any data previously written
- and that writes are atomic
这里我理解放到分布式系统里面就是要实现强一致性。
如果有读写或者写写冲突,那么 MDS 就会撤回之前发出的 read caching 和 write buffering 的 capacity,强制同步 IO。也就是说,所有应用的读和写都会被 block,直到被 OSD 确认。这样 update serialization 和 synchronization 的负担被转移给了 OSD。
当写请求跨越 object 的边界的时候,会向所有对象对应的 OSD 请求各自的锁,然后提交 write 并释放锁。Object locks are similarly used to mask latency for large writes by acquiring locks and flushing data asynchronously.
当然,同步 IO 对特别是小读写请求的影响比较大,因为每次都会请求一次 OSD。在一些情况下,可以选择更松的一致性要求。当然,性能和一致性是一组 tradeoff。
Ceph 支持一些 POSIX IO 的 HPC 接口,比如 O_LAZY flag,也就是放松了 coherency 要求。但是,HPC 程序自己会去控制一致性。这是因为一些应用可能只是让不同的线程写同一个文件的不同部分,这样就和一致性不冲突。
还有两个高级功能,lazyio_propagate 能够 flush 一个 range 到 object store 上。lazyio_synchronize will ensure that the effects of previous propagations are reflected in any subsequent reads.
Namespace Operations
Namespace Operations 诸如 readdir、unlink、chmod 之类的由 MDS 处理。
出于简化的目的,不会给 client 分发诸如 metadata lock 或者 lease 之类的东西。特别是对于 HPC 负载,callbacks offer minimal upside at a high potential cost in complexity.
Ceph 会对一些最常见的 metadata 访问场景进行优化,比如 readir 后面接一系列 stat 这个场景是 performance killer,Ceph 会选择在 readdir 的时候就直接取回来缓存。因为中间某个文件的属性可能变更了,访问缓存可能会牺牲一点 coherence,但性能提升很大。
对此的另一个优化手段是在 stat 被触发时,MDS 撤回所有的 write capacity,让所有的写暂停。然后获取所有的 writer 上的最新文件大小和 mtime,选择其中的最大的值返回。
当然,如果只有一个 writer,那么就可以直接从 writing client 取到正确的值,从而就不需要上面的过程了。
Applications for which coherent behavior is unnecesssary-victims of a POSIX interface that doesn’t align with their needs-can use statlite, which takes a bit mask specifying which inode fields are not required to be coherent. 这里不太看得懂。
Dynamically Distributed Metadata
Metadata operation 通常占据了近乎一半的文件系统开销,并且处在 critical path 上。
下面这段话值得是 metadata 的操作往往涉及的依赖更多,导致扩容方面存在更大的挑战。
Metadata management also presents a critical scaling challenge in distributed file systems: although capacity and aggregate I/O rates can scale almost arbitrarily with the addition of more storage devices, metadata operations involve a greater degree of interdependence that makes scalable consistency and coherence management more difficult.
Ceph 的上的 metadata 很小,基本只包含 file name 和 inode。对象名通过 inode 构建出来,并且通过 CRUSH 来分布到不同的 OSD 上。这简化了 metadata workload,并且让 Ceph 管理能力和文件的大小无关。
此外,Ceph 还要减少和 metadata 相关的 IO 次数。它使用了一个 two-tiered storage strategy,并且通过 Dynamic Subtree Partitioning 最大化 locality,并且提高 cache efficiency。
Metatada storage
MDS 使用 journal 来持久化。每个 journal 有几百兆,可以 absorb repetitive metadata updates。journer 被 lazy 和流式地地写入 OSD 集群。
下面这段话,这个设计有几点好处,但有点模糊。简单来说是:
- 流式地将更新写入磁盘,顺序写对读取友好
- Inode 直接嵌入在目录里面,这样一次 OSD 读就可以获取到整个目录的结构。充分利用了 directory locality
This strategy provides the best of both worlds: streaming updates to disk in an efficient (sequential) fashion, and a vastly reduced re-write workload, allowing the long-term on-disk storage layout to be optimized for future read access. In particular, inodes are embedded directly within directories, allowing the MDS to prefetch entire directories with a single OSD read request and exploit the high degree of directory locality present in most workloads [22].
