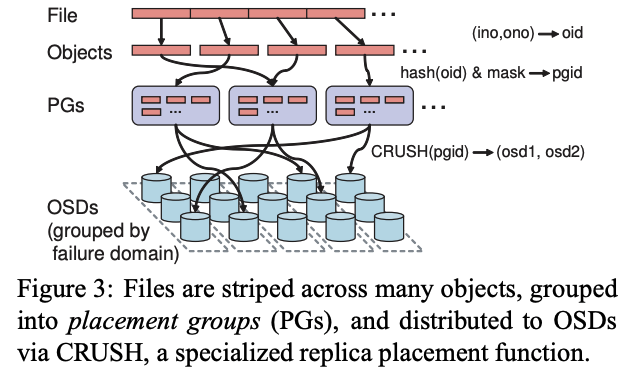
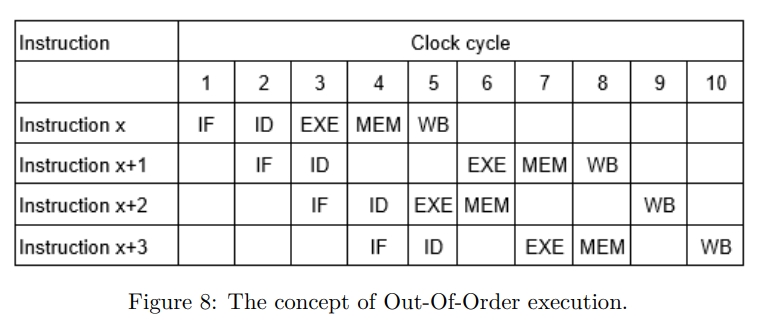
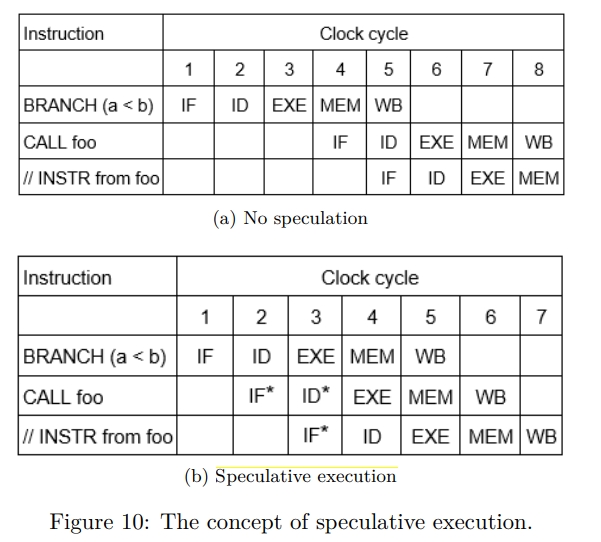
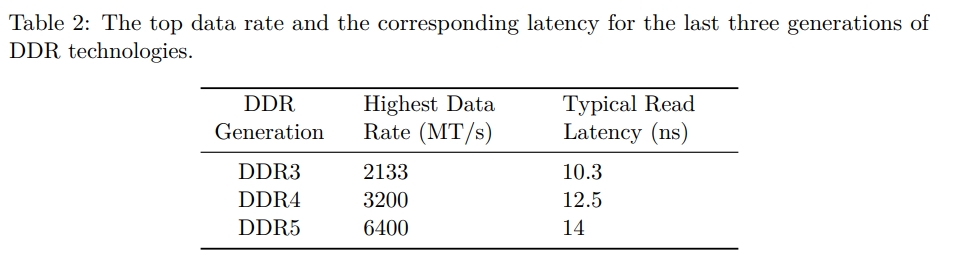
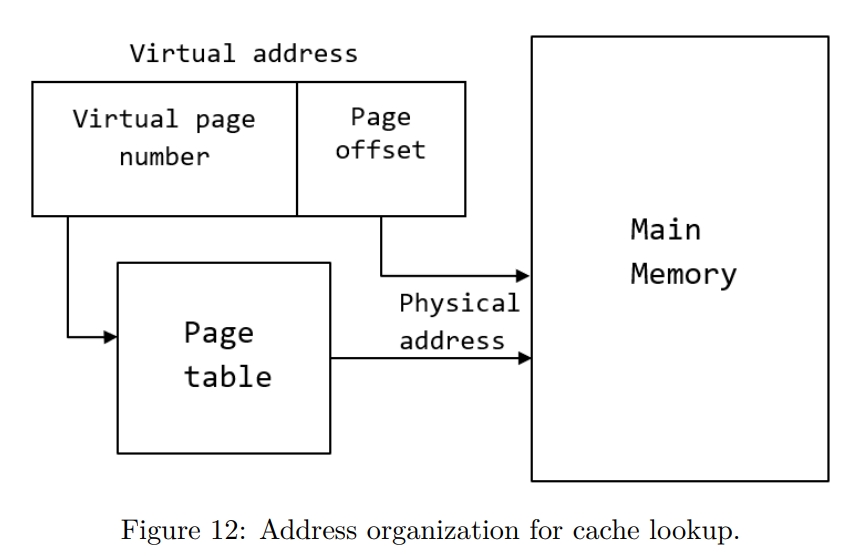
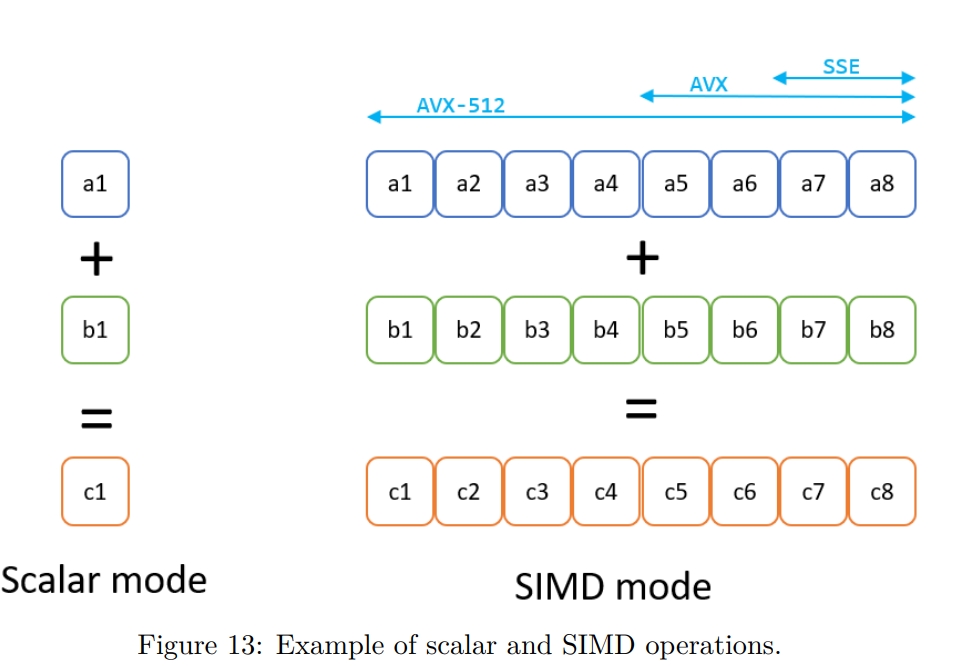
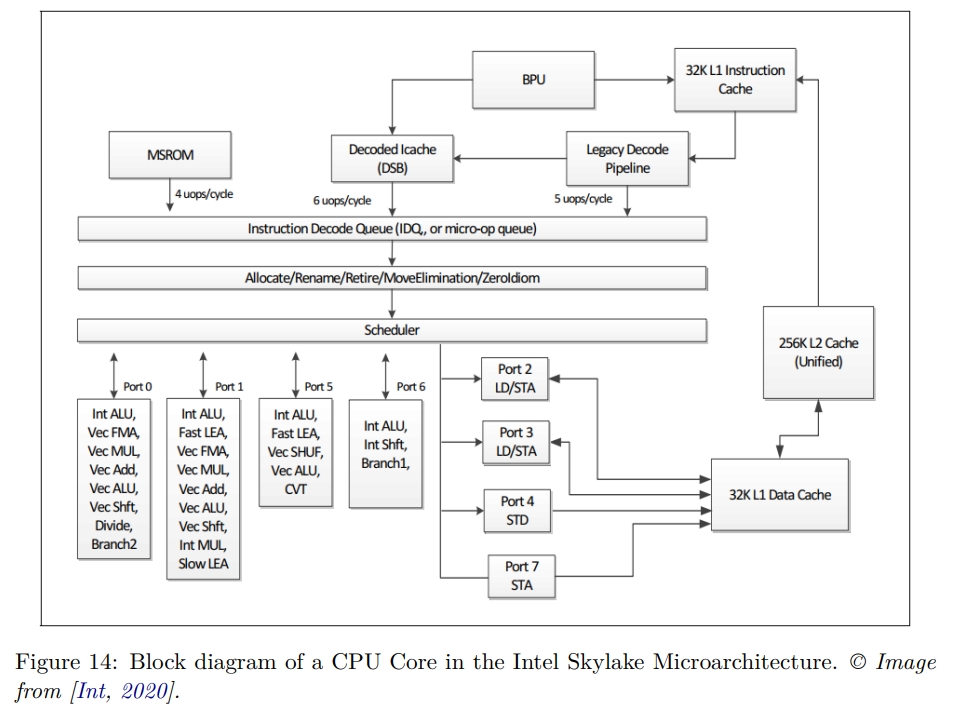
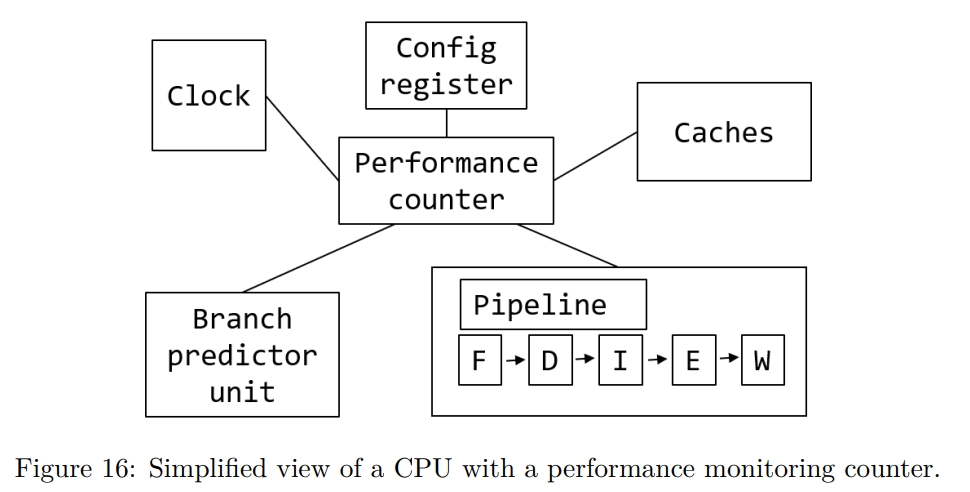
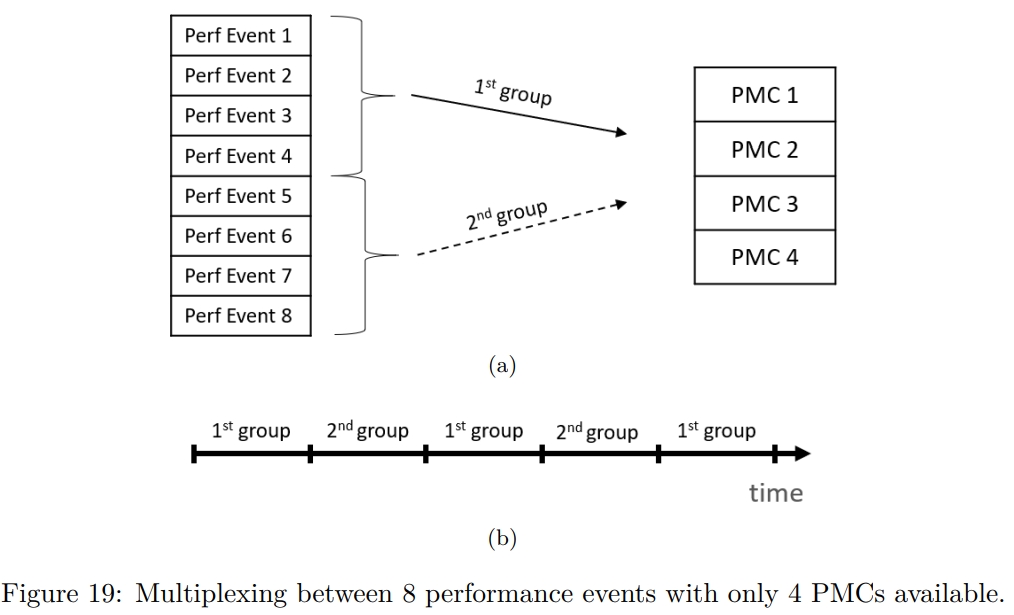
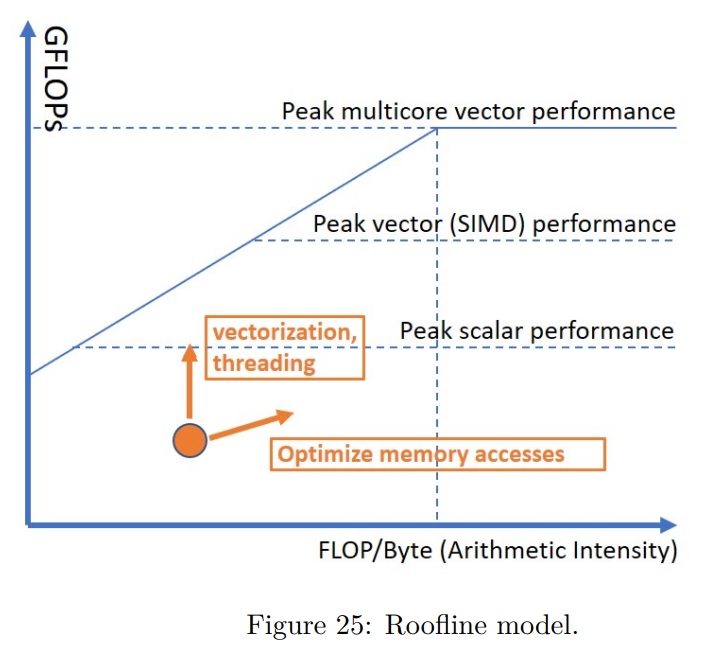
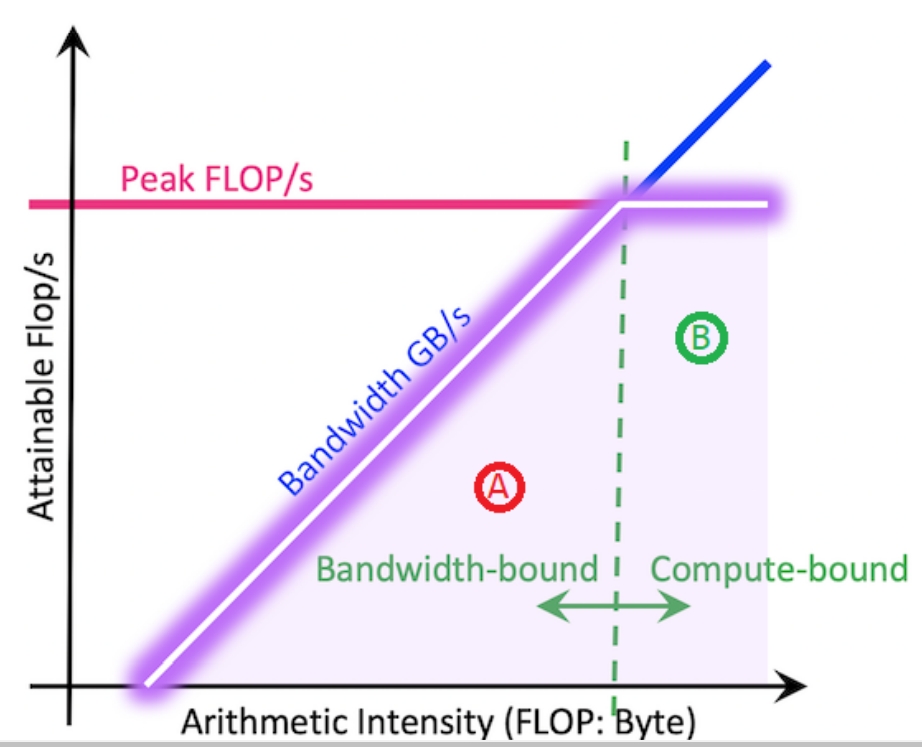
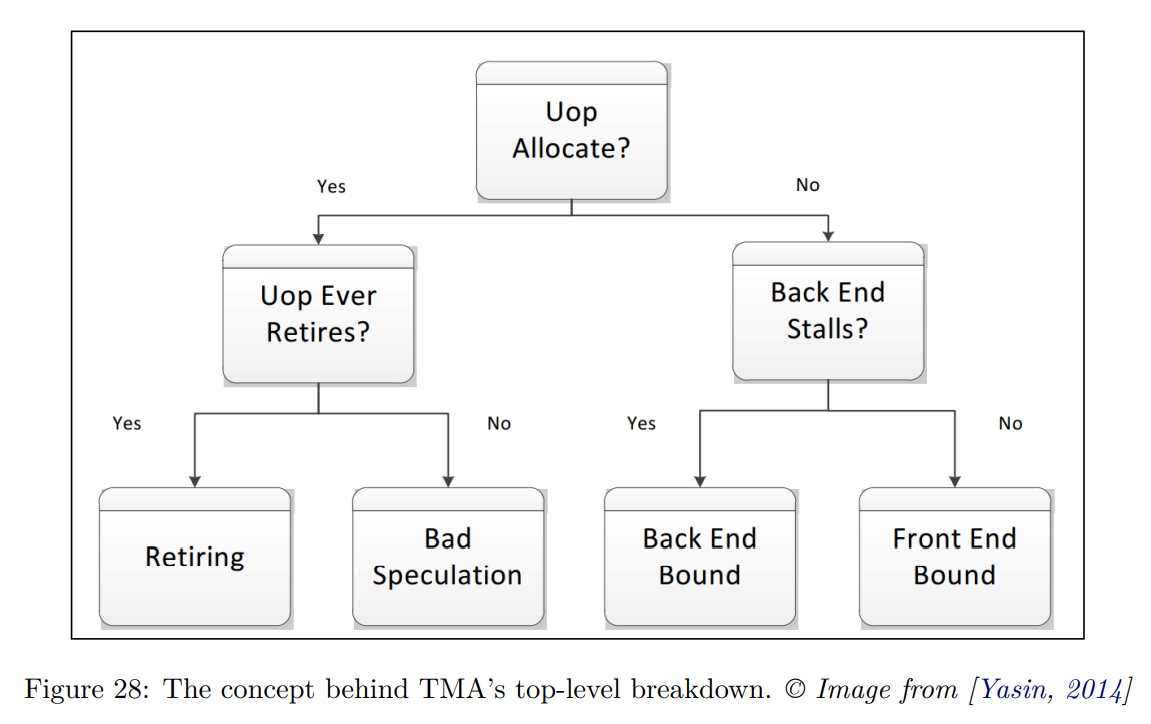
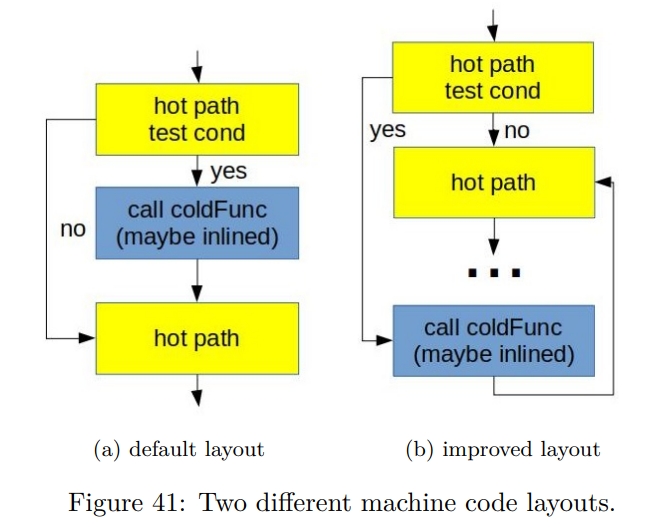
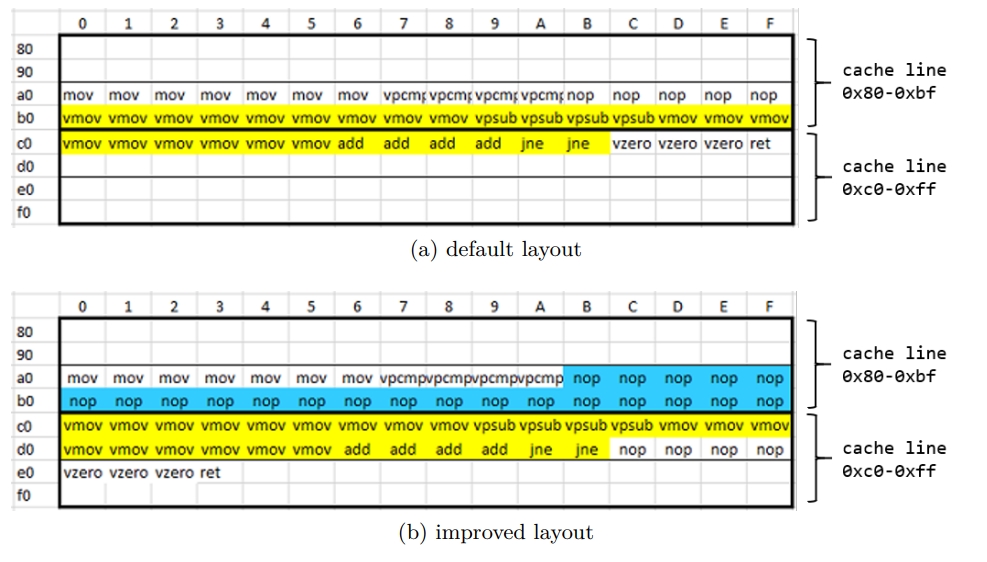
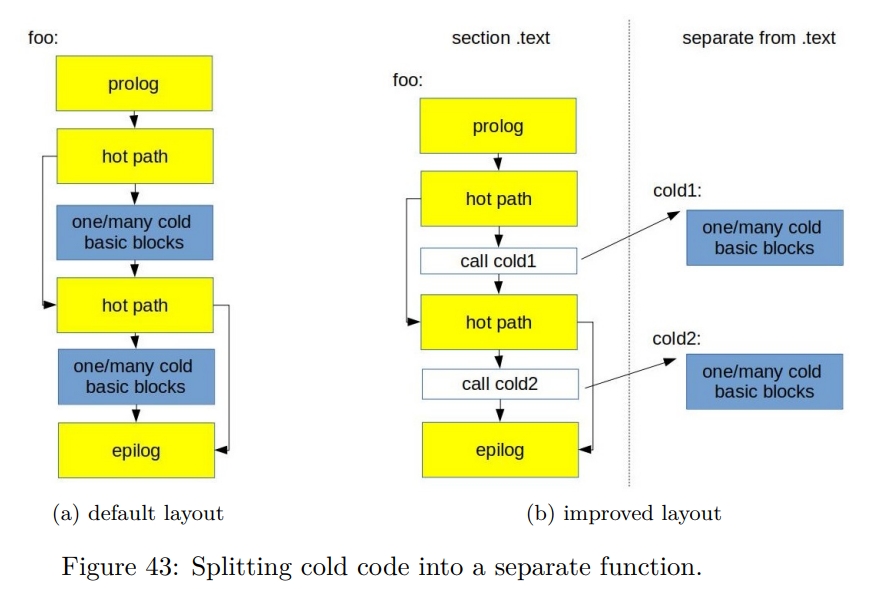
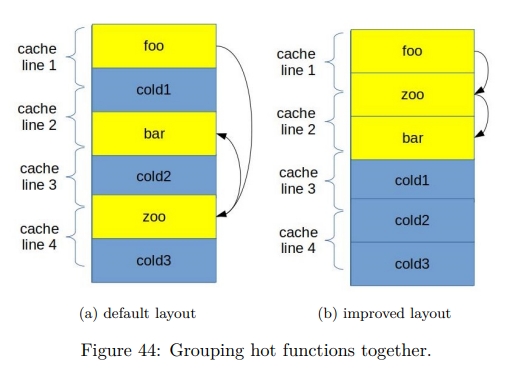
While rereading Harry Potter, I found these passages are inspiring and interesting.HP1
“No, thanks,” said Harry. “The poor toilet’s never had anything as horrible as your head down it — it might be sick.” Then he ran, before Dudley could work out what he’d said.
But from that moment on, Hermione Granger became their friend. There are some things you can’t share without ending up liking each other, and knocking out a twelve-foot mountain troll is one of them.
It does not do to dwell on dreams and forget to live, remember that.
Everyone fell over laughing except Hermione, who leapt up and performed the countercurse. Neville’s legs sprang apart and he got to his feet, trembling.
