总结一下二分图匹配的几种算法
定义
把图的顶点分为不相交集合U和V,不存在连接U或V内部点的边,这样的图成为二分图(bipartite graph)。
二分图有一些性质,如二分图中不存在奇数条边的环(奇圈),因为环必须首尾相接的,奇数条边必定会使首和尾分处于U和V中。如果我们对二分图进行DFS,那么每一次都是从U到V或者从V到U,这个性质可以被用来判断是否是二分图(DFS到vis[next]和自己的vis[cur]相等就说明不是)。
匹配是对于边而言的,表示在所有的边中,任意两条边都没有公共顶点。如果一个图中的所有顶点都能够构成匹配,则称这个图存在完美匹配,否则这个图只存在最大匹配,含有尽可能多的匹配边数。
一个点被当前匹配饱和指这个点在当前匹配的某个边上。
匈牙利算法
算法介绍
匈牙利算法试图优化当前的匹配,得到边数+1的匹配。构造的方式是从一个非饱和点(也称为非匹配点,saturated vertex)开始,依次通过非匹配边、匹配边、非匹配边…(这样非匹配边和匹配边交替形成的路径叫做交替路)。容易发现这样的路径总结束于一个到非饱和点的非匹配边,因为到达于一个匹配点,如果轮到走该点关联的那条匹配边,这样要么走完完美匹配,要么到达另一个匹配点。如果轮到走非匹配边,则可能到达一个匹配点(回到上个情况),也可能到达一个非饱和点,但是非饱和点肯定是不能继续走匹配边形成更长的交替路的,于是结束。可以发现,这样走下来非匹配边始终比匹配边多一条,并且除了一头一尾的两个节点,中间节点全部是匹配点,如果反向匹配边和非匹配边,就能够得到边数+1的匹配。因此把这条起点和终点未饱和的交替路称为增广路。可以发现这样的增广路中每个点至多出现一次,因此反向匹配边和非匹配边后不会出现一个点有两个匹配边连接的情况,并且增广路的长度总是奇数,并且总是起于二分图的一端,终于二分图的另一端。根据berge定理,如果图G中不存在对匹配M的增广路,那么该匹配M是最大匹配。
算法实现
在实现匈牙利算法时,并不需要显式地去建立交替路,交替路的扩展和反转通过dfs(或者bfs)隐式地表现出来。这样的算法复杂度O(EV),经过优化的Hopcroft-Karp算法复杂度可达到O(E*sqrt(V))。
首先实现寻找增广路径的算法。从节点U(大写表示二分图左部)进行dfs寻找从U开始的增广路(因为从U开始,所以U必然要是非饱和点)。对于U的所有出边(U, v),假如v是非饱和点,那么可以直接匹配U和v,显然匹配数会增加1。假如v已经和W匹配,但是能够为W在右部找到另一个匹配点x,那么就将U和v匹配。即对于这一种情况,匹配数同样是增加1的,假设原先(W, v)是匹配的,如果现在匹配U和v,则W失去匹配,匹配数并没有增加,但是如果能够找到另一个x能够和W匹配,那匹配数增加1,当然这个过程是递归的(因此匈牙利算法寻找增广路使用dfs实现),x和W匹配同样可能导致x的原配失配,因此这个算法的返回值是个表示是否存在增广路的布尔量,如果在递归的末端存在x的匹配Y不能找到新的匹配,也就是不存在从x开始的增广路,那么也不存在从v开始的增广路。对于其他情况就不存在从U开始的增广路。
因此整个算法可以枚举二分图左边的点x,寻找是否存在增广路,从而得到匹配。在实现算法的时候需要注意对于有向图邻接矩阵不能设置m[dest][src]。
下表给出了一个匈牙利算法的实例,其中红色点表示已经匹配了的点。增广路搜索始终从左端开始,因此从左侧到右侧是搜索的是不在当前匹配M中的边,从右侧到左侧是在当前匹配M中的边
| 初始情况 | 寻找增广路 | 新的匹配 |
|---|---|---|
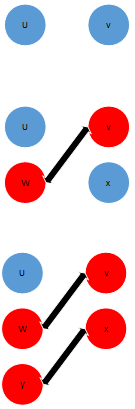 |
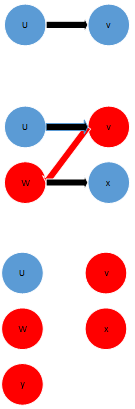 |
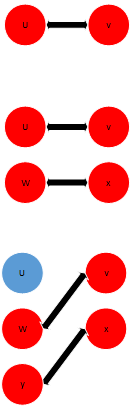 |
例题 HDU2063
Hopcroft-Karp算法
算法介绍
匈牙利算法使用dfs寻找增广路,Hopcroft-Karp算法作为改进使用bfs寻找增广路,bfs相对dfs的优势是找到的增广路永远是最短的。因此Hopcroft-Karp每轮按层搜索多条无公共顶点的增广路并全部替换。
算法流程如下:
- 将所有未饱和的左侧顶点作为第0层
- 对于偶数层顶点,通过不在当前匹配中的边寻找
对于奇数层顶点,通过在当前匹配中的边寻找 - 当发现未饱和右部顶点,或搜完全部顶点,bfs终止
- 如果搜到未饱和的右侧顶点,进行反向dfs,搜索回第一层的某个点,这样形成一条增广路。将这条增广路加入匹配,并临时删除这条路上的点和边。重复此步操作直到无法到达第0层。重新开始bfs。
算法实现
Edmonds算法
以上两种算法只可以在二分图上使用,这是因为二分图不会包含奇圈。
学习资料
- Wikipedia
- 南京大学程龚讲义