细节:
- Each directory’s content is written to the OSD cluster using the same striping and distribution strategy as metadata journals and file data.
- Inode numbers are allocated in ranges to metadata servers and considered immutable in our prototype, although in the future they could be trivially reclaimed on file deletion.
- An auxiliary anchor table [28] keeps the rare inode with multiple hard links globally addressable by inode number-all without encumbering the overwhelmingly common case of singly-linked files with an enormous, sparsely populated and cumbersome inode table.
Dynamic Subtree Partitioning
做 delegate authority,SOTA 的方案包括:
- 静态子树切割
指的类似于 forcing an administrator to carve the dataset into smaller static “volumes” 这样的方案。 - 动态地基于 hash
哈希的方案会破坏元数据的 locality,也会破坏 prefetch 的可能性。
Ceph 的 Dynamic Subtree Partitioning 首先是引入了 hierachy。也就是 adaptively distributes cached metadata hierarchically across a set of nodes,如下图所示:
- 每个 MDS 通过 counters with an exponential time decay 去计算当前的 directory hierarchy 的元数据的 popularity
对某个 inode 的 counter 增加计数,会导致所有的祖先,直到树根的 counter 都增加。 - 这个 popularity 会向上往树根处传播,从而每个 MDS 可以计算得到一棵反映负载分布的权重树。
- MDS 可以通过迁移子树的方式来实现负载均衡。
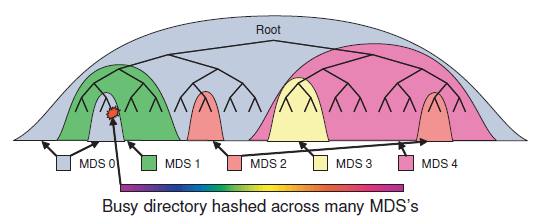
这个负载均衡可以只在内存中进行,从而减少对 coherence lock 或者 client capability 的影响。原理是:
- 共享的长期存储
- 精心设计的命名空间锁
Imported metadata is written to the new MDS’s journal for safety, while additional journal entries on both ends ensure that the transfer of authority is invulnerable to intervening failures (similar to a two-phase commit).
The resulting subtree-based partition is kept coarse to minimize prefix replication overhead and to preserve locality. 不太明白这里说的 prefix replication 是什么。
在 replication 的时候,inode 的内容被分为三块:security、file 和 immutable。security、file 两个组会被使用单独的 FSM 管理。其目的是减少 lock contention。这里也不太明白说的是什么。
Traffic control
尽管做了 partition,但是还是会存在 hotspot 或者 flash crowds(瞬时拥堵)的问题,比如很多个客户端同时访问同一个文件或者目录。Ceph 会根据 popularity 来决定是否将 hotspot 进行分散,同时也会想办法避免损失 locality:
1.读取压力比较大的目录会设有多个 replica 来分散负载。如果一个目录不 popular,那么它就不会被创建其他的 replica。
2.写入压力比较大的目录中的文件会被 hash 到不同的节点上。这会牺牲目录的 locality,但负载是均衡的。写入会直接被 direct 到 authority 节点上。
Distributed Object Storage
让 OSD 处理注入 replicate 之类的工作,让 Ceph 的 RADOS 取得在容量和聚合能力上的线性伸缩。
CRUSH(Controlled Replication Under Scalable Hashing)
如下图所示,一个文件会被分为多个 Object,通过 inode 和 ono 可以定位到某个对象的 oid。有了 oid 可以经过下面两步转换,得到存放的 OSD。