“Call him Voldemort, Harry. Always use the proper name for things. Fear of a name increases fear of the thing itself.”
“There are all kinds of courage,” said Dumbledore, smiling. “It takes a great deal of bravery to stand up to our enemies, but just as much to stand up to our friends. I therefore award ten points to Mr. Neville Longbottom.”
HP2
“Did you really?” said Mr. Weasley eagerly. “Did it go all right? I — I mean,” he faltered as sparks flew from Mrs. Weasley’s eyes, “that — that was very wrong, boys — very wrong indeed. . . .”
“Rubbish,” said Hermione. “You’ve read his books — look at all those amazing things he’s done —“
“He says he’s done,” Ron muttered.
“I never thought I’d see the day when you’d be persuading us to break rules,” said Ron. “All right, we’ll do it. But not toenails, okay?”
“See here, Malfoy, if Dumbledore can’t stop them,” said Fudge, whose upper lip was sweating now, “I mean to say, who can?”
help will always be given at Hogwarts to those who ask for it.
“However,” said Dumbledore, speaking very slowly and clearly so that none of them could miss a word, “you will find that I will only truly have left this school when none here are loyal to me. You will also find that help will always be given at Hogwarts to those who ask for it.”
Ahaha
“But one of us seems to be keeping mightily quiet about his part
in this dangerous adventure,” Dumbledore added. “Why so modest, Gilderoy?”
“He tried to do a Memory Charm and the wand backfired,” Ron explained quietly to Dumbledore.
“Dear me,” said Dumbledore, shaking his head, his long silver mustache quivering. “Impaled upon your own sword, Gilderoy!”
“Voldemort put a bit of himself in me?” Harry said, thunderstruck.
“because I asked not to go in Slytherin.” What really matters is one’s choice.
“It only put me in Gryffindor,” said Harry in a defeated voice,
“because I asked not to go in Slytherin. . . .”
“Exactly,” said Dumbledore, beaming once more. “Which makes you very different from Tom Riddle. It is our choices, Harry, that show what we truly are, far more than our abilities.” Harry sat motionless in his chair, stunned. “If you want proof, Harry, that you belong in Gryffindor, I suggest you look more closely at this.”
Dumbledore reached across to Professor McGonagall’s desk, picked up the blood-stained silver sword, and handed it to Harry. Dully, Harry turned it over, the rubies blazing in the firelight. And then he saw the name engraved just below the hilt.
Godric Gryffindor.
“Only a true Gryffindor could have pulled that out of the hat, Harry,” said Dumbledore simply.
