在本篇中比较了各种并发、并行技术。
并发(concurrency) 强调的是逻辑上的同时发生,是语义上的模型(semantic model)。如果只有一个处理器,那么并发程序是 interleave 执行的。并发通常可划分为多个级别:Blocking、Obstruction-Free、Lock-Free、Wait-Free,其中后三种统称为 Non-blocking 的。
并行(parallelism) 属于并发,是运行期的行为(runtime behavior),并行强调这两个并发事件实际上也是同时发生的,例如在多个处理器上运行的多个任务。但我们不能讲这两个概念绝对化,例如在处理器层面,流水线绝对是并发的,但在操作系统之上提供的机制来说,却体现出顺序的特性。
处理器层面的并发
处理器在硬件架构上可以被分为:
- 对称多处理器 (Symmetric Multiprocessing, SMP)
SMP 被广泛用于 PC 中,架构简单,但扩展性较差。 - 非均匀访问存储模型 (Non-Uniform Memory Access, NUMA)
- Massive Parallel Processing(MPP)
这里简单地论述处理器层面的并发相关,例如流水线、分支预测、多级缓存等技术。
流水线(pipeline)
流水线和吞吐量
通常使用每秒千兆次操作,即 GOPS 定义吞吐量,表示每秒内执行操作的次数。CPU 流水线的目的是为了提高吞吐量(throughput),但会增加每条指令的延迟(latency),这是因为执行一条指令需要经过更多的流水线寄存器。
CSAPP 使用一个称为 SEQ 的架构来描述流水线的通用模型,一条指令在 CPU 中被执行会经过如下阶段:
- 取指 fetch
从 PC 处取得指令。指令包含 icode 和 ifun。还包含译码阶段需要读取的寄存器 rA 和 rB(可选的),一个常数 valC。 - 译码 decode
从寄存器读取。不妨把读到的数令为 valA 和 valB。 - 执行 execute
- 访存
读写内存。如果读内存,读到的值令为 valM。 - 写回
写回到寄存器。 - 更新PC
在 SEQ+ 中和取指进行了合并。
特别注意,处理器可以读写寄存器和内存,读写寄存器和读写内存是不同的阶段。
容易想到在某一时钟周期内,每一个阶段都可以独立运行。例如当指令 PC 在执行阶段时,就可以对指令 PC+1 进行译码,这样译码器就不会闲置。这种流水线设计很常见,以 486 为例,其拥有一条 5 级流水线 取指F->译码D1->转址D2->执行EX->写回WB。
出于两点的考虑,流水线技术会制约了吞吐量能提高的上限:
- 流水线不同阶段的延迟是不同
如下图所示,流水线的吞吐量会受到其中最长操作的局限。
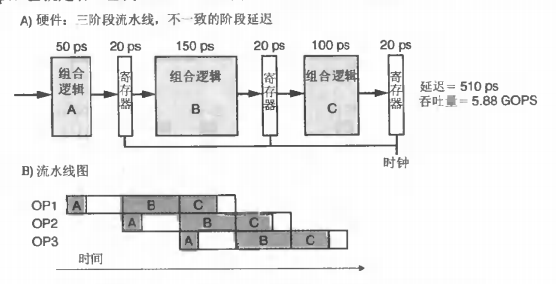
- 一个较深的流水线可能带来很大的流水线寄存器延迟
这是来自于增加的流水线寄存器所带来的额外开销。
流水线和冒险
流水线并发执行一些指令需要面临的问题:
- 顺序(数据)相关
后一条指令的执行依赖于前一条指令的值 - 控制相关
指令流的路径依赖于前一条指令(通常是条件测试)的结果
为了解决这样的问题,CSAPP首先升级了原先的SEQ到SEQ+,现在将更新PC移到最前面,并且和取指进行了合并,这样做的目的是在程序开始时通过上面一条指令结束时的状态来确定地址。CSAPP基于SEQ+引入了PIPE-这个流水线,并希望PIPE-能够实现每个时钟周期发射(issue)一条指令,因此我们需要在取出一条指令后马上确定下一条指令的位置。这对于ret和条件转移来说是较为麻烦的,因为要进行分支预测。
分支预测有一些策略:
- 总是选择
- 从不选择 Not Taken
- 正向不选择(BTFNT)
Backward Taken:只接受跳往地址更低的分支。简单来说,就是往之前的代码跳,因为它可能标志着一个循环的右大括号。
Forward Not Taken : 当目的地址比当前地址大时,通常是条件不成立时的代码块,预测不执行跳转 Not Taken。
现在的分支预测器通常分为静态规则和动态规则的.动态规则会基于一些运行期的历史进行类似“强化学习”,例如一段分支历史上不进行跳转的成功率大,那么就这一次预测的时候就不进行跳转,知乎专栏上给出了一个例子来验证这个特性,它的现象是:对一个有序数组遍历时其耗时约为无序数组的1/3。
- 分支预测失败,也就是**控制冒险(control hazard)**,它的代价是就会导致流水线刷新(flush)。