- Ceph 通过简单的 hash 函数将对象映射到不同的 PG 里面。
- 通过 CRUSH 函数将 PG 映射到 OSD。
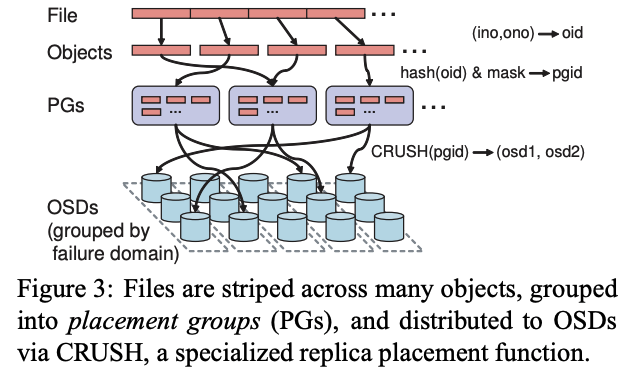
那么 CRUSH 函数定位一个 Object 所在的 OSD 就只需要知道:
- PG
- OSD cluster map
这个 map 实际上就是 OSD 节点的分布。
所以不会很频繁变化,或者变化也是只其中一小部分,比如上下线节点。
有关 OSD cluster map:
- OSD cluster map 是分层的描述,比如可以分为 shelf、rack cabinet(机柜)、row of cabinet(机柜列)。
- 每个 OSD 有个权重,表示自己能承受的数据的数量。
- CRUSH 会根据 placement rule 将 PG 映射到 OSD
Placement rule 定义了复制级别(level of replication)和放置的限制。例如:- 将 3 个 replica 都放到一个 row 中,从而避免 inter row 的流量。
- 但是在不同的 cabinet 中,从而实现容灾。
- OSD cluster map 还包含 down 或者 inactive 机器的列表,以及一个 epoch 号。
所有对 OSD 的请求都会带上 epoch 号。
OSD 之间会互相传播 epoch 以及对应的 OSD cluster map 从而实现相互的更新。 - 【Q】从后面的介绍可以看出,还有个专门的 Monitor 集群来维护 OSD cluster map。不是很清楚这里的关系。
Replication
Ceph 这里的假设:
对于 PB/EB 级别的系统,故障应该被认为是常态而不是意外。
Replication 的粒度是 PG。
写入流程:
- Client 会将写入发送个第一个没有 fail 的 OSD 中。
- 这个 OSD 会负责生成一个新版本,并进行复制。
- Primary 会确保所有的 replica 都被写完之后,再写入自己本地,然后回复 client。
读流程:
- 始终从 Primary 读。
Data safety
Ceph 认为共享存储的必要性在于两个方面:
- 同步,也就是让一个更新尽快对其他 client 可见
尽快在这里是很重要的,因为可能有多个客户端并发写,或者有并发读和并发写的存在,导致需要系统的写入比较快。 - 可靠性,也就是持久化。
在 ack update 的时候,Ceph 的 RADOS 解耦了 sync 和 safety。同时保证了快速的写入,以及持久性。
如下所示,和客户端的交互主要分为两个消息:
- ack 消息,表示 Primary 已经将 update 复制到了所有的 OSD 的 in-memory buffer cache 中
- commit 消息,表示所有 OSD 已经落完盘了
这个 commit 消息,可能需要等待几秒钟了。
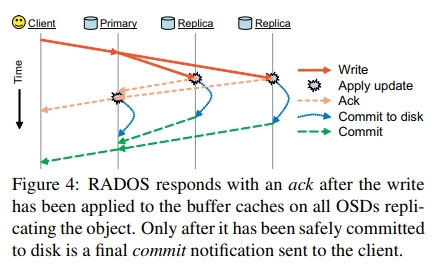
于此同时,在 commit 之前,client 本身也要 buffer 对应的 update,以避免所有的 OSD 都挂掉。When recovering in such cases, RADOS allows the replay of previously acknowledged (and thus ordered) updates for a fixed interval before new updates are accepted.
【Q】我觉得这种全部写入的方案,实际上简化了“选举”,因为如果关于一个 update 节点之间没有达成一致是不可能 ack 或者 commit 的。但是,如果一个 OSD 挂掉,那么可能导致写入无法被 commit,从而产生较大的内存开销。
故障检测
大部分情况下,replication 扮演了一个被动的 liveness 确认机制。当一个 OSD 无法收到最近 peer 的消息时,会发送一个专门的 ping。
RADOS 将 OSD liveness 分为两个维度:
- OSD 是否 reachable
对应了后面的 up/down - OSD 是否被 CRUSH assigned 了 data
对应了后面的 in/out
然后分为两个阶段:
- 短暂无响应的 OSD 会被标记为 down,此时会移交 primary 工作,比如 update serialization, replication 给这个 PG 对应的下一个 OSD。
- 长期无响应的 OSD 会被标记为 out,会派其他的 OSD 来接管。这个新的 OSD 会重新复制。
如下所示,Ceph 还是引入了一个 Monitor 集群来提供强一致的 OSD cluster map 的视图。
Because a wide variety of network anomalies may cause intermittent lapses in OSD connectivity, a small
cluster of monitors collects failure reports and filters out transient or systemic problems (like a network partition) centrally.