“Dobby is free”
“Master has given a sock,” said the elf in wonderment. “Master gave it to Dobby.”
“What’s that?” spat Mr. Malfoy. “What did you say?”
“Got a sock,” said Dobby in disbelief. “Master threw it, and Dobby caught it, and Dobby — Dobby is free.”
And the day came eventually…
“Least I could do, Dobby,” said Harry, grinning. “Just promise never to try and save my life again.”
HP3
Very accurate prophecy
“I dare not, Headmaster! If I join the table, we shall be thirteen! Nothing could be more unlucky! Never forget that when thirteen dine together, the first to rise will be the first to die!”
Very accurate prophecy too
“If you must know, Minerva, I have seen that poor Professor Lupin will not be with us for very long. He seems aware, himself, that his time is short. He positively fled when I offered to crystal gaze for him —“
This scene is a wonderful scene in the movie
“Have you ever seen anything quite as pathetic?” said Malfoy.
“And he’s supposed to be our teacher!”
Harry and Ron both made furious moves toward Malfoy, but Hermione got there first — SMACK!
She had slapped Malfoy across the face with all the strength she could muster. Malfoy staggered. Harry, Ron, Crabbe, and Goyle stood flabbergasted as Hermione raised her hand again.
“YOU CHEATING SCUM!” Lee Jordan was howling into the megaphone, dancing out of Professor McGonagall’s reach. “YOU FILTHY, CHEATING B —“
In Chinese version, it is fist rather than finger. But finger here is more vivid.
Professor McGonagall didn”t even bother to tell him off. She was actually shaking her finger in Malfoy’s direction, her hat had fallen off, and she too was shouting furiously.
“I must admit, Peter, I have difficulty in understanding why an innocent man would want to spend twelve years as a rat,” said Lupin evenly.
“If you made a better rat than a human, it’s not much to boast about, Peter,” said Black harshly.
“You don’t understand!” whined Pettigrew. “He would have killed me, Sirius!”
“THEN YOU SHOULD HAVE DIED!” roared Black. “DIED RATHER THAN BETRAY YOUR FRIENDS, AS WE WOULD HAVE DONE FOR YOU!”
Black and Lupin stood shoulder to shoulder, wands raised.
“You should have realized,” said Lupin quietly, “if Voldemort didn’t kill you, we would. Good-bye, Peter.”
“I’m not doing this for you. I’m doing it because — I don’t reckon my dad would’ve wanted them to become killers — just for you.”
You know, Minister, I disagree with Dumbledore on many counts . . . but you cannot deny he’s got style. . . .
“What we need,” said Dumbledore slowly, and his light blue eyes moved from Harry to Hermione, “is more time.”
“But —“ Hermione began. And then her eyes became very round. “OH!”
“Now, pay attention,” said Dumbledore, speaking very low, and very clearly. “Sirius is locked in Professor Flitwick’s office on the seventh floor. Thirteenth window from the right of the West Tower. If all goes well, you will be able to save more than one innocent life tonight. But remember this, both of you: you must not be seen. Miss Granger, you know the law — you know what is at stake. . . . You — must — not — be — seen.”
“Dumbledore just said — just said we could save more than one innocent life. . . .” And then it hit him. “Hermione, we’re going to save Buckbeak!”
He knew it!
Harry tugged harder on the rope around Buckbeak’s neck. The hippogriff began to walk, rustling its wings irritably. They were still ten feet away from the forest, in plain view of Hagrid’s back door.
“One moment, please, Macnair,” came Dumbledore’s voice.
“You need to sign too.” The footsteps stopped. Harry heaved on the rope. Buckbeak snapped his beak and walked a little faster.
You can always rely on yourself
And then it hit him — he understood. He hadn’t seen his father — he had seen himself — Harry flung himself out from behind the bush and pulled out his wand.
“EXPECTO PATRONUM!” he yelled.
It made all the difference in the world
“It didn’t make any difference,” said Harry bitterly. “Pettigrew got away.”
“Didn’t make any difference?” said Dumbledore quietly. “It made all the difference in the world, Harry. You helped uncover the truth. You saved an innocent man from a terrible fate.”
We all know in HP7, Pettigrew gave his life to save Harry.
This is magic at its deepest, its most impenetrable, Harry. But trust me … the time may come when you will be very glad you saved Pettigrew’s life.
“You think the dead we loved ever truly leave us? You think that
we don”t recall them more clearly than ever in times of great trouble? Your father is alive in you, Harry, and shows himself most plainly when you have need of him. How else could you produce that particular Patronus? Prongs rode again last night.”
It took a moment for Harry to realize what Dumbledore had said.
HP4
The bar that leads to diag alley is called leaking cauldron
“We’re not thundering,” said Ron irritably. “We’re walking. Sorry if we’ve disturbed the top-secret workings of the Ministry of Magic.”
“What are you working on?” said Harry.
“A report for the Department of International Magical Cooperation,” said Percy smugly. “We’re trying to standardize cauldron thickness. Some of these foreign imports are just a shade too thin — leakages have been increasing at a rate of almost three percent a year —“
“That’ll change the world, that report will,” said Ron. “Front page of the Daily Prophet, I expect, cauldron leaks.”
Crouch can’t even spell Percy’s name correctly.
“Ludo, we need to meet the Bulgarians, you know,” said Mr. Crouch sharply, cutting Bagman’s remarks short. “Thank you for the tea, Weatherby.”
It was the only time the brothers have seem what they will look like when they get old.
The entrance hall rang with laughter. Even Fred and George joined in, once they had gotten to their feet and taken a good look at each other’s beards.
“because Dobby wants paying now”
“Dobby has traveled the country for two whole years, sir, trying to find work!” Dobby squeaked. “But Dobby hasn’t found work, sir, because Dobby wants paying now!”
The house-elves all around the kitchen, who had been listening and watching with interest, all looked away at these words, as though Dobby had said something rude and embarrassing.
Hermione, however, said, “Good for you, Dobby!”
“Thank you, miss!” said Dobby, grinning toothily at her. “But most wizards doesn’t want a house-elf who wants paying, miss. ‘That’s not the point of a house-elf,’ they says, and they slammed the door in Dobby’s face! Dobby likes work, but he wants to wear clothes and he wants to be paid, Harry Potter. . . . Dobby likes being free!”
“Oh no, sir, no,” said Dobby, looking suddenly serious. “ ‘Tis part of the house-elf’s enslavement, sir. We keeps their secrets and our silence, sir. We upholds the family’s honor, and we never speaks ill of them — though Professor Dumbledore told Dobby he does not insist upon this. Professor Dumbledore said we is free to — to —“
Dobby looked suddenly nervous and beckoned Harry closer.
Harry bent forward. Dobby whispered, “He said we is free to call him a — a barmy old codger if we likes, sir!”
Dobby gave a frightened sort of giggle.
“But Dobby is not wanting to, Harry Potter,” he said, talking normally again, and shaking his head so that his ears flapped.
“Dobby likes Professor Dumbledore very much, sir, and is proud to keep his secrets and our silence for him.”
“temporarily deaf”
“Of course we still want to know you!” Harry said, staring at Hagrid. “You don’t think anything that Skeeter cow — sorry, Professor,” he added quickly, looking at Dumbledore.
“I have gone temporarily deaf and haven’t any idea what you said, Harry,” said Dumbledore, twiddling his thumbs and staring at the ceiling.
“Really, Hagrid, if you are holding out for universal popularity,
I’m afraid you will be in this cabin for a very long time,” said Dumbledore, now peering sternly over his half-moon spectacles. “Not a week has passed since I became headmaster of this school when I haven’t had at least one owl complaining about the way I run it. But what should I do? Barricade myself in my study and refuse to talk to anybody?”
Another subtle foreshadowing. One must finish reading the entire book before being impressed by Dumbledore’s foresight.
For a fleeting instant, Harry thought he saw a gleam of something like triumph in Dumbledore’s eyes.
“You are blinded,” said Dumbledore, his voice rising now, the aura of power around him palpable, his eyes blazing once more, “by the love of the office you hold, Cornelius! You place too much importance, and you always have done, on the so-called purity of blood! You fail to recognize that it matters not what someone is born, but what they grow to be! Your dementor has just destroyed the last remaining member of a pure-blood family as old as any — and see what that man chose to make of his life!
“make a choice between what is right and what is easy”.
Remember Cedric. Remember, if the time should come when you have to make a choice between what is right and what is easy, remember what happened to a boy who was good, and kind, and brave, because he strayed across the path of Lord Voldemort. Remember Cedric Diggory.
“Listen,” said Harry firmly. “If you don’t take it, I’m throwing it down the drain. I don’t want it and I don’t need it. But I could do with a few laughs. We could all do with a few laughs. I’ve got a feeling we’re going to need them more than usual before long.”
HP5
DO NOT SURRENDER YOUR WAND
Harry —
Dumbledore’s just arrived at the Ministry, and he’s trying to sort it all out. DO NOT LEAVE YOUR AUNT AND UNCLE’S HOUSE. DO NOT DO ANY MORE MAGIC. DO NOT SURRENDER YOUR WAND
I think it’s funny, since it remind me of Sir Humphrey Appleby.
… because some changes will be for the better, while others will come, in the fullness of time, to be recognized as errors of judgment. Meanwhile, some old habits will be retained, and rightly so, whereas others, outmoded and outworn, must be abandoned. Let us move forward, then, into a new era of openness, effectiveness, and accountability, intent on preserving what ought to be preserved, perfecting what needs to be perfected, and pruning wherever we find practices that ought to be prohibited.