- 当一条指令写后面指令会读到的那些程序状态时就会带来数据冒险(data hazard)
特别地我们可以发现控制冒险可以看做是对程序计数器PC而言的数据冒险。
考虑整个流水线中可能出现的部件,其中通用寄存器和 PC 已经被证明是存在冒险的。以通用寄存器为例,其写和读发生在流水线上不同的阶段(写回和解码)。剩下来的是 EFLAGS 以及存储器则是不存在冒险的,以存储器为例,其读写都发生在流水线的访存阶段,那么前一条指令对存储器的写对后一条指令对存储器的读总是可见的。
CPU流水线中通过暂停(stalling)和转发(forward)/旁路(bypassing)的机制解决数据冒险的问题。此外在汇编层面,我们可以使用条件传送而不是条件控制转移来避免分支预测出错的问题。
冒险导致错误的展示
暂停
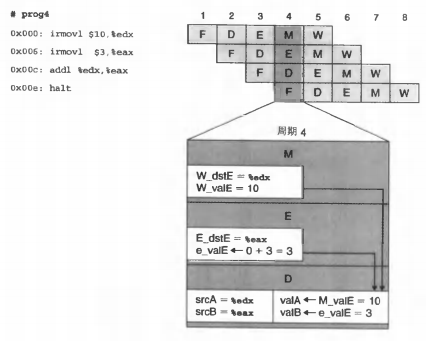
暂停的思路很简单,就是阻塞流水线中的一些指令直到冒险条件不满足。对通用寄存器而言,在解码阶段时流水线会检查前方执行、访存和写回阶段中是否有指令会更新该通用寄存器。如果存在那么就会阻塞处于解码阶段的指令(包括后面即将执行的下一条指令的取指阶段,也就是保持PC的值)。在阻塞时,流水线的一部分会进入空转状态,称为插入一个气泡(bubble)。如下图所示,在时刻5,原本应该执行的 0x00d 处的 D 被阻塞了,因为 0x006 处的 W 尚未完成。因此在等待其完成的时间中插入了三个气泡,分别对应 EMW 阶段。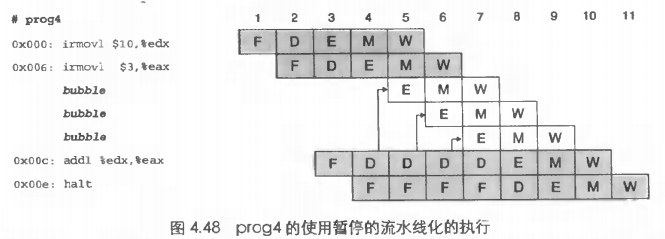
转发
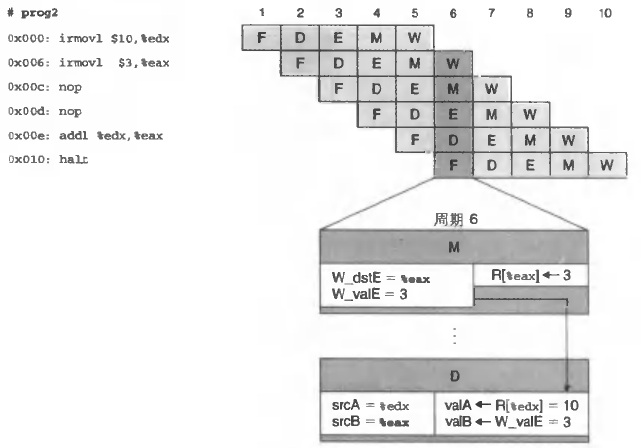
上面的暂停机制非常直白和简单,但考虑到前后连续两条指令对同一个寄存器先写后读是很通常的情况,此时三个气泡是很划不来的。此时可以借助转发来避免暂停。转发机制指将结果从流水线的较晚阶段发送到流水线的较早阶段的过程,通常是从写回阶段W转发到译码D阶段作为操作数之一。
- 【写回–译码】
查看下面的图,在第6周期上,0x00e的解码逻辑发现0x006上所在的写回阶段有对%eax的写,而自己恰恰要访问%eax,所以与其这样不如直接拿过来用了。这样相当于只插入了两个气泡。
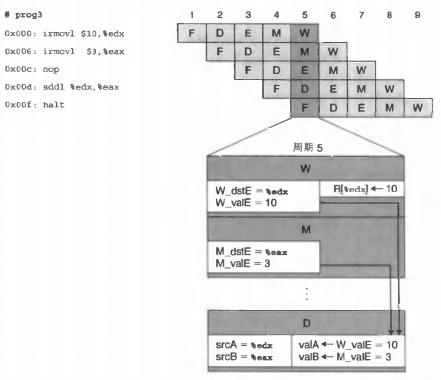
- 【访存–译码】
更厉害的是我们甚至可以在访存阶段就转发到解码阶段。查看下面的图,在第5周期上位于解码阶段的0x00d发现0x006和0x000分别处于访存和写回阶段,这里写回阶段如上所示,而访存阶段我们发现正在读入数据到%eax。因此可以直接将这个对%eax的写也转发过去。现在相当于只插入了一个气泡。
- 【执行–译码】
能不能一个都不插入呢?也是可以的,我们从执行阶段就转发到解码阶段。查看下面的图,在第4周期上位于解码阶段的0x00c发现0x006和0x000分别处于执行和访存阶段,这里访存阶段如上所示,而在执行阶段我们发现正在计算一个立即数,这个立即数将在稍后写入%eax。
加载互锁
转发能够解决相当多的数据冒险,但有一类加载/使用冒险(load/use hazard)难以被解决,这是因为加载(从存储器读)存在于访存阶段,而如果下一条指令就要使用的话,那么就会“赶不上趟”。
如下所示,mrmovl 试图从内存中读出 %eax,而 0x01e 就要将 %eax 的值作为源操作数了。因为 mrmovl 在访存阶段才能读完,而 addl 在译码阶段就要读出寄存器的值了,显然来不及。
1 | 0x018: mrmovl 0(%edx),%eax |
对于这种情况,可以在两个命令之间插入一个气泡。
现代处理器
在现代的处理器中,流水线被拆分地更加细,出现了所谓的12级、31级乃至更深的流水线。但是这么深的流水线阻塞的代价是非常巨大的。为此 Intel 使用了乱序执行组件(Out-of-Order core)。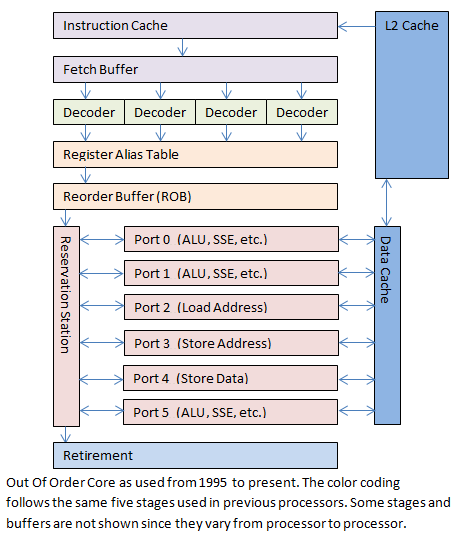
流水线机制对程序优化的启示
流水线机制对我们程序性能优化的启示主要有下面几点:
- 减少连续指令的相关性
这一点是针对数据冒险而言的。 - 进行循环展开
这一点是针对控制冒险而言的。循环处必然出现分支,这就带来了可能的分支预测失败的成本。通过展开循环能够减少这样的跳转次数。 - 减少过程调用
- 取出不必要的存储器引用
combine 函数的初步优化
- combine2
在循环结束条件中去掉strlen函数 - combine3
去掉每次的边界检查。但收益一般,原因是分支预测机制。 - combine4