Monitors (which are only partially implemented) use elections, active peer monitoring, short-term leases, and two-phase commits to collectively provide consistent and available access to the cluster map.
这里作者又再一次说,OSD cluster map 的变化是在 OSD 之间传播的。
When the map is updated to reflect any failures or recoveries, affected OSDs are provided incremental map updates, which then spread throughout the cluster by piggybacking on existing inter-OSD communication.
下面的意思是,Monitor 更多的是作为一个仲裁的角色来解决不一致的问题。
Distributed detection allows fast detection without unduly burdening monitors, while resolving the occurrence of inconsistency with centralized arbitration.
这一章以下面这句话作为收尾。我理解就是 up/down 和 in/out 是两个维度的概念。一个节点挂掉了,或者被分区了,那么它就是 down 的节点。但是 down 掉的节点不一定就不可以恢复。如果我们发现节点 down 掉了,就立刻扩容,就会造成很多额外的 replication。
Most importantly, RADOS avoids initiating widespread data re-replication due to systemic problems by marking OSDs down but not out (e. g., after a power loss to half of all OSDs).
Recovery and Cluster Updates
为使恢复更快,OSD 为:
- 每个 Object 维护了版本号,这里叫 version
- 每个 PG 维护最近改动的 Object 的日志
类似于 Harp 的 replication logs
【Q】区别,epoch 用来标记 OSD cluster map 的版本,而 version 用来标记 PG 和 Object 的版本。
当一个 active OSD 收到一个更新过的 cluster map,它会遍历本地所有的 PG,计算 CRUSH mapping,确定每个 OSD 是该作为 primary OSD 还是 replica OSD。
如果一个 PG 的 OSD 成员列表变了,或者如果一个 OSD 刚启动,那这个 OSD 必须和 PG 的其他 OSD (也称为 peer)进行同步:
- 对于 replicated PG,它需要向 primary OSD 提供它自己当前的 PG 版本号
- 如果一个 OSD 是 PG 的 primary OSD,it collects current (and former) replicas’ PG versions.
下面这里说的是,如果一个 Primary 没有最近 PG 的状态,它就需要从之前的 OSD 中获取 PG change log,然后恢复。
If the primary lacks the most recent PG state, it retrieves the log of recent PG changes (or a complete
content summary, if needed) from current or prior OSDs in the PG in order to determine the correct (most recent)
PG contents.
然后,Primary 会视情况给所有的 replica 发送一个增量或者全量的更新。这个更新会覆盖。
The primary then sends each replica an incremental log update (or complete content summary, if
needed), such that all parties know what the PG contents should be, even if their locally stored object set may not
match.
只有当上面这个过程同步,才能恢复对这个 PG 中 object 的 IO。
Only after the primary determines the correct PG state and shares it with any replicas is I/O to objects in the PG permitted.
OSDs are then independently responsible for retrieving missing or outdated objects from their peers. If an OSD receives a request for a stale or missing object, it delays processing and moves that object to the front of the recovery queue.
下面是个例子。从这个例子可以更加发现 down 的节点在恢复后,是可以继续 Primary 的职责的:
- 假如 osd1 crash 了,然后被标记为了 down。osd2 会代替它成为 pgA 的 Primary。
- 如果 ods1 后面恢复了,它会在启动时请求最新的 map。然后 Monitor 会将它标记为 up。
- 当 osd2 收到了这个更新后,它会发现 osd2 不再是 Primary 了。他就会将 pgA 的 version number 发送给 osd1。
- osd1 会从 osd2 收到最近的 pgA 的日志,然后告诉 osd2 自己的内容是最新的了,and then begin processing requests while any updated objects are recovered in the background.