“You told her He-Who-Must-Not-Be-Named is back?
“Yes.”
Professor McGonagall sat down behind her desk, frowning at Harry.
Then she said, “Have a biscuit, Potter.”
That tells the difference between Hermione and Percy.
“You disagree?”
“Yes, I do,” said Hermione, who, unlike Umbridge, was not whispering, but speaking in a clear, carrying voice that had by now attracted the rest of the class’s attention. “Mr. Slinkhard doesn’t like jinxes, does he? But I think they can be very useful when they’re used defensively.”
Ron’s awkward compliment shows the subtle change in his relationship with Hermione.
“We do try,” said Ron. “We just haven’t got your brains or your memory or your concentration — you’re just cleverer than we are — is it nice to rub it in?”
“Oh, don’t give me that rubbish,” said Hermione, but she looked slightly mollified as she led the way out into the damp courtyard.
Excellent sarcasm.
“For disrupting my class with pointless interruptions,” said Professor Umbridge smoothly. “I am here to teach you using a Ministry approved method that does not include inviting students to give their opinions on matters about which they understand very little. Your previous teachers in this subject may have allowed you more license, but as none of them — with the possible exception of Professor Quirrell, who did at least appear to have restricted himself to age-appropriate subjects — would have passed a Ministry inspection —“
“Yeah, Quirrell was a great teacher,” said Harry loudly, “there was just that minor drawback of him having Lord Voldemort sticking out of the back of his head.”
Hermione is not a nerd.
Nobody raised objections after Ernie, though Harry saw Cho’s friend give her a rather reproachful look before adding her name. When the last person — Zacharias — had signed, Hermione took the parchment back and slipped it carefully into her bag. There was an odd feeling in the group now. It was as though they had just signed some kind of contract.
He was on the sixth stair when it happened. There was a loud, wailing, klaxonlike sound and the steps melted together to make a long, smooth stone slide. There was a brief moment when Ron tried to keep running, arms working madly like windmills, then he toppled over backward and shot down the newly created slide, coming to rest on his back at Harry’s feet.
Umbridge’s confrontation with Snape. Snape refused to say one more word to deal with Umbridge’s nonsense.
“Well, the class seems fairly advanced for their level,” she said briskly to Snape’s back. “Though I would question whether it is advisable to teach them a potion like the Strengthening Solution. I think the Ministry would prefer it if that was removed from the syllabus.”
Snape straightened up slowly and turned to look at her.
“Now … how long have you been teaching at Hogwarts?” she asked, her quill poised over her clipboard.
“Fourteen years,” Snape replied. His expression was unfathomable.
His eyes on Snape, Harry added a few drops to his potion; it hissed menacingly and turned from turquoise to orange.
“You applied first for the Defense Against the Dark Arts post, I believe?” Professor Umbridge asked Snape.
“Yes,” said Snape quietly.
“But you were unsuccessful?”
Snape’s lip curled.
“Obviously.”
Professor Umbridge scribbled on her clipboard.
“And you have applied regularly for the Defense Against the Dark Arts post since you first joined the school, I believe?”
“Yes,” said Snape quietly, barely moving his lips. He looked very angry.
“Do you have any idea why Dumbledore has consistently refused to appoint you?” asked Umbridge.
“I suggest you ask him,” said Snape jerkily.
“Oh I shall,” said Professor Umbridge with a sweet smile.
“I suppose this is relevant?” Snape asked, his black eyes narrowed.
It is always wise to take fate firmly in one’s own hands.
“Well, better expelled and able to defend yourselves than sitting safely in school without a clue,” said Sirius.
Some parents are “living through us”.
“You don’t think he has become … sort of … reckless … since he’s been cooped up in Grimmauld Place? You don’t think he’s … kind of … living through us?”
there are things worth dying for
“Your father knew what he was getting into, and he won’t thank you for messing things up for the Order!” said Sirius angrily in his turn. “This is how it is — this is why you’re not in the Order — you don’t understand — there are things worth dying for!”
“Easy for you to say, stuck here!” bellowed Fred. “I don’t see you risking your neck!”
Being a victim is not a shame. However, being a fighter is more honorable.
“What’s this?” said Mrs. Longbottom sharply. “Haven’t you told your friends about your parents, Neville?”
Neville took a deep breath, looked up at the ceiling, and shook his head. Harry could not remember ever feeling sorrier for anyone, but he could not think of any way of helping Neville out of the situation.
“Well, it’s nothing to be ashamed of!” said Mrs. Longbottom angrily. “You should be proud, Neville, proud! They didn’t give their health and their sanity so their only son would be ashamed of them, you know!”
“I’m not ashamed,” said Neville very faintly, still looking anywhere but at Harry and the others. Ron was now standing on tiptoe to look over at the inhabitants of the two beds.
“Well, you’ve got a funny way of showing it!” said Mrs. Longbottom. “My son and his wife,” she said, turning haughtily to Harry, Ron, Hermione, and Ginny, “were tortured into insanity by You-Know-Who’s followers.”
Hermione and Ginny both clapped their hands over their mouths.
Ron stopped craning his neck to catch a glimpse of Neville’s parents and looked mortified.
“They were Aurors, you know, and very well respected within the Wizarding community,” Mrs. Longbottom went on. “Highly gifted, the pair of them. I — yes, Alice dear, what is it?”
An incisive comment on speech censorship.
“Oh Harry, don’t you see?” Hermione breathed. “If she could have done one thing to make absolutely sure that every single person in this school will read your interview, it was banning it!”
Brilliant irony.
“Oh, so that’s why he wasn’t prosecuted for setting up all those regurgitating toilets!” said Professor McGonagall, raising her eyebrows. “What an interesting insight into our justice system!”
I cannot allow you to manhandle my students
“Well, usually when a person shakes their head,” said McGonagall coldly, “they mean ‘no.’ So unless Miss Edgecombe is using a form of sign language as yet unknown to humans —“
Professor Umbridge seized Marietta, pulled her around to face her, and began shaking her very hard. A split second later Dumbledore was on his feet, his wand raised. Kingsley started forward and Umbridge leapt back from Marietta, waving her hands in the air as though they had been burned.
“I cannot allow you to manhandle my students, Dolores,” said Dumbledore, and for the first time, he looked angry.
“You want to calm yourself, Madam Umbridge,” said Kingsley in his deep, slow voice. “You don’t want to get yourself into trouble now.”
Dumbledore’s contempt of Fudge jumps off the page.
“Well, the game is up,” he said simply. “Would you like a written confession from me, Cornelius — or will a statement before these witnesses suffice?”
Harry saw McGonagall and Kingsley look at each other. There was fear in both faces. He did not understand what was going on, and neither, apparently, did Fudge.
“Statement?” said Fudge slowly. “What — I don’t — ?”
“Dumbledore’s Army, Cornelius,” said Dumbledore, still smiling as he waved the list of names before Fudge’s face. “Not Potter’s Army. Dumbledore’s Army.”
“But — but —“
Understanding blazed suddenly in Fudge’s face. He took a horrified step backward, yelped, and jumped out of the fire again.
“You?” he whispered, stamping again on his smoldering cloak.
“That’s right,” said Dumbledore pleasantly.
“You organized this?”
“I did,” said Dumbledore.
“You recruited these students for — for your army?”
“Tonight was supposed to be the first meeting,” said Dumbledore, nodding. “Merely to see whether they would be interested in joining me. I see now that it was a mistake to invite Miss Edgecombe, of course.”
Marietta nodded. Fudge looked from her to Dumbledore, his chest swelling.
“Then you have been plotting against me!” he yelled.
“That’s right,” said Dumbledore cheerfully.
“NO!” shouted Harry.
Kingsley flashed a look of warning at him, McGonagall widened her eyes threateningly, but it had suddenly dawned upon Harry what Dumbledore was about to do, and he could not let it happen.
“No — Professor Dumbledore!”
“Be quiet, Harry, or I am afraid you will have to leave my office,” said Dumbledore calmly.
“Yes, shut up, Potter!” barked Fudge, who was still ogling Dumbledore with a kind of horrified delight. “Well, well, well — I came here tonight expecting to expel Potter and instead —“
“Instead you get to arrest me,” said Dumbledore, smiling. “It’s like losing a Knut and finding a Galleon, isn’t it?”
“Weasley!” cried Fudge, now positively quivering with delight, “Weasley, have you written it all down, everything he’s said, his confession, have you got it?”
“Yes, sir, I think so, sir!” said Percy eagerly, whose nose was splattered with ink from the speed of his note-taking.
“The bit about how he’s been trying to build up an army against the Ministry, how he’s been working to destabilize me?”
“Yes, sir, I’ve got it, yes!” said Percy, scanning his notes joyfully.
“Very well, then,” said Fudge, now radiant with glee. “Duplicate your notes, Weasley, and send a copy to the Daily Prophet at once. If we send a fast owl we should make the morning edition!” Percy dashed from the room, slamming the door behind him, and Fudge turned back to Dumbledore. “You will now be escorted back to the Ministry, where you will be formally charged and then sent to Azkaban to await trial!”
“Ah,” said Dumbledore gently, “yes. Yes, I thought we might hit that little snag.”
“Snag?” said Fudge, his voice still vibrating with joy. “I see no snag, Dumbledore!”
