本文主要介绍在设计需要序列化到磁盘上的数据结构时,需要考虑的点。
See also 《数据库中的压缩技术》。
设计要点
这里的要点,并不只局限在类似于 protobuf 的库上,而是在设计存储格式的时候,都会考虑的问题。
序列化和反序列化(serde)
- 兼容性
新旧版本应该能够处理彼此的数据。例如:- 旧版本能够忽略新增的字段,对于后续被删除的字段,也会保留其编号。
- 新版本对于旧消息中缺失的字段能补上默认值,或者填入 null。
- 类型的 cast
例如支持从 bool 升级为 enum 或者 int。 - 完整性校验
- 是否有足够的容错
- 是否多个文件或者多级文件?
- 是否分开存储 meta 和 data?先写 meta 还是先写 data?
- 是否可以自描述?
出于空间考虑,就不会包含,但这就会导致像 Parquet 一样的问题。因为解析库是由不同的语言和库来实现的,因此编码库会担心自己的编码用了新特性,从而导致别人解析不了。
所承载的数据类型和 workload
需要关注的:
- 对于 blob 的支持
解析是否需要占用大量内存? - 对于多模态数据的支持
例如对于向量的支持,是否便于做 ANN 等。 - 读取部分数据/Random Access 的需求
是否需要解压/解码全部结构,才能读取到该数据呢?
使用的 backend 存储
需要关注的:
- 对云原生场景的支持,例如是否适合放在 OSS 上面
对象存储的 TTFB(首字节响应时间)通常在几毫秒到几十毫秒之间(本地 SSD 仅为数十微秒)。因此,减少 IO 次数是关键。 - 磁盘 IO 的次数
这个关注点主要在底层的存储是内存、HDD、SDD 还是 OSS 上。
压缩和编码方式
See also 《数据库中的压缩技术》。
需要关注的:
- 压缩和解压缩的速度,以及 CPU 开销、内存开销
磁盘 IO 的单位并不一定要和解压缩的单位对应。完全可以- 从磁盘取一批数据到内存,以最大化利用磁盘带宽。
- 后面如何解压缩则纯粹是 CPU bound 的问题了。
- 如果预期只需要读一两条的数据,那么就希望有索引能够帮助我们快速 seek 到指定的位置,并解压足够小的 block。这样索引就会占据更大的空间,
- 如果预期需要读取所有数据,那么每次解压的单位就可以大很多,从而索引的大小就能做到更小。
- 编码和解码的速度,以及 CPU 开销、内存开销
这一点很重要,例如 json 的编解码性能就比较差。 - 压缩和编解码的平衡
Parquet 使用的 Snappy 等压缩算法会破坏 Page 的结构,造成严重的读放大。
因此更提倡的是像 Vortex 的 Adaptive 的编码。
常见格式
Parquet
假设一个表中有 N 列,它们被分入了 M 个 row groups 中。那么每个 row groups 中的一个 Column 称为一个 Column Chunk。
文件的 metadata 包含了每个 Column Chunk 的开始位置。为了能够一趟写完文件,所以最后才会写入 metadata。
1 | 4-byte magic number "PAR1" |
在读取时,首先需要读取 metadata,从而定位到所有要读取的 Column Chunks。这些 Column Chunk 稍后可以被顺序读取出来。
Parquet 的格式的设计思想是将 metadata 和 data 分开,这使得可以将 Column 们分入到不同的文件中。于此同时,有一个单独的 metadata 文件去索引多个 parquet 文件。
从下面的图片中可以看到,Parquet 文件实际上是自包含的,也就是说单个 Parquet 文件已经包含完整的数据和元数据,无需依赖外部元数据文件。像 Spark 之类的系统确实会创建一个全局的 metadata 文件,但它的作用就是方便快速的索引。