引入一个临时变量acc来记录
依赖于目标机器微体系结构的优化
下面是依赖于目标机器微体系结构的优化。相比于刚提到的 in-order 流水线,诸如 Core i7 架构下支持在一个时钟周期内乱序执行多个操作,即所谓的超标量(superscalar)。i7 的体系结构分为两个单元,指令控制单元 ICU 和执行单元EU。
ICU 负责取指,这个取指操作往往很超前,这样 ICU 才有足够时间进行译码,并发送给 EU 执行。
CPU 的缓存
现代CPU中寄存器与内存之间没有直接的渠道,而必须通过多级的高速缓存才能到内存。高速缓存的作用依然是为了弥补CPU和内存在速度上的差异,高速缓存提高效率的原理是基于**时间局部性(Temporal Locality)和空间局部性(Spatial Locality)**,将在稍后讨论。高速缓存基于静态RAM(SRAM)技术,区别于主存的动态RAM(DRAM)技术。
虽然高速缓存对用户来说是透明的,汇编要不直接操作寄存器,要不直接操作内存,但它并不是不存在。从实现角度来看内存和对应CPU缓存的同步是个问题,但这问题在一定程度上对用户是透明的,比如我们不要担心“一个核心写另一个核心脏读”之类的情况,缓存一致性协议能够解决内存和多核CPU缓存之间以及缓存与缓存之间的同步的正确性问题。
我们仍然要关注缓存这个概念,以写出高质量的程序。
访存速度
先前,介绍了常见的 CPU 指令的耗时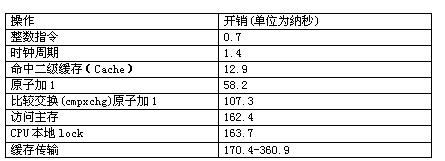
对于访存而言:
- L1: 1–4 cycles(几 ns)
- L2: 5–20 cycles
- L3: 20–100 cycles
- DRAM: 50–200 ns(几十到百余 cycles)
- SSD: 10⁴–10⁶ ns(微秒到毫秒级)
x86的缓存架构简介
局部性原理
- 时间局部性
如果被访问过的存储器地址在较短时间内被再次访问,则程序具有良好的时间局部性。
在一定的时间内,重复访问同一个地址的次数越多,时间局部性越好。换句话说,对同一个地址的两次访问间隔时间越短,时间局部性越好。 - 空间局部性
如果程序访问某个存储器地址后,又在较短时间内访问临近的存储器地址,则程序具有良好的空间局部性。
两次访问的地址越接近,空间局部性越好。
以控制时间局部性的变量为x轴,控制空间局部性的变量为y轴,存储器访问速率为z轴,就能得到一个三维图形,它看起来像一座有着山峰,山脊和山坡的小山,即存储器山。可以构造下面这个循环来生成存储器山图:
1 | Kernel_loop(elems, stride): |
- 参数 stride 表示访问时的步长,即相邻两次访问的元素的地址间隔,是空间局部性的控制。
- 参数 elems 表示 data 数组的尺寸,是时间局部性的控制。解释一下,这是因为当 stride 固定时,elems 越小,也就是数组长度越小,遍历一次的时间就更快,从而对相同地址的两次访问间隔(预热和真正访问)就越短。
这里的 elems 也就是图里的 size。
一般来说 stride 越小,空间局部性越好;size 越小,时间局部性越好。
空间局部性在对二维数组的访问上会更加明显,例如对于行存储的模型,如果以列为单位遍历,那么就会破坏空间局部性。
展示存储器山
下图展示了 i7 的存储器山。它具有 32kb 的 L1 缓存,256KB 的 L2 缓存和 8MB 的 L3 缓存。
从 size 看出:
- 由于 CPU 通常有多级缓存,所以一般存储器山会沿着 size 分为若干个台阶,分别对应使用内存、L3、L2、L1 缓存的情况。
从 stride 看出:
- 主存山脊的最高点是最低点的 7 倍还多。这意味着在时间局部性很差的情况下,当 stride 变大,性能会急速变差
这说明空间局部性是非常重要的。
联合看出:
- 当 size 小于 32k 之后,在 stride 很大时,山脊会明显往下折。这是因为循环只需要执行一次就结束,所以大部分时间都被用在处理迭代之间的事务了。
- 当步长为1和2时,山脊线平行于 size 轴。也就是说,无论 size 有多大,吞吐量始终是 4.5GB。这是因为 i7 的 prefetching 机制。也就是说它能够在块被访问前,就将对应的数据从内存取到高速缓存中。所以即使 size 太大放不下,通过这个机制仍然可以“提前把高速缓存换好”。
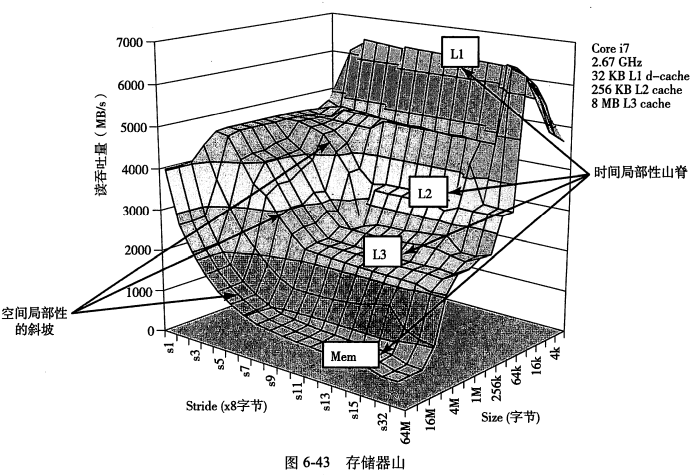
stride 为 16 时的切面。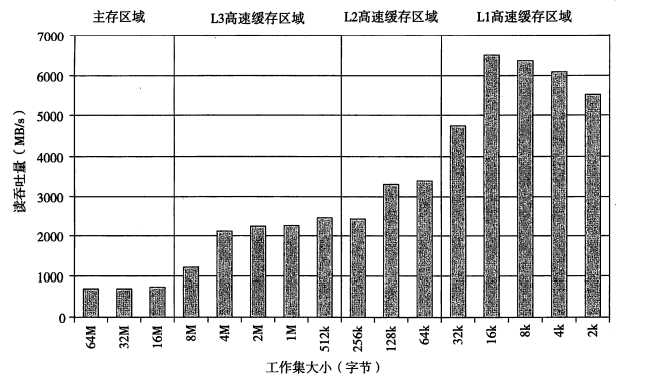