“Well,” said Dumbledore apologetically, “I’m afraid I do.”
“Oh really?”
“Well — it’s just that you seem to be laboring under the delusion that I am going to — what is the phrase? ‘Come quietly’ I am afraid I am not going to come quietly at all, Cornelius. I have absolutely no intention of being sent to Azkaban. I could break out, of course — but what a waste of time, and frankly, I can think of a whole host of things I would rather be doing.”
Umbridge’s face was growing steadily redder, she looked as though she was being filled with boiling water. Fudge stared at Dumbledore with a very silly expression on his face, as though he had just been stunned by a sudden blow and could not quite believe it had happened. He made a small choking noise and then looked around at Kingsley and the man with short gray hair, who alone of everyone in the room had remained entirely silent so far. The latter gave Fudge a reassuring nod and moved forward a little, away from the wall. Harry saw his hand drift, almost casually, toward his pocket.
“Don’t be silly, Dawlish,” said Dumbledore kindly. “I’m sure you are an excellent Auror, I seem to remember that you achieved ‘Outstanding’ in all your N.E.W.T.s, but if you attempt to — er — ‘bring me in’ by force, I will have to hurt you.”
The man called Dawlish blinked, looking rather foolish. He looked toward Fudge again, but this time seemed to be hoping for a clue as to what to do next.
“So,” sneered Fudge, recovering himself, “you intend to take on Dawlish, Shacklebolt, Dolores, and myself single-handed, do you, Dumbledore?”
“Merlin’s beard, no,” said Dumbledore, smiling. “Not unless you are foolish enough to force me to.”
“He will not be single-handed!” said Professor McGonagall loudly, plunging her hand inside her robes.
“Oh yes he will, Minerva!” said Dumbledore sharply. “Hogwarts needs you!”
“Enough of this rubbish!” said Fudge, pulling out his own wand.
“Dawlish! Shacklebolt! Take him!”
A streak of silver light flashed around the room. There was a bang like a gunshot, and the floor trembled. A hand grabbed the scruff of Harry’s neck and forced him down on the floor as a second silver flash went off — several of the portraits yelled, Fawkes screeched, and a cloud of dust filled the air. Coughing in the dust, Harry saw a dark figure fall to the ground with a crash in front of him. There was a shriek and a thud and somebody cried, “No!” Then the sound of breaking glass, frantically scuffling footsteps, a groan — and silence.
Harry struggled around to see who was half-strangling him and saw Professor McGonagall crouched beside him. She had forced both him and Marietta out of harm’s way. Dust was still floating gently down through the air onto them. Panting slightly, Harry saw a very tall figure moving toward them.
“ ‘Course we have,” said George. “Never been expelled, have we?”
“We’ve always known where to draw the line,” said Fred.
“We might have put a toe across it occasionally,” said George.
“But we’ve always stopped short of causing real mayhem,” said Fred.
“But now?” said Ron tentatively.
“Well, now —“ said George.
“— what with Dumbledore gone —“ said Fred.
“— we reckon a bit of mayhem —“ said George.
“— is exactly what our dear new Head deserves,” said Fred.
“You mustn’t!” whispered Hermione. “You really mustn’t! She’d love a reason to expel you!”
“You don’t get it, Hermione, do you?” said Fred, smiling at her.
“We don’t care about staying anymore. We’d walk out right now if we weren’t determined to do our bit for Dumbledore first. So anyway,” he checked his watch, “phase one is about to begin. I’d get in the Great Hall for lunch if I were you, that way the teachers will see you can’t have had anything to do with it.”
“Thank you so much, Professor!” said Professor Flitwick in his squeaky little voice. “I could have got rid of the sparklers myself, of course, but I wasn’t sure whether I had the authority… .”
Hermione and rebellious…
“Oh, why don’t we have a night off?” said Hermione brightly, as a silver-tailed Weasley rocket zoomed past the window. “After all, the Easter holidays start on Friday, we’ll have plenty of time then… .”
“Are you feeling all right?” Ron asked, staring at her in disbelief.
“Now you mention it,” said Hermione happily, “d’you know … I think I’m feeling a bit … rebellious.”
When it comes to satire, McGonagall will never let you down.
“I should have made my meaning plainer,” said Professor McGonagall, turning at last to look Umbridge directly in the eyes. “He has achieved high marks in all Defense Against the Dark Arts tests set by a competent teacher.”
“She towered over”
Professor McGonagall got to her feet too, and in her case this was a much more impressive move. She towered over Professor Umbridge.
“Potter,” she said in ringing tones, “I will assist you to become an Auror if it is the last thing I do! If I have to coach you nightly I will make sure you achieve the required results!”
“The Minister of Magic will never employ Harry Potter!” said Umbridge, her voice rising furiously.
“There may well be a new Minister of Magic by the time Potter is ready to join!” shouted Professor McGonagall.
Glorious finale of Fred and George’s schooling.
“You know what?” said Fred. “I don’t think we are.”
He turned to his twin.
“George,” said Fred, “I think we’ve outgrown full-time education.”
“Yeah, I’ve been feeling that way myself,” said George lightly.
“Time to test our talents in the real world, d’you reckon?” asked Fred.
“Definitely,” said George.
And before Umbridge could say a word, they raised their wands and said together, “Accio Brooms!”
Harry heard a loud crash somewhere in the distance. Looking to his left he ducked just in time — Fred and George’s broomsticks, one still trailing the heavy chain and iron peg with which Umbridge had fastened them to the wall, were hurtling along the corridor toward their owners. They turned left, streaked down the stairs, and stopped sharply in front of the twins, the chain clattering loudly on the flagged stone floor.
“We won’t be seeing you,” Fred told Professor Umbridge, swinging his leg over his broomstick.
“Yeah, don’t bother to keep in touch,” said George, mounting his own.
Fred looked around at the assembled students, and at the silent, watchful crowd.
“If anyone fancies buying a Portable Swamp, as demonstrated upstairs, come to number ninety-three, Diagon Alley — Weasleys’ Wizarding Wheezes,” he said in a loud voice. “Our new premises!”
“Special discounts to Hogwarts students who swear they’re going to use our products to get rid of this old bat,” added George, pointing at Professor Umbridge.
“STOP THEM!” shrieked Umbridge, but it was too late. As the Inquisitorial Squad closed in, Fred and George kicked off from the floor, shooting fifteen feet into the air, the iron peg swinging dangerously below. Fred looked across the hall at the poltergeist bobbing on his level above the crowd.
“Give her hell from us, Peeves.”
And Peeves, whom Harry had never seen take an order from a student before, swept his belled hat from his head and sprang to a salute as Fred and George wheeled about to tumultuous applause from the students below and sped out of the open front doors into the glorious sunset.
Indeed, a week after Fred and George’s departure Harry witnessed Professor McGonagall walking right past Peeves, who was determinedly loosening a crystal chandelier, and could have sworn he heard her tell the poltergeist out of the corner of her mouth, “It unscrews the other way.”
there are things much worse than death
“We both know that there are other ways of destroying a man, Tom,” Dumbledore said calmly, continuing to walk toward Voldemort as though he had not a fear in the world, as though nothing had happened to interrupt his stroll up the hall. “Merely taking your life would not satisfy me, I admit —“
“There is nothing worse than death, Dumbledore!” snarled Voldemort.
“You are quite wrong,” said Dumbledore, still closing in upon Voldemort and speaking as lightly as though they were discussing the matter over drinks. Harry felt scared to see him walking along, undefended, shieldless. He wanted to cry out a warning, but his headless guard kept shunting him backward toward the wall, blocking his every attempt to get out from behind it. “Indeed, your failure to understand that there are things much worse than death has always been your greatest weakness —“
faltered … as surveyed … magisterially over …
This is one of the few scenes in which Dumbledore act very aggresively. Don’t forget that he used to hand out with Grindelwald.
“Now see here, Dumbledore!” said Fudge, as Dumbledore picked up the head and walked back to Harry carrying it. “You haven’t got authorization for that Portkey! You can’t do things like that right in front of the Minister of Magic, you — you —“
His voice faltered as Dumbledore surveyed him magisterially over his half-moon spectacles.
“You will give the order to remove Dolores Umbridge from Hogwarts,” said Dumbledore. “You will tell your Aurors to stop searching for my Care of Magical Creatures teacher so that he can return to work. I will give you …” Dumbledore pulled a watch with twelve hands from his pocket and glanced at it, “half an hour of my time tonight, in which I think we shall be more than able to cover the important points of what has happened here. After that, I shall need to return to my school. If you need more help from me you are, of course, more than welcome to contact me at Hogwarts. Letters addressed to the headmaster will find me.”
“Kreacher is what he has been made by wizards, Harry,” said Dumbledore. “Yes, he is to be pitied. His existence has been as miserable as your friend Dobby’s. He was forced to do Sirius’s bidding, because Sirius was the last of the family to which he was enslaved, but he felt no true loyalty to him. And whatever Kreacher’s faults, it must be admitted that Sirius did nothing to make Kreacher’s lot easier —“
“Sirius did not hate Kreacher,” said Dumbledore. “He regarded him as a servant unworthy of much interest or notice. Indifference and neglect often do much more damage than outright dislike… .
The fountain we destroyed tonight told a lie. We wizards have mistreated and abused our fellows for too long, and we are now reaping our reward.”
Well, Flitwick’s got rid of Fred and George’s swamp,” said Ginny.