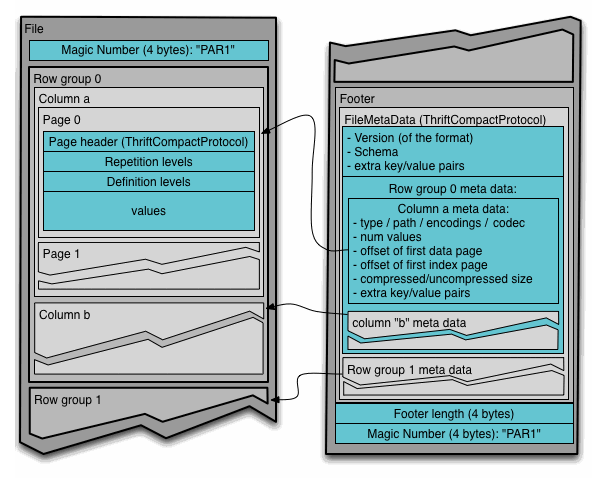
因为 metadata 在 parquet 文件的 Footer 处,所以需要先读取文件的倒数第 5 到 8 字节,得到它的大小,然后再往前 seek 这个大小解析出 metadata 部分。
Parquet 是使用 Thrift 协议解析序列化的。它和 protobuf 其实差不多,不过 Thrift 自带了 RPC。
Types
Parquet 会在 Column Chunk 层面保存 min max 值。
Nested Encoding
关于 Dremel 格式,可以看 https://paper-notes.zhjwpku.com/datalayout/dremel.html。后面章节也专门有介绍
To encode nested columns, Parquet uses the Dremel encoding with definition and repetition levels. Definition levels specify how many optional fields in the path for the column are defined. Repetition levels specify at what repeated field in the path has the value repeated. The max definition and repetition levels can be computed from the schema (i.e. how much nesting there is). This defines the maximum number of bits required to store the levels (levels are defined for all values in the column).
Two encodings for the levels are supported BIT_PACKED and RLE. Only RLE is now used as it supersedes BIT_PACKED.
Column chunks
错误恢复
如果文件的 metadata 丢失了,那么文件损坏。如果 Column 的 metadata 丢失了,那么这个 Column Chunk 就损坏了。但是这个 Column 在其他 row group 中的部分是 OK 的。如果 page header 丢失了,那 chunk 中剩余的 page 就丢失了。如果 page 中的 data 损坏了,那么这个 page 就丢失了。
因此,如果 row group 设置的比较小,那么文件可能在 resilient 上更好。但是,这会 file metadata 更大。如果在写入 metadata 的时候出现问题,那么所有写入的数据都丢失了。一个做法是每写 N 个 row group,就写一次 metadata。每个 metadata 都是 cumulative 的,并且包含了写到现在所有的 row group。
Combining this with the strategy used for rc or avro files using sync markers, a reader could recover partially written files.
Parquet 的缺点以及可能的优化
对向量等多模态数据支持不好
实际上是被表示成Array<Float>,最终按照 Dremel 的形式存储。
Dremel 那一套虽然很优美,但是 decode 开销巨大。
进一步,这种形式的问题:- 对向量检索完全不友好。
- 对稀疏向量的支持也不好。稀疏向量一般采用 (index, value) 这样的方式,或者 CSC / CSR 这样的存储。