size 为 4 时的切面。右边完全水平是因为每次读取都不会命中L2,需要从L3重新读取。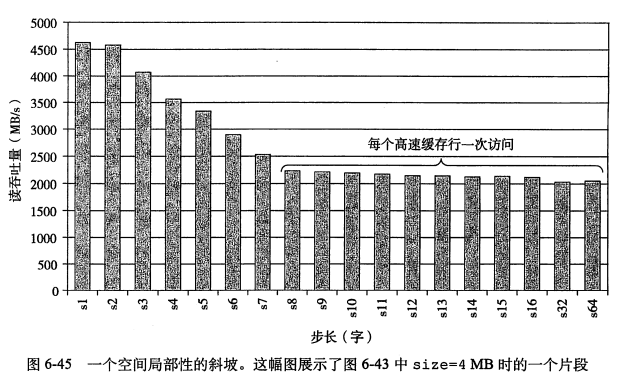
计算存储器山
在GitHub上可以找到类似的程序。
Demo:向量求和
时间局部性:被引用过一次的存储器位置很可能在不远的将来再次被引用
空间局部性:存储器中的某一个地址被引用过,那么它附近的地址很可能也会被使用
考虑对一个向量求和
1 | int s = 0; |
- 对于标量
s
它并没有空间局部性一说,但是它在每次循环中都被访问,因此具有较好的时间局部性。 - 对于向量
v是被逐一访问的,即具有步长为1的引用模式,因此空间局部性很好,不过用一次就不用了,所以时间局部性不好。
这个在我CFortranTranslator工程的设计上曾有所考虑。
Demo:矩阵相乘
考虑矩阵C=AB,其计算方法为$C_{ij}=A{ik}*B{kj}$。但有6种方法来组织这三层的循环(说到这个推荐一下MIT18.06的线代课)。因为考虑局部性是看最内层循环的操作,所以我们根据最内层操作的元素分为三类:
- ijk/jik(AB类)
直接算出Cij的最终结果。 - jki/kji(AC类)
相当于左边矩阵的每一列Ai,乘上右边矩阵对应的行r,得到n个矩阵再加起来。
这里看最内层循环扫过的坐标就能分辨出来是哪种。 - kij/ikj(BC类)
相当于右边矩阵的每一行Bj,乘上左边矩阵的每一列r,得到n个矩阵再加起来。
假设程序在下面的环境上运行:
- 每个元素sizeof(double) = 8个字节
- 只有一个块大小(B)为32字节的缓存,能存4个double
- n很大,无法装到L1
- 局部变量放寄存器
- 数组以C-style存储
可以得到下面的分析。对于AB,内循环对A的扫描的步长是1,因为高速缓存一次只能存4个double,所以内循环每迭代4次就要加载一次,我们计算 miss 次数是0.25。同理,内循环对 B 的扫描步长是n,因为n很大,所以可以认为每次都不命中。特别地,对于BC和AC类,因为有C[i][j] += 这样的操作,所以内循环中除了两次加载之外,还需要一次存储。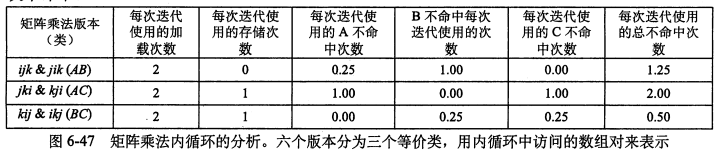
下图是实验结果,y轴表示每次内循环迭代需要的 cpu 周期,曲线越往下说明越快,即BC类最快。可以看出:
- 当 n 很大时,运行速度和外循环的关系并不大。运行速度慢的版本具有更高的 miss 率。
- 类BC比类AB在内循环中会多引用一次内存,但因为它的 miss 率更低,所以性能更好。
- 当 n 逐渐增大时,类BC的性能并没有受到什么影响。这说明我们的存储硬件能对步长为1的访问模式进行很有效的优化。
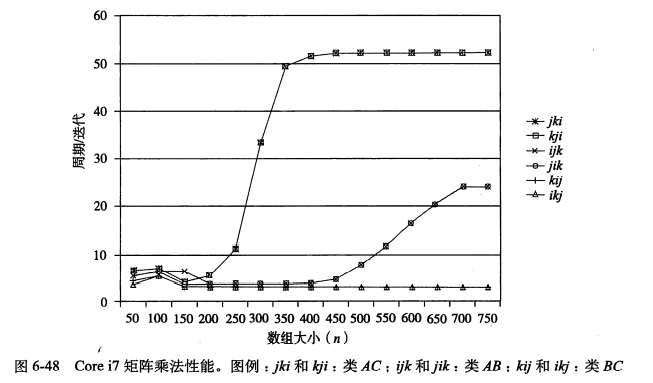
【Q】三个类最右边的平台有什么特别的意义么?
缓存抖动(thrash)
下面的代码局部空间性看上去很好,但如果x和y都被映射到一个高速缓存组中,就会造成**缓存抖动(thrash)**。
1 | for(int i = 0; i < 8; i++){ |
在后面的“伪共享”章节会详细探讨这种情况。
缓存不命中(cache miss)
往下深究局部性原理,自然想到缓存不命中的问题。我们肯定是希望能在当前缓存找到需要的对象,这样最快。但缓存的容量总是有限的:当缓存不能命中时,我们就需要从下一级缓存中找。
缓存不命中的几个case
- 冷不命中/强制不命中
当系统开始运行时缓存是空的,如果缓存是空的,那命中个啥 - 冲突不命中(conflict miss)
例如我们mod 4一下到四个桶里面。那么假如从k+1层交替访问0号和8号块,缓存会一直不命中,即使其他的块还是空的。 - 容量不命中(capacity miss)
有的时候缓存就是太小了。
高速缓存的架构
下面考虑如何从缓存中找呢?总不能说也有个现成的哈希表甚至红黑树来维护吧?实际上,我们是快速根据地址来定位和映射Cache。
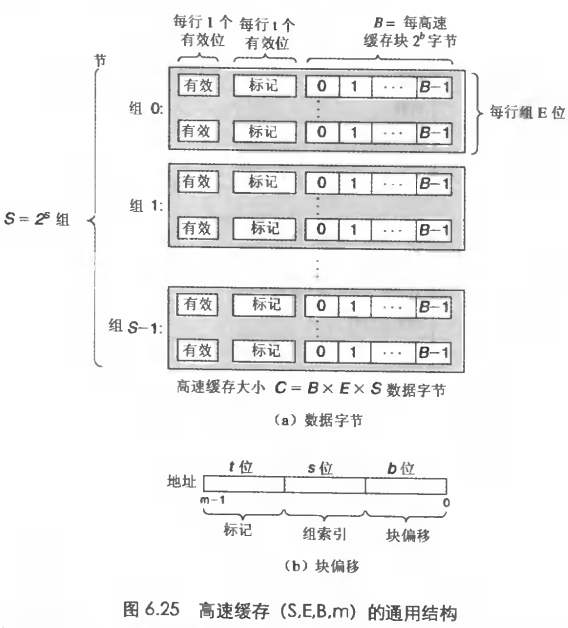
高速缓存一般分为cache set/cache line/block的三层结构。假如地址长度为 m,即总共有 M=2^m 个地址。将地址 m 分为三段,即组索引位 s、行标记位 t 和偏移位 b,分别用于在cache set/cache line/block的三层结构上进行索引。
这会产生几个问题:
- s、b、t大小如何指定?