“He did it in about three seconds. But he left a tiny patch under the window and he’s roped it off —“
“Why?” said Hermione, looking startled.
“Oh, he just says it was a really good bit of magic,” said Ginny, shrugging.
“I think he left it as a monument to Fred and George,” said Ron through a mouthful of chocolate. “They sent me all these, you know,” he told Harry, pointing at the small mountain of Frogs beside him.
“Must be doing all right out of that joke shop, eh?”
who can be intimidated
“And do I look like the kind of man who can be intimidated?” barked Uncle Vernon.
“Well …” said Moody, pushing back his bowler hat to reveal his sinisterly revolving magical eye. Uncle Vernon leapt backward in horror and collided painfully with a luggage trolley. “Yes, I’d have to say you do, Dursley.”
HP6
“You are determined to hate him”
“You are determined to hate him, Harry,” said Lupin with a faint smile.
Snape’s irony
“Yes, indeed, most admirable,” said Snape in a bored voice. “Of course, you weren’t a lot of use to him in prison, but the gesture was undoubtedly fine —“
“Gesture!” she shrieked; in her fury she looked slightly mad.
“While I endured the dementors, you remained at Hogwarts, comfortably playing Dumbledore’s pet!”
Greate self-defending
“Think!” said Snape, impatient again. “Think! By waiting two hours, just two hours, I ensured that I could remain at Hogwarts as a spy! By allowing Dumbledore to think that I was only returning to the Dark Lord’s side because I was ordered to, I have been able to pass information on Dumbledore and the Order of the Phoenix ever since! Consider, Bellatrix: The Dark Mark had been growing stronger for months. I knew he must be about to return, all the Death Eaters knew! I had plenty of time to think about what I wanted to do, to plan my next move, to escape like Karkaroff, didn’t I?
Harry got to his feet. As he walked across the room, his eyes fell upon the little table on which Marvolo Gaunt’s ring had rested last time, but the ring was no longer there.
“Yes, Harry?” said Dumbledore, for Harry had come to a halt.
“The ring’s gone,” said Harry, looking around. “But I thought you might have the mouth organ or something.”
Dumbledore beamed at him, peering over the top of his halfmoon spectacles.
“Very astute, Harry, but the mouth organ was only ever a mouth organ.”
And on that enigmatic note he waved to Harry, who understood himself to be dismissed.
A very tough conversation with the Ministry.
“But if I keep running in and out of the Ministry,” said Harry, still endeavoring to keep his voice friendly, “won’t that seem as though I approve of what the Ministry’s up to?”
“Well,” said Scrimgeour, frowning slightly, “well, yes, that’s partly why we’d like —“
“No, I don’t think that’ll work,” said Harry pleasantly. “You see, I don’t like some of the things the Ministry’s doing. Locking up Stan Shunpike, for instance.”
Scrimgeour did not speak for a moment but his expression hardened instantly. “I would not expect you to understand,” he said, and he was not as successful at keeping anger out of his voice as Harry had been. “These are dangerous times, and certain measures need to be taken. You are sixteen years old —“
“Dumbledore’s a lot older than sixteen, and he doesn’t think Stan should be in Azkaban either,” said Harry. “You’re making Stan a scapegoat, just like you want to make me a mascot.”
They looked at each other, long and hard. Finally Scrimgeour said, with no pretense at warmth, “I see. You prefer — like your hero, Dumbledore — to disassociate yourself from the Ministry?”
“I don’t want to be used,” said Harry.
“Some would say it’s your duty to be used by the Ministry!”
“Yeah, and others might say it’s your duty to check that people really are Death Eaters before you chuck them in prison,” said Harry, his temper rising now. “You’re doing what Barty Crouch did. You never get it right, you people, do you? Either we’ve got Fudge, pretending everything’s lovely while people get murdered right under his nose, or we’ve got you, chucking the wrong people into jail and trying to pretend you’ve got ‘the Chosen One’ working for you!”
“So you’re not ‘the Chosen One’?” said Scrimgeour.
“I thought you said it didn’t matter either way?” said Harry, with a bitter laugh. “Not to you anyway.”
“I shouldn’t have said that,” said Scrimgeour quickly. “It was tactless —“
“No, it was honest,” said Harry. “One of the only honest things you’ve said to me. You don’t care whether I live or die, but you do care that I help you convince everyone you’re winning the war against Voldemort. I haven’t forgotten, Minister… .”
He raised his right fist. There, shining white on the back of his cold hand, were the scars which Dolores Umbridge had forced him to carve into his own flesh: I must not tell lies.
“I don’t remember you rushing to my defense when I was trying to tell everyone Voldemort was back. The Ministry wasn’t so keen to be pals last year.”
They stood in silence as icy as the ground beneath their feet. The gnome had finally managed to extricate his worm and was now sucking on it happily, leaning against the bottommost branches of the rhododendron bush.
“What is Dumbledore up to?” said Scrimgeour brusquely.
“Where does he go when he is absent from Hogwarts?”
“No idea,” said Harry.
“And you wouldn’t tell me if you knew,” said Scrimgeour, “would you?”
“No, I wouldn’t,” said Harry.
“a baboon brandishing a stick”, LOL
“Harry’s already Apparated,” Ron told a slightly abashed Seamus, after Professor Flitwick had dried himself off with a wave of his wand and set Seamus lines: “I am a wizard, not a baboon brandishing a stick.” “Dum — er — someone took him. Side-Along Apparition, you know.”
“He accused me of being ‘Dumbledore’s man through and through.’ “
“How very rude of him.”
“I told him I was.”
He raised his glass as though toasting Voldemort, whose face remained expressionless. Nevertheless, Harry felt the atmosphere in the room change subtly: Dumbledore’s refusal to use Voldemort’s chosen name was a refusal to allow Voldemort to dictate the terms of the meeting, and Harry could tell that Voldemort took it as such.
“For the greater good”.
“You call it ‘greatness,’ what you have been doing, do you?” asked Dumbledore delicately.
“Certainly,” said Voldemort, and his eyes seemed to burn red. “I have experimented; I have pushed the boundaries of magic further, perhaps, than they have ever been pushed —“
“Of some kinds of magic,” Dumbledore corrected him quietly. “Of some. Of others, you remain … forgive me … woefully ignorant.”
“I am glad to hear that you consider them friends,” said Dumbledore. “I was under the impression that they are more in the order of servants.”
“Let us speak openly. Why have you come here tonight, surrounded by henchmen, to request a job we both know you do not want?”
Voldemort looked coldly surprised. “A job I do not want? On the contrary, Dumbledore, I want it very much.”
“Oh, you want to come back to Hogwarts, but you do not want to teach any more than you wanted to when you were eighteen. What is it you’re after, Tom? Why not try an open request for once?”
Voldemort sneered. “If you do not want to give me a job —“
“Of course I don’t,” said Dumbledore. “And I don’t think for a moment you expected me to. Nevertheless, you came here, you asked, you must have had a purpose.”
The most valuable thing of a man is braveness.
“Of course, it doesn’t matter how he looks… . It’s not r-really important … but he was a very handsome little b-boy … always very handsome … and he was g-going to be married!”
“And what do you mean by zat?” said Fleur suddenly and loudly.
“What do you mean, ‘ ‘e was going to be married?’ “
Mrs. Weasley raised her tear-stained face, looking startled.
“Well — only that —“
“You theenk Bill will not wish to marry me anymore?” demanded Fleur. “You theenk, because of these bites, he will not love me?”
“No, that’s not what I —“
“Because ‘e will!” said Fleur, drawing herself up to her full height and throwing back her long mane of silver hair. “It would take more zan a werewolf to stop Bill loving me!”
“Well, yes, I’m sure,” said Mrs. Weasley, “but I thought perhaps — given how — how he —“
“You thought I would not weesh to marry him? Or per’aps, you hoped?” said Fleur, her nostrils flaring. “What do I care how he looks? I am good-looking enough for both of us, I theenk! All these scars show is zat my husband is brave! And I shall do zat!” she added fiercely, pushing Mrs. Weasley aside and snatching the ointment from her.
Mrs. Weasley fell back against her husband and watched Fleur mopping up Bill’s wounds with a most curious expression upon her face. Nobody said anything; Harry did not dare move. Like everybody else, he was waiting for the explosion.
“Our Great-Auntie Muriel,” said Mrs. Weasley after a long pause, “has a very beautiful tiara — goblin-made — which I am sure I could persuade her to lend you for the wedding. She is very fond of Bill, you know, and it would look lovely with your hair.”
“Thank you,” said Fleur stiffly. “I am sure zat will be lovely.”
And then, Harry did not quite see how it happened, both women were crying and hugging each other. Completely bewildered, wondering whether the world had gone mad, he turned around: Ron looked as stunned as he felt and Ginny and Hermione were exchanging startled looks.
she would not say, “Be careful,” or “Don’t do it,” but accept his decision, because she would not have expected anything less of him
Harry looked at Ginny, Ron, and Hermione: Ron’s face was screwed up as though the sunlight were blinding him. Hermione’s face was glazed with tears, but Ginny was no longer crying. She met Harry’s gaze with the same hard, blazing look that he had seen when she had hugged him after winning the Quidditch Cup in his absence, and he knew that at that moment they understood each other perfectly, and that when he told her what he was going to do now, she would not say, “Be careful,” or “Don’t do it,” but accept his decision, because she would not have expected anything less of him. And so he steeled himself to say what he had known he must say ever since Dumbledore had died.
