因为《并发编程重要概念及比较》文章过长,所以将其中无锁队列部分拆出来。
常见的用CAS实现的Lockfree算法例如并发缓冲队列,我们可以抽象成维护一个链表。
下面介绍几个经典实现,可以注意观察:
- 如何减少 CAS 操作数量
- 如何 GC
有锁链表——使用一把大锁
有锁链表——每个节点一把锁
Valois 无锁队列
首先对于一读一写的模型我们可以仅通过约束读指针和写指针的行为即可实现,并不需要接触并发模型。
下面主要考虑多对多的模型,以 Valois 的论文Implementing Lock-Free Queues中的论述为例。
1 | Initialize(){ |
在 Enqueue 中,需要维护 p 和 tail 两个变量。
1 | Enqueue(x) { |
【Q】这里有一个疑问,就是为什么2这句不使用循环保护起来,以确保成功呢?这是因为这个语句是始终能够成功的。我们考虑:
- 线程 T1 成功进行了 1 处的 CAS,它使得
tail->next不为NULL - 线程 T2 执行到 1,那么它的 CAS 一定是失败的
这是因为 tail 还是老的值,没来得及被 T1 更新,但是tail->next已经被线程 T1 更新过,不是NULL而是q了。这个过程一直到语句2之后tail被成功更新成q。
因此实际上可以把tail->next看成一个锁一样的东西。
不过,可以发现一个违背锁无关性质的问题,也就是当线程 T1 在执行语句2时挂掉了,那就会阻塞所有其他在循环中的线程,因为 tail 不会被更新了。其实这里可以想到一个优化,就是如果其他线程执行语句1失败了,仍然可以帮助 T1 更新完 tail。
深入思考一下,原因在于两个 CAS 操作1和2并不是原子的,所以可能出现某个线程执行了1,但没有执行2的中间状态。换句话说,这个版本中**p = tail 中的 tail并不一定是结尾。这也导致了为了维护离开循环时 p 必须指向结尾这个特性,线程需要在循环内自旋,从而导致上述的死锁现象的产生。进一步看,tail 和 next 真的都是必要的么?事实上,即使我不记录 tail,那么这个链表也是正确的**。
为了解决问题,索性放宽假设,认为 tail 只是“接近”结尾。现在需要使用一个内层的 while 循环(指3处的 while)来从 tail 开始尝试更新结尾,此时 tail 存在的目的是为了减少 next 的数量。因此提出下面的改良版,不过在此之前,需要再研究下 Dequeue 的实现。
下面是 Dequeue 的实现,需要额外考虑两种情况下和 Enqueue 会不会产生冲突:
- 链表中只有一个元素
那么head和tail指向的就会是同一个节点。为了解决这个问题,增加一个 dummy 节点作为head,并且每次弹出head->next而不是head。
这样,**Enqueue 的时候不需要访问head,Dequeue 的时候,不需要访问tail**。MS 队列中指出,这样的好处是可以避免潜在的死锁问题。 - 链表为空
此时,head和tail应当指向同一个节点,但这种实现有可能会破坏这个性质。考虑下面的图,假设 T1 在做Dequeue,正准备执行位于1处的判断。此时 T2 正在执行 Enqueue 插入节点A,并且刚执行完1处的 CAS,此时p->next不为 NULL 了。回归到 T1,此时1处的判断不成立,Dequeue就会把Enqueue新生成的节点取走。而等线程切换回来,T1 还在傻傻地设置tail。Scott 等人的论文中提到,这种方案会阻碍对 Dequeued 节点的释放。
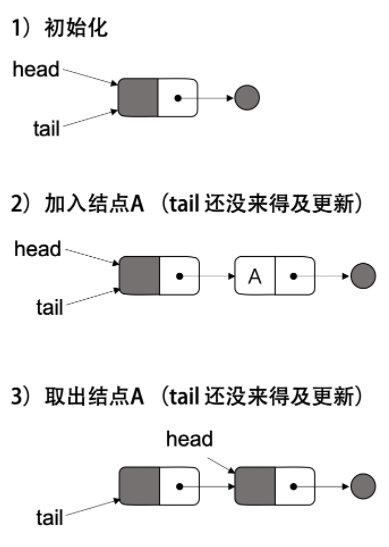
1 | DeQueue() { |
改良版1
改良版中不再记录 tail 的值,而是用一个内部循环不断地 p->next 找 tail
1 | EnQueue(x) |
观察改良版代码,即使 T1 线程挂在语句2,没能更新完 tail 指针,线程T2也可以自动跟踪到T1在1处的修改。
注意此时语句2可能失败,但这说明此时它应该失败。考虑下面的执行顺序:
- 原先链表中只有一个元素1
- 此时线程T1添加了一个元素2,并且成功执行语句1,将
p指向了元素2的位置 - 此时发生了调度,线程T2获得处理器,它需要在队列中加一个元素3
T2 在刚进入循环时它发现自己的tail是指向1的,这是因为此时 T1 还没有更新tail指针。
但 T2 在内层的while循环中根据p的next指针走到了刚被T1添加进去的元素2处。因此T2在元素2的末尾增加了元素3,并且更新自己的p指向元素3。
T2 继续执行语句2,此时tail == oldp指向元素1,所以 CAS 成功,tail指向了元素3。
现在,T1 重新获得了处理器,此时tail已经被 T2 修改到指向元素3了,于是不能匹配oldp,这个 CAS 就会失败,因为它试图更新一个较旧的值。
容易看到这个失败不会影响tail指向精确的队列结尾。但是如果稍稍修改下上面的运行顺序,按照
1 | T1 T2 |
来执行,那会发现 tail 被更新到指向元素2而不是元素3。所以看到先前放宽的假设是非常有必要的,在论文中作者指出这种情况下tail指针距离列表的准确结束位置最多相差2 * p - 1个节点。其实这个“最多”还是有点多的,所以在实践中我们常常结合两种方案来使用。