点查性能不好
Parquet 的假设是少量列+许多行。不适合高频随机写/更新
需要解压缩
一般是找到 page -> snappy 解压 -> decode -> 定位。
非常消耗 CPU。并且这些算法也导致随机访问性能差,对应到点查性能不好。
这么激进的压缩策略,是因为在 HDD 年代的带宽低,所以需要更极限的压缩。Footer 在尾部,对 object store 不够友好
尽管可以通过 Range HTTP Request 异步读取尾部固定大小的字节,但 Parquet 的 Footer 长度是可变的,所以首先需要获得一个 footer length。
所以,通过 OSS 读取可能要1
2
3先 GET footer length
再 GET footer 中的 metadata
再 GET data小 IO 太多了。以一次点查为例,Parquet 的读 IO 分别是:
- 读取 footer,解析各种元数据,比如 schema,以及各个 row group。
- 在每个 row group 中,读取对应列的 column metadata。对于大宽表,比如有 100 列,那么就要加载 100 次不同的 column chunk offset,开销很大。
- 但其中有多个 page,所以要挨个找到对应的 page,形成多次 IO。
在之前的版本中,统计数据(min、max)只在 column 的 metadata 和 page header 当中,当读取 page 的时候,可以根据 page header 中的统计数据决定是否需要跳过这一页,但这样还是需要遍历文件中的每一页。
但是在 https://github.com/apache/parquet-format/blob/master/PageIndex.md 中,支持在 RowGroup 层面,用 ColumnIndex 通过列值定位到 page。然后 OffsetIndex 可以根据 page 的编号,找到在文件中的实际偏移。
当然,这个优化下,仍然没有 key index,也仍然需要整个 page 都解压并且 decode。
Encoding 算法,并不是 adaptive 的
比如有的列,可能一部分适合 dict,一部分适合 FSST 这样。
这能看出 Parquet 在存储设计上的一些问题:
- Row Group 太粗了,读放大大,随机访问性能拉胯
仅仅为了读一行一列,都需要执行度 footer -> 读 row group meta -> 定位 column chunk -> 解压 page -> decode -> scan 找到这一行一列。 - Page 中并不能实现随机读取
例如有共享的字典或者其他 encoding。
Vortex
- Adaptive Encoding
不同的 chunk、segment 甚至不同的区域都可以选择不同的 encoding 方式。
encoding 是 composable 的,比如可以做 delta + bitpacking。
这里的一点 tradeoff 是宁愿损失一点压缩率,也要换取 execution efficiency。所以,诸如全局字典这种 Parquet 比较喜欢的手段,在 Vortex 中就被 tradeoff 掉了。当然,全局字典还有个问题是没法做 pruning 了。因为如果每个 Page 有自己的字典,那么直接读取这个字典就能知道某个值是否存在了。 - Random Access:Page 可以独立 decode
- Arrow-native
- 更细粒度的统计信息
对WHERE ts BETWEEN ...这样的查询更友好。 - 更适合对象存储
- metadata 更局部
- block 更独立
- seek 更少
- RTT 更少
- 更适合向量/稀疏数据
Avro
Arrow