高速缓存具有 $S=2^s$ 个 cache set,E 个 cache line,每个 cache line 包含 $B=2^b$ 字节的数据。因此一个高速缓存可以用(S,E,B,m)来描述。整个高速缓存的大小是S*E*B个字节。
这里的 cache line 是最特殊的,**需要注意 E 不等于$ 2^t $**,不然这缓存直接当主存用了。
s 和 b 的大小取决于要有多少个 S 和 B,然后t是由s和b决定的。假设地址长度为m,块偏移位数为b,剩下的t = m - s - b个 bit 就是标记位。 - s、b、t位置如何指定?
一般在地址的中间部分抽出s个位作为组索引位。这是为了利用空间局部性,如果使用高位做索引,那么连续的块因为空间局部性好,就会被映射到一个cache set里面,会导致缓存频繁刷新。
那么 t 就被安排在了高位,b 则在低位。这样相邻的块会被映射到不同的 cache set 上。 - 为什么要分成三个层?
由于一般高速缓存的容量要小,所以缓存在设计的时候会分成几个桶,每个桶对应一个 cache set。
每个 cache line 的构成是:
- 有效位
表示这个 cache line 是不是有效的 - 标记位
长度为 t,用来和地址里面的那 t 位进行比较 - 数据块
包含 B 个字节
根据指定的E不同,高速缓存分为了直接映射高速缓存、组相联高速缓存和全相联高速缓存。在后面会详细介绍。
通用架构
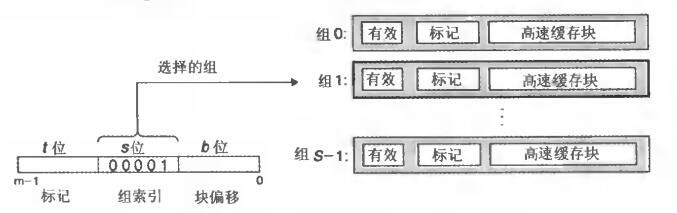
如下图所示,在高速缓存中查找时,在 m 中提出s、t、b,并哈希的方式逐层查找:
- 第一步用 s 做组选择,找到对应的 cache set
- 第二步用 t 做行匹配,找到对应的有效位被设置了的 cache line。
这是因为缓存可能会失效,这个对于只有一行的直接映射缓存来说的 trivial 的。
一旦找到匹配的t,就可以认为这个地址在缓存行中。
由于s占了中间位,所以t实际上就占了高位。 - 第三步用 b 来做字选择,也就是在 cache line 中根据偏移位
b找到具体的字。
直接映射高速缓存
直接映射(direct-mapped)高速缓存的 E 为 1。如下图所示,每个组中只有一行。
缓存根据是否命中会选择直接返回或者向下层请求对应块。
组相联高速缓存
直接映射高速缓存中每个组只有一行,也就是 E = 1。这是其冲突不命中造成问题的原因。组相联高速缓存放松了限制,允许一个组中有多个缓存行。
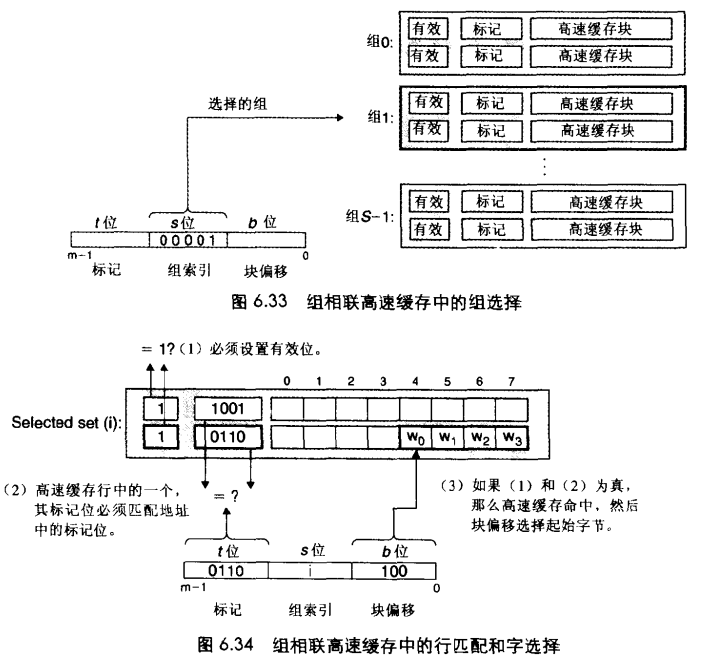
全相联高速缓存
这种模式下,只有一个组,也就是 E=C/B。
缓存污染
对于异常控制流,例如中断和上下文切换,缓存工作会受影响。此时主程序的缓存和中断处理的程序缓存会相互影响导致互相变cold。这种情况下当中断返回或者上下文切换回来时缓存需要较长时间来warm up,这种情况称为缓存污染(cache pollution)。
常见的缓存替换算法
在组相联高速缓存中,每个组中存在多个缓存行。如果当前的缓存满了的话,就需要去确定一个最合适的牺牲块(victim block)进行替换,常见的有LRU和LFU算法。LFU替换过去引用次数最少的行,LRU替换最后一次访问时间最久远的一行。
LFU:
- 需要额外的一些计算
- 当数据访问模式改变后LFU需要较长的时间重新进行适应(统计频率)
LRU:
- LRU的问题是当出现偶发性的批量操作时容易将Hot块(访问频率高的块)移出缓存,造成缓存污染
因此引入LRU-K算法,这个算法比较距当前第K次的访问时间和当前时间的距离来移出缓存。
一般来讲,LFU可以通过优先队列或者双层链表来实现。
测试缓存大小
根据知乎,方案是创建一个连续的内存块,进行连贯、大量、随机且有意义(防止被优化掉)的访问。在这种情况下,当内存块能够被整块放入 Cache 时,平均访问速度会显著的快。观察随着内存大小提高,平均访问时间的跃升点,即可估计Cache大小。
特别地,这样的测试构成了一个存储器山。
缓存一致性
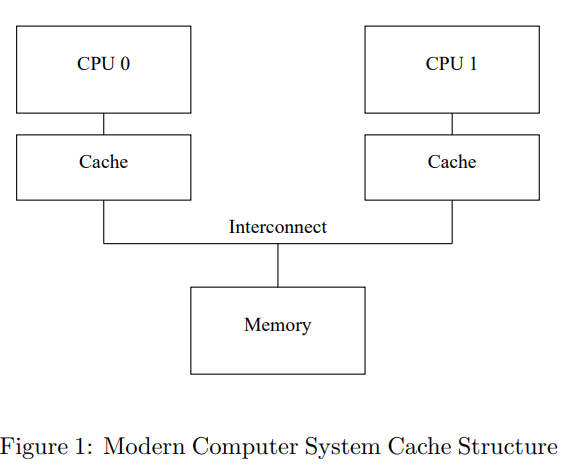
当多个核心同时读写一个内存地址时,如何保证其正确性?几种办法:
- 锁总线
- 缓存一致性协议
简单来说,就是大家都可以读写,但违反缓存一致性的结果会被扔掉。
总线锁
在较为古老的 CPU 上 LOCK 指令通常是锁总线的,后面有使用 Ringbus+MESI 协议的。
CPU 的缓存一致性协议
缓存一致性协议协调的对象是 CPU 的多个核心,MESI 是实现缓存一致性的一个基础协议。根据维基百科
MESI协议是一个基于失效的缓存一致性协议,是支持 write-back 缓存的最常用协议。与 write through 缓存相比,回写缓冲能节约大量带宽。总是有“脏”状态表示缓存中的数据与主存中不同。MESI 协议要求在缓存不命中且数据块在另一个缓存时,允许缓存到缓存的数据复制。与 MSI 协议相比,MESI 协议减少了主存的事务数量。这极大改善了性能。
MESI 分别表示缓存行可能处于的四个状态 Modified、Exclusive、Shared、Invalid。除此之外,Intel 使用了扩展的 MESIF,增加了状态 Forward。而 AMD 使用了 MOESI,增加了状态 Owned。CPU 的各个核心通过 ringbus 连接起来,每个核心维护自己的一致性。
状态的定义:
- S(hared) 状态,也就是共享状态。表示目前有多个缓存行缓存有该数据,并且缓存行中数据和内存中一样。