HP7
“He must’ve known you’d always want to come back.”
But I don’t think so, not anymore. He knew what he was doing when he gave me the Deluminator, didn’t he? He — well,” Ron’s ears turned bright red and he became engrossed in a tuft of grass at his feet, which he prodded with his toe, “he must’ve known I’d run out on you.”
“No,” Harry corrected him. “He must’ve known you’d always want to come back.”
“And if it does fall into his grasp,” said Dumbledore, almost, it seemed, as an aside, “I have your word that you will do all in your power to protect the students of Hogwarts?”
“Professor Snape sent them into the Forbidden Forest, to do some work for the oaf, Hagrid.”
“Hagrid’s not an oaf!” said Hermione shrilly.
“And Snape might’ve thought that was a punishment,” said Harry, “but Ginny, Neville, and Luna probably had a good laugh with Hagrid. The Forbidden Forest . . . they’ve faced plenty worse than the Forbidden Forest, big deal!”
This is a very giant change of Harry. He finally learned how to shut his mind from Voldemort, and he’s no longer obsessed with Hallows.
His scar burned, but he was master of the pain; he felt it, yet was apart from it. He had learned control at last, learned to shut his mind to Voldemort, the very thing Dumbledore had wanted him to learn from Snape. Just as Voldemort had not been able to possess Harry while Harry was consumed with grief for Sirius, so his thoughts could not penetrate Harry now, while he mourned Dobby.
Grief, it seemed, drove Voldemort out . . . though Dumbledore, of course, would have said that it was love. . . .
On Harry dug, deeper and deeper into the hard, cold earth, subsuming his grief in sweat, denying the pain in his scar. In the darkness, with nothing but the sound of his own breath and the rushing sea to keep him company, the things that had happened at the Malfoys’ returned to him, the things he had heard came back to him, and understanding blossomed in the darkness. . . .
The steady rhythm of his arms beat time with his thoughts. Hallows . . . Horcruxes . . . Hallows . . . Horcruxes . . . Yet he no longer burned with that weird, obsessive longing. Loss and fear had snuffed it out: He felt as though he had been slapped awake again.
Deeper and deeper Harry sank into the grave, and he knew where Voldemort had been tonight, and whom he had killed in the topmost cell of Nurmengard, and why. . . .
And he thought of Wormtail, dead because of one small unconscious impulse of mercy. . . . Dumbledore had foreseen that. . . . How much more had he known?
Another side depiction of Naville’s family.
“Yeah, well, I couldn’t ask people to go through what Michael did, so we dropped those kinds of stunts. But we were still fighting, doing underground stuff, right up until a couple of weeks ago. That’s when they decided there was only one way to stop me, I suppose, and they went for Gran.”
“They what?” said Harry, Ron, and Hermione together.
“Yeah,” said Neville, panting a little now, because the passage was climbing so steeply, “well, you can see their thinking. It had worked really well, kidnapping kids to force their relatives to behave, I s’pose it was only a matter of time before they did it the other way around. Thing was,” he faced them, and Harry was astonished to see that he was grinning, “they bit off a bit more than they could chew with Gran. Little old witch living alone, they probably thought they didn’t need to send anyone particularly powerful. Anyway,” Neville laughed, “Dawlish is still in St. Mungo’s and Gran’s on the run. She sent me a letter,” he clapped a hand to the breast pocket of his robes, “telling me she was proud of me, that I’m my parents’ son, and to keep it up.”
This little episode shows Ron’s character traits vividly.
“Your mother can’t produce food out of thin air,” said Hermione. “No one can. Food is the first of the five Principal Exceptions to Gamp’s Law of Elemental Transfigur —“
“Oh, speak English, can”t you?” Ron said, prising a fish bone outfrom between his teeth.
“Yeah, well, food’s one of the five exceptions to Gamp’s Law of Elemental Transfiguration,” said Ron to general astonishment.
“Why would Harry Potter try to get inside Ravenclaw Tower? Potter belongs in my House!”
Beneath the disbelief and anger, Harry heard a little strain of pride in her voice, and affection for Minerva McGonagall gushed up inside him.
“It’s not a case of what you’ll permit, Minerva McGonagall. Your time’s over. It’s us what’s in charge here now, and you’ll back me up or you’ll pay the price.” And he spat in her face.
Harry pulled the Cloak off himself, raised his wand, and said, “You shouldn’t have done that.”
As Amycus spun around, Harry shouted, “Crucio!”
“Potter, I — that was very — very gallant of you — but don’t you realize — ?”
There was a sound of movement, of clinking glass: Amycus was coming round. Before Harry or Luna could act, Professor McGonagall rose to her feet, pointed her wand at the groggy Death Eater, and said, “Imperio.”
The aged caretaker had just come hobbling into view, shouting, “Students out of bed! Students in the corridors!”
“They’re supposed to be, you blithering idiot!” shouted McGonagall. “Now go and do something constructive! Find Peeves!”
Percy returns to the arms of his family.
“I was a fool!” Percy roared, so loudly that Lupin nearly dropped his photograph. “I was an idiot, I was a pompous prat, I was a — a —“
“Ministry-loving, family-disowning, power-hungry moron,” said Fred.
Percy swallowed.
“Yes, I was!”
“Well, you can’t say fairer than that,” said Fred, holding out his hand to Percy.
Mrs. Weasley burst into tears. She ran forward, pushed Fred aside, and pulled Percy into a strangling hug, while he patted her on the back, his eyes on his father.
“Well, we do look to our prefects to take a lead at times such as these,” said George in a good imitation of Percy’s most pompous manner. “Now let’s get upstairs and fight, or all the good Death Eaters’ll be taken.”
“I am not such a coward.”
“Karkaroff’s Mark is becoming darker too. He is panicking, he fears retribution; you know how much help he gave the Ministry after the Dark Lord fell.” Snape looked sideways at Dumbledore’s crooked-nosed profile. “Karkaroff intends to flee if the Mark burns.”
“Does he?” said Dumbledore softly, as Fleur Delacour and Roger Davies came giggling in from the grounds. “And are you tempted to join him?”
“No,” said Snape, his black eyes on Fleur’s and Roger’s retreating figures. “I am not such a coward.”
“No,” agreed Dumbledore. “You are a braver man by far than Igor Karkaroff. You know, I sometimes think we Sort too soon… .”
Snape began to care for his soul. This is a big change of him.
“If you don’t mind dying,” said Snape roughly, “why not let Draco do it?”
“That boy’s soul is not yet so damaged,” said Dumbledore. “I would not have it ripped apart on my account.”
“And my soul, Dumbledore? Mine?”
“You alone know whether it will harm your soul to help an old man avoid pain and humiliation,” said Dumbledore.
This is also a very important conversation. Snape no longer fight only for Lily, but for justice now.
“Don’t be shocked, Severus. How many men and women have you watched die?”
“Lately, only those whom I could not save,” said Snape. He stood up. “You have used me.”
“Meaning?”
“I have spied for you and lied for you, put myself in mortal danger for you. Everything was supposed to be to keep Lily Potter’s son safe. Now you tell me you have been raising him like a pig for slaughter —“
“But this is touching, Severus,” said Dumbledore seriously. “Have you grown to care for the boy, after all?”
“For him?” shouted Snape. “Expecto Patronum!”
From the tip of his wand burst the silver doe: She landed on the office floor, bounded once across the office, and soared out of the window. Dumbledore watched her fly away, and as her silvery glow faded he turned back to Snape, and his eyes were full of tears.
“After all this time?”
“Always,” said Snape.
There is always something worth giving your life for.
“I am sorry too,” said Lupin. “Sorry I will never know him … but he will know why I died and I hope he will understand. I was trying to make a world in which he could live a happier life.”
“Would I?” asked Dumbledore heavily. “I am not so sure. I had proven, as a very young man, that power was my weakness and my temptation. It is a curious thing, Harry, but perhaps those who are best suited to power are those who have never sought it. Those who, like you, have leadership thrust upon them, and take up the mantle because they must, and find to their own surprise that they wear it well.
At last he said, “Grindelwald tried to stop Voldemort going after the wand. He lied, you know, pretended he had never had it.”
You are the true master of death, because the true master does not seek to run away from Death. He accepts that he must die, and understands that there are far, far worse things in the living world than dying.
Pity the living
“I’ve got to go back, haven’t I?”
“That is up to you.”
“I’ve got a choice?”
“Oh yes.” Dumbledore smiled at him. “We are in King’s Cross, you say? I think that if you decided not to go back, you would be able to … let’s say … board a train.”
“And where would it take me?”
“On,” said Dumbledore simply.
Silence again.
“Voldemort’s got the Elder Wand.”
“True. Voldemort has the Elder Wand.”
“But you want me to go back?”
“I think,” said Dumbledore, “that if you choose to return, there is a chance that he may be finished for good. I cannot promise it. But I know this, Harry, that you have less to fear from returning here than he does.”
Harry glanced again at the raw-looking thing that trembled and choked in the shadow beneath the distant chair.
“Do not pity the dead, Harry. Pity the living, and, above all, those who live without love. By returning, you may ensure that fewer souls are maimed, fewer families are torn apart. If that seems to you a worthy goal, then we say good-bye for the present.”
“Of course it is happening inside your head, Harry, but why on earth should that mean that it is not real?”
]]>