Lance
LevelDB/RocksDB 的 WAL
Dremel
如下图所示,dremel 可以将 nesting 的格式,例如 protobuf 或者 json 拍平成适合列式存储的格式。那么多个 doc 就会被转换成一定数量的列。如下图所示,2 个 doc 被用 6 个列存储。我们不需要记录“内部节点”,只需要记录“叶子节点”就行。
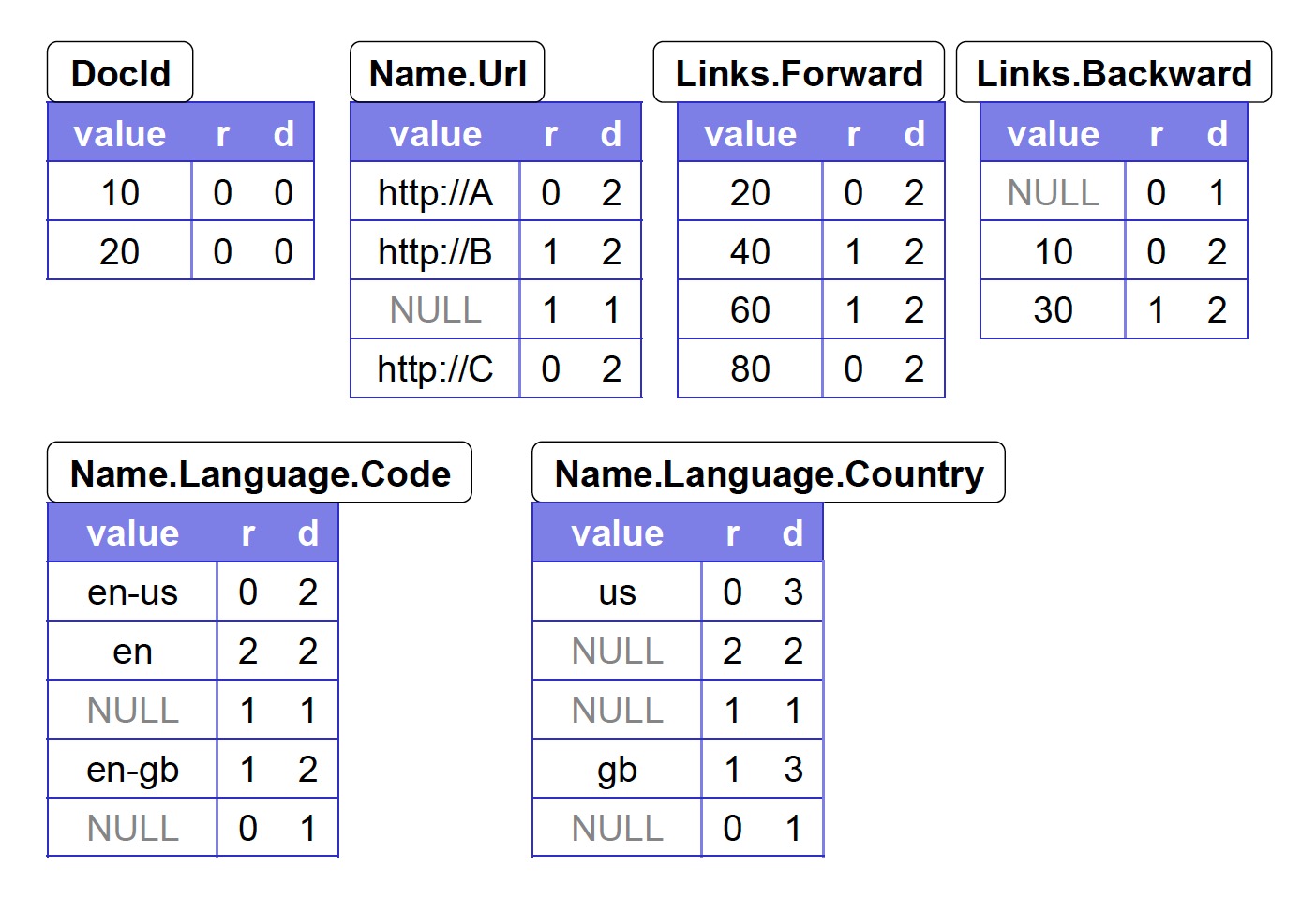
容易看到,每个列的长度是不一样的。这是因为 nesting 格式主要的复杂点是存在 option 和 repeated 的情况。
如果没有上述的情况,就可以理解为一个只包含基础类型的 struct。那么:
- 如上图所示,每个 fullpath 作为一列。对于每个 doc,按照 fullpath 拍平,将值对应存储到各列就行。这个过程称为 strip。
- 读取的时候,可以直接按照顺序从各个列中还原成原来的文档,不同列相同的 offset 肯定属于同一个文档。
- 所有列的长度是一样的。
但是如果有了 option 和 repeated,就不是这样了。
解决方案是引入两个计数:
Repetiton Level
表示这个值在 full path 的哪一级进行重复。如果为 0,说明这是一个新的 doc。
在下面的例子中,考虑Name.Language这个列的 Repetiton Level 值:如果为 R = 1,就表示在当前这个 doc 中,还有一个 Name 字段。对应如下的情况:
1
2
3
4
5Doc 1
Name 1
Language 1
Name 2
Language 2 <====== 属于 Name 2如果为 R = 2,就表示在当前这个 doc 中,当前这个 Name 字段中,还有一个 Language 字段。对应如下的情况:
1
2
3
4Doc 1
Name 1
Language 1
Language 2 <====== 属于 Name 1
容易看出,如果没有 Repetition Level,我们无法分清上面两种情况。
Definition Level
用来解决 option 字段的问题。只有 option 和 repeated 字段才需要 definition level,required 的字段不需要。
如果没有 Definition Level 会怎么样呢?考虑下面的 Schema1
2
3
4
5message M {
repeated group A {
optional int32 B;
}
}然后在列存中是
1
2
3
4B = 1
B = NULL
B = NULL
B = 2那么它对应的真实数据可能是
1
2
3
4
5
6
7
8
9Doc 1
A
B 1
B NULL
Doc 2
A NULL
Doc 3
A
B 2这种情况对应的 Repetiton Level 是
[0, 1, 0, 0]。但是,它有可能是1
2
3
4
5
6
7
8
9
10Doc 1
A
B 1
B NULL
Doc 2
A
B NULL
Doc 3
A
B 2也就是我们无法分辨 Doc 2 中究竟是:
- A 是空列表
- A 不是空列表,但是它的唯一元素中的 B 为 NULL
下图中是一个概括性的示例:
- required 字段的 R level 和 D level 和父亲一样
- option 字段的 R level 不变,D level 递增
- repeated 字段的 R level 和 D level 都递增
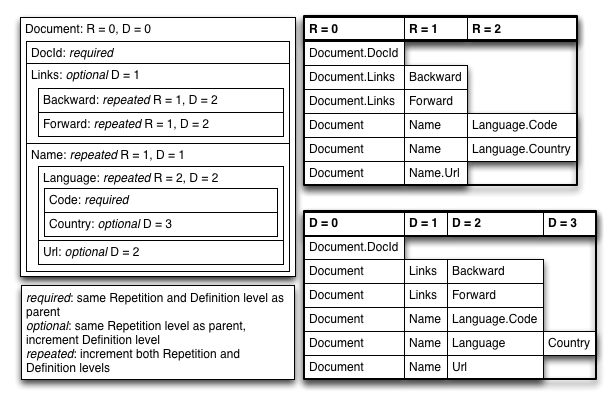
下面是个 demo,几个关键点:
Links.Backward: NULL, R:0, D:1
如果一个 repeated 或者 optional 字段为空,需要写一个 NULL。