- E(xclusive) 状态,也就是独占状态。表示目前只有一个缓存行缓存有该数据。
- M(odified) 状态,表示该缓存行已经被修改。
- I(nvalid) 状态,表示缓存行失效。
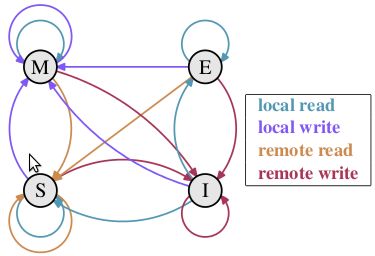
MESI 协议需要正确处理 local read(LR)、local write(LW)、remote read(RR)、remote write(RW) 四个场景,其中 local 表示本 core 对本地缓存读写,而 remote 则表示非本地 core 对非本地缓存的读写。
- 一个缓存行 Cache0 初始状态为 I,因为它并不缓存任何数据
- 当 Core0 向本地 Cache0 请求时,CPU 会通过 ringbus 发出 BusRd 信号向其他 Core 询问:
- 如果存在缓存行 Cache1 拥有该缓存,则将对应缓存行设为 S 状态。它会发出 FlushOpt 信号将缓存发送到总线。
- 否则从内存中加载到 Cache0,并设为 E 状态。
- 当本地处理器写入时,缓存行状态变为 M,此时缓存与主存之间的数据不一致,CPU 会发送 ringbus 信号 BusUpgr 通知所有对应的缓存行失效。其他 Core 收到后,会将状态设置为 I。
注意写操作仅在缓存行是 M 或 E 时可自由执行。如果在 S 状态,其他缓存都要先把该缓存行置为无效,这种广播操作称作 Request For Ownership。
特别地,在 I 状态也是可以写入的,此时会给 ringbus 发送 BusRdX 信号,表示 Core 要写一个自己缓存上没有的块。
在 S 状态的读也可以同时通过发送一个 Read Invalidate 消息作废其他 Core 上的 Cache,这一般发生在这个核很快需要做一次写入。
E 状态是个优化,因为修改 E 状态的缓存行不需要 ringbus 通信。
这个模型有点像读写锁的模式,读是 Shared,写会作废所有的缓存行。下图描述了四种读写下的状态变化。容易理解的是:
- 所有的 RW 都会导致 I
- 所有的 RR 都会导致 S
- 所有的 LW 都会导致 M
下面考虑 LR:
- 状态 E,由于是独占的,所以怎么读都是 E,因此是自环。
- 同理状态 M 也是独占的。
- S 状态虽然不是独占,但缓存行中数据和主存一致,因而是有效的,所以也是自环。
- I 状态,缓存行失效意味着有其他 core 的写导致了缓存行的刷新,所以进行 LR 之后实际上就和这些 core 进行了数据的同步,也就是回到了 S 状态。
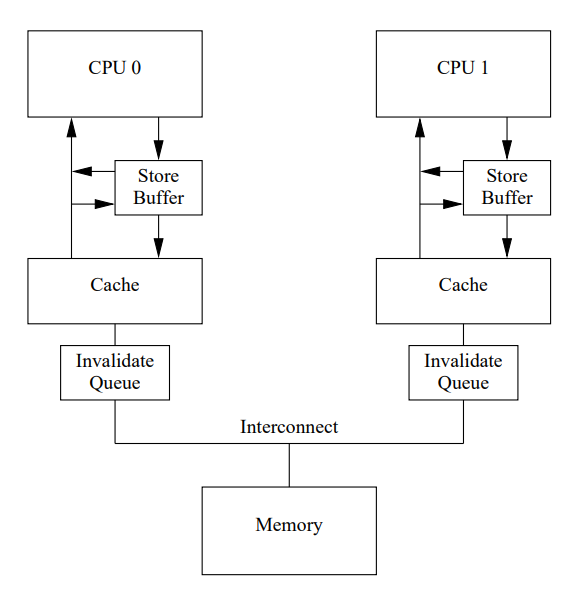
尽管 Figure 1 的架构能够使某个 Core 多次读写某些数据时的性能较好,但如果第一次写某个 Cache line 的性能很差。如下所示,Core0 需要写某个被 Core1 持有的缓存行。因为 Core0 必须要等待 Invalidate 消息被执行完毕,然后再返回。所以这会产生 Write stall。并且这个 Stall 相比寄存器操作是数量级的时间。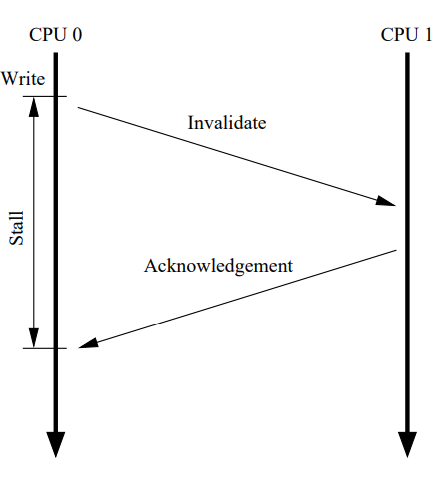
自然而然想到,能够避免 stall 的办法就是在 CPU 和 Cache 中间引入 Store Buffer,如下图 Figure 5 所示。Core0 可以直接写 Write Buffer,等到 Cache 从 Core1 回到 Core0 了,再从 Store Buffer 写到 Cache line。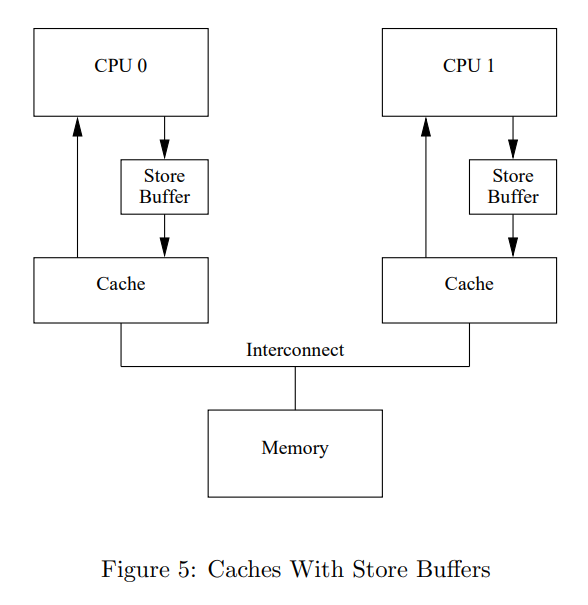
这种方案存在两个问题需要被解决。
第一个问题和 Store Buffer
第一个问题,考虑 a 和 b 开始都是 0,a 只在 Core 1,b 只在 Core 0。那么上面 Figure 5 的架构会导致 assert 失败。考虑:
- Core 0 执行 a = 1,它需要通过一个 Read Invalidate 消息从 Core 0 拿到 a 的缓存行,然后让 Core 0 变成 Invalidate。
- Core 1 在这中间可以处理完毕 Read Invalidate 消息,也就是返回自己的缓存行,然后再 Invalidate 掉。但问题在于 Core 0 可能还没有将 a = 1 从 Store Buffer 写到自己的 Cache line。而这就出问题了。
- Core 0 开始执行 b = a + 1。这个时候,因为 Core 1 已经返回了,所以它会从自己的 Cache 读到 a = 0。这样 b 算出来就是 1 了。
1 | a = 1; |
这里的问题是 Core 0 上有两份 a,一份在 Cache 里面,一份在 Store Buffer 里面,而自己的 Store Buffer 更新。对应的解法就是用下面的架构,Core 上的 load 在读 Cache 的同时也会读 Store Buffer。另一种说法就是 Core 上的 store 会被 forward 给后续的 load。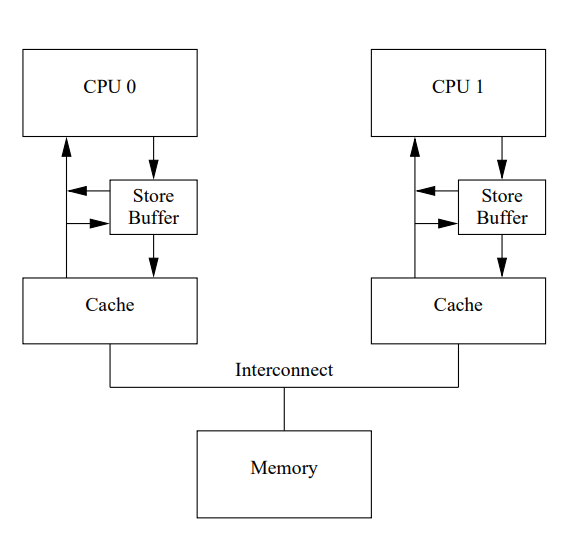
第二个问题和 Memory Barrier
第二个问题,同样考虑 a 和 b 开始都是 0,Core 0 执行 foo,Core 1 执行 bar。并且同样地,a 只在 Core 1,b 只在 Core 0。这个有点类似于我们后面的 Message Passing 这个 Litmus test。