Michael 和 Scott队列
Michael 和 Scott在1996年提出了另一种无锁队列的实现方法。在论文里还介绍了有锁实现,我们暂时不讨论。
在指针 pointer_t 中引入了一个 count,也就是论文中提到的 modification count,其作用是解决 ABA 问题。
给定一个 p: pointer_t,则 p.ptr->next 表示后继,是个 pointer_t 对象。
和 Valois 的算法一样,MS 队列的 Head 指针同样是一个 dummy 节点。 Tail 指针指向的是倒数第一个或者倒数第二个节点。
为了允许出队函数释放被弹出的 node,我们需要保证 Tail 并不指向被弹出的节点,或者任何它的前驱 node。因此我们甚至可以安全地重新使用这些节点
1 | structure pointer_t {ptr: pointer to node_t, count: unsigned integer} |
插入的过程主要是:
- 不断重复,直到 Enqueue 成功
- 记录当前队尾
Q->Tail到 tail - 记录 tail 的后继对应的
pointer_t到 next - E7 判断此时记录的 tail 是否还是队尾
如果不是,则下一轮循环。 - E8 判断此时
tail.ptr–>next指向的 node_t 为 NULL- 如果是,说明此时 tail 还是队尾
E9 尝试将队尾改为<node, next.count+1>。
E9的CAS要成功,则tail.ptr–>next==next==NULL。 - 如果不是,说明 tail 不是队尾了
此时 tail 指向倒数第二个 node。
E13 我们更新一下Q->tail,指向tail.ptr–>next。
- 如果是,说明此时 tail 还是队尾
- 记录当前队尾
- Enqueue 完成
E17 将Q->Tail修改为<node, tail.count+1>。
1 | enqueue(Q: pointer to queue_t, value: data type) |
需要注意这里的 free 不是简单的 delete,如果简单 delete,会 use after free。
事实上,无锁算法中,GC 是一个难点。它在于当线程释放了一块内存时,是无法获知是否有别的线程也同时持有该块内存的指针并需要访问。所以 MS 队列的作者之一就提出了 HazardPointer 的思路。
1 | dequeue(Q: pointer to queue_t, pvalue: pointer to data type): boolean |
Safety
我们要证明下面的性质始终成立:
- 链表始终是连接上的
- 新节点只插入到最后一个节点后面
- 节点只在链表头删除
- Head 始终指向链表头
- Tail 始终指向链表中的某个节点
证明:
首先,在一开始所有的性质都成立。那么假设 ABA 不发生,则:
- 一个节点不会被设置为 NULL,除非它被释放。而只有当节点从链表头被删除之后,才会被释放【性质3】。
- 通过 Tail 始终能找到链表中的某个节点【性质5】,新的节点只会插入到 next 为 NULL 的节点后面,也就是链表的最后一个节点【性质1】。
- 因为只通过 Head 删除,但 Head 始终指向链表头【性质4】。
- Head 的值只会在一种情况下变化,也就是在删除时,原子地切换到 next 上。Head 不可能为 NULL,因为如果队列中只有一个元素,dequeue 会直接返回。
- Tail 永远不会落后于 Head,所以它不会指向一个被删除了的节点。并且,Tail 只会在 next 不为 NULL 时,切换到 next。
Liveness
我们将证明上面这个算法是Non-Blocking的,主要思路是证明如果循环判断条件触发了超过一次,那么必然有另外一个进程完成了操作,那么整体来说,整个算法就是一直在往前运行的。
首先考虑Enqueue情况:
- E7
如果E7不满足,说明在E5后,Tail被另一个进程修改了。Tail永远指向最后一个,或者倒数第二个节点。所以如果E7失败超过1次,那么另一个进程一定成功完成了一次Enqueue。 - E8
如果E8失败,说明Tail此时正指向倒数第二个节点。那么在E13的CAS后,Tail就会指向链表中最后一个节点,除非另一个进程又Enqueue了一个。因此,如果E8又失败了一次,说明另一个进程一定成功完成了一次Enqueue。 - E9
E9 处的 CAS 失败,说明一个进程成功Enqueue了一个元素。
下面是Dequeue情况:
- D5/D13
如果D5的判断不满足,或者D13的CAS失败了,说明Head被另一个线程修改过了,而Head只有在被成功Dequeue(E13)的时候才会被修改。 - D6
如果D6满足,并且此时链表是不空的,说明此时Tail正指向倒数第二个节点,也就是正数第一个节点。
那么在D10的CAS之后,Tail一定指向最后一个节点了,除非此时又有一个进程完成一次Enqueue操作。
所以,如果D6的条件满足了多于1次,那么另一个进程一定Enqueue成功,并且同一个或者另一个进程又Dequeue了一个item