这里 D 为 1 是因为 Links 是有值的,它的 level 是 1。Name.Language.Code: en-us, R:0, D:2
尽管在同一个 doc 里面,但这里 R 是 0 而不是 1,因为这里的 Name 没有重复。
其实这也很好理解,因为Links.*和Name.*是两个列了,所以不能因为觉得这里的 Name 和上面的 Links 同属一个文档,这个文档就是重复的。
这里 D 为 2 是因为 Name 和 Language 都是 repeated 字段,所以都自增 1,但是 Code 是 required 的字段,就不需要自增,结果为 2。Name.Language.Country: us, R:0, D:3
和上面唯一的区别就是 Country 为 optional,所以 D 还要自增 1,所以为 3。
| Schema | Document | Dremel format |
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
}
|
DocId: 10
Links
Forward: 20
Forward: 40
Forward: 60
Name
Language
Code: 'en-us'
Country: 'us'
Language
Code: 'en'
Url: 'http://A'
Name
Url: 'http://B'
Name
Language
Code: 'en-gb'
Country: 'gb'
|
R = 0 (current repetition level)
DocId: 10, R:0, D:0
Links.Backward: NULL, R:0, D:1 (no value defined so D < 2)
Links.Forward: 20, R:0, D:2
R = 1 (we are repeating 'Links.Forward' of level 1)
Links.Forward: 40, R:1, D:2
R = 1 (we are repeating 'Links.Forward' again of level 1)
Links.Forward: 60, R:1, D:2
Back to the root level: R=0
Name.Language.Code: en-us, R:0, D:2
Name.Language.Country: us, R:0, D:3
R = 2 (we are repeating 'Name.Language' of level 2)
Name.Language.Code: en, R:2, D:2
Name.Language.Country: NULL, R:2, D:2 (no value defined so D < 3)
Name.Url: http://A, R:0, D:2
R = 1 (we are repeating 'Name' of level 1)
Name.Language.Code: NULL, R:1, D:1 (Only Name is defined so D = 1)
Name.Language.Country: NULL, R:1, D:1
Name.Url: http://B, R:1, D:2
R = 1 (we are repeating 'Name' again of level 1)
Name.Language.Code: en-gb, R:1, D:2
Name.Language.Country: gb, R:1, D:3
Name.Url: NULL, R:1, D:1
|
Table Format
Hive
Iceberg
Iceberg 解决的问题是如何把对象存储上的一堆 Parquet 文件,组织成一个像数据库表一样可管理、可事务化、可演进的数据集。但是它本身并不是数据集,