1 | void foo(void) |
考虑:
- Core 0 首先执行 a = 1。它需要写入 Store Buffer,并发送一个 Read Invalidate 消息,让 Core 1 作废它的 Cache。注意此时 Read Invalidate 信息并没有像上一个 case 一样被 Core 1 处理和返回,所以还不能写 Cache。然后 Core 0 可以立即继续写 b = 1,因为 b 是它独占,所以它可以立即写入 b 到自己的 Cache。
- 然后,Core 1 执行 while (b == 0),它需要发送一个 Read 消息给 Core 0。Core 0 收到就会返回自己 Cache 中的 b 的值,也就是 1 给 Core 1。然后标记 b 对应的缓存行是 S 状态。
- Core 1 收到了 b = 1,就可以退出循环,到了 assert 语句了。因为此时 Core 1 还没有处理 a = 1 对应的 Read Invalidate 消息,所以 Store Buffer 还不能被 Core 0 写入到 Cache,所以 Core 1 读到的 a 是旧的值 0,assert 失败了。
- 后面,Core 1 才收到 Read Invalidate 的返回,并写 Store Buffer 到 Cache。
容易看出,这里的问题在于 Core 1 实际上要读到 Core 0 的 Store Buffer 才能保障一致性。这个问题并不能从硬件层面解决,因为 CPU 并不知道哪些变量是 related 的。为此,CPU 提供了 memory barrier,即 smp_mb 指令。
总之,smp_mb 做的工作是要求 Core 将 Store Buffer 中的东西先写到 Cache 中,然后再处理后续的 Store 操作。这个时候 Core 可以选择 Stall 住,直到 Store Buffer 清空。另一种办法是不写到 Cache 里面,而是写到 Store Buffer 里面,但是同样等到 Store Buffer 中前面的数据被写入到 Cache 中。
smp_mb
这里插一句嘴,再介绍下 smp_mb。这个指令通常是 mfence,如果硬件不支持则会翻译为 lock。根据 Linux-Kernel Memory Model 文档,可以通过 smp_mb 是使用 mfence 实现的。具体来说:
- Linux 4.14 使用 mb。mb 有可能就用 mfence,否则就用 lock addl。
__smp_store_mb(store + memory barrier) 用 xchg。 - Linux 4.15 直接使用 lock addl 了。
这里有说法是直接用 lock add 性能更好,SoF 上解释说 mfence 会 block 住 out-of-order 命令的执行,但 xchg 不会。
有人提到,在最新的架构中,mfence 能力更强一点。例如它可以 fence a subsequent non-temporal load from a WC(write combining)-type memory region
第三个问题和 Invalidation Queue
即使引入了 Store Buffer,仍然存在性能问题:
- 一定数量的 Store 会填满 Store Buffer,从而导致 Stall。
- Memory barrier 会导致 Store Buffer 中的 Store 必须阻塞等待 Invalidation。
解决方案是想办法让 Invalidation 消息来得更快,一个方案是对每一个 Core 引入一个 Invalidation Queue。它的思路还是将这些 Invalidation 消息暂存起来,延迟到必须读取之前再检查。
这里必须解释下为什么 Invalidation 需要这么长时间。这是因为某个 Cache 可能会很忙,比如它对应的 Core 正在疯狂读写自己。那么如果此时有大量的 Invalidate 消息压过来,那么这些消息肯定得不到及时处理。这里的优化点在于,一个繁忙的 Core 无法避免,但不应该阻塞其他 Core 的工作。所以它可以先把 Invalidate 消息存起来,保证自己后续的读之前会处理这些消息。这样它就不会阻塞其他 Core 了。
伪共享
伪共享(False Sharing)是在 MESI 模型下多个线程对同一缓存行竞争写所导致的性能降低。考虑这篇博文中的一个场景一个数组 int32_t arr[] 被同时加载到 CPU0 和 CPU1 的 L1 缓存 Cache0 和 Cache1 上。现在两个线程 A 和 B 试图分别修改 arr[0] 和 arr[1]。这种情况下是不存在 race condition 的,但是可能导致伪共享。
考虑初始情况下 Cache0 和 Cache1 都处于 S 状态,现在 CPU0 收到线程 A 的请求,写 arr[0],Cache0 状态变为 M,而 Cache1 收到通知后也作废了自己的缓存行。接下来 CPU1 发起了写操作,根据 MESI,CPU0 会先将 arr[0] 写回内存,此时 Cache0 变为 I。之后 CPU1 才能从内存或者通过 ringbus 从其他核心重新读取,然后 CPU1 才能修改 arr[1]。
为了解决伪共享存在的问题,通常是尽量避免将需要访问的数据放到同一个缓存行中。而这就是在一些指令中需要内存对齐的原因,当然还有的原因是原子操作上的考虑。
缓存一致性和 volatile 语义
C++ 中的 volatile 的作用之一是强制每次从内存中读值。但既然缓存一致性协议保证 CPU 总是能读到内存里面最新的值,那为啥还需要 volatile 呢?原因有二
- CPU 不一定会读缓存,可能直接读寄存器
例如出于优化,编译器可能把一个值缓存到到寄存器里面,以避免访问内存,既然不访问内存那和缓存一致也没啥关系了。但这样就会出现问题,如果某个线程修改了这个值对应的内存,那么寄存器是不知道的。所以这时候 volatile 强制说不要在寄存器里面读啦,直接从内存里面读。
所以,缓存一致性解决的是Lx缓存和内存之间的问题,而不是寄存器和内存之间的问题。 - 有的缓存一致性也不保证是任意时刻的
CPU 缓存行的写操作也分为直写(write through)和回写(write back)两种策略。
直写就是同时写缓存和内存,因此对于直写来说,确实可以做到任意时刻各缓存中的内容等于内存中内容。
但回写就不一定是任意时刻了,它并不是立即更新缓存,而是只修改本级缓存,然后将对应缓存标记为脏段,只有当所有脏段被回写后才能达到一致性。具体还可以参看缓存一致性。
Memory Barrier 的 API
以 x86 为例,提供了lfence、sfence 和 mfence。
lfence+sfence 弱于 mfence,因为它不能禁止 Store-Load 的乱序。
下面给出三个 fence 的定义。
- MFENCE prevents any later loads or stores from becoming globally observable before any earlier loads or stores. It drains the store buffer before later loads can execute.
包含两层意思:- 禁止一切形式的 Store/Load 重排
- 在下一个指令开始前,清空 Store Buffer
- LFENCE blocks instruction dispatch (Intel’s terminology) until all earlier instructions retire. This is currently implemented by draining the ROB (ReOrder Buffer) before later instructions can issue into the back-end.
包含几层意思:- 除非之前的指令 retire,否则不 dispatch 新的指令。
- 目前通过在 dispatch 后续指令前排空 ReOrder Buffer 来做到的。
- SFENCE only orders stores against other stores, i.e. prevents NT stores from committing from the store buffer ahead of SFENCE itself. But otherwise SFENCE is just like a plain store that moves through the store buffer. Think of it like putting a divider on a grocery-store checkout conveyor belt that stops NT stores from getting grabbed early. It does not necessarily force the store buffer to be drained before it retires from the ROB, so putting LFENCE after it doesn’t add up to MFENCE.
包含几层意思:- 只禁止 Store-Store 重排
- 可以看做在超市售货员的传送带上放置的分隔条,从而防止 NT store 被过早取走。这里的 NT store 指 non temporal store,表示这个 store 并不会马上被读。也就是说没有时间局部性即 temporal locality。
- 不强制排空 Store Buffer
内核层面的同步与并发
中断
x86上的中断
在一些经典的 x86 系统中使用的是 Intel 8259 PIC 处理中断,在这种形式下 CPU 通过两个 8259 处理 16 个 IRQ,这两个 8259 以 Master/Slave 形式存在。在现在多核 CPU 特别是 SMP 架构背景下,中断的机制和单核有所区别,主要借助于高级可编程中断控制器(APIC)。APIC 由本地 APIC 和 IO APIC 组成,其中本地 APIC 与每个处理器核心对应,IO APIC 负责采集和转发来自 IO 设备的中断信号。
根据 Intel 的规定,广义上的中断可分为同步中断和异步中断。
- 同步中断又称异常,实际上是由 CPU 产生的,因此显然不能被屏蔽。异常分为故障(fault)、陷阱(trap)和终止(abort),对应到中断号的0-15。
- 异步中断又称中断,分为**外部非屏蔽中断(NMI)和外部可屏蔽中断(INTR)**,分别对应中断号 IRQ 的16-31和32-47。Intel 将非屏蔽中断也归入异常,所以异常一般为来自外设或 CPU 中的非法或故障状态,例如常见的除零错误、缺页(故障)、单步调试(陷阱)等情况。
中断语境主要讨论的是异步中断中的可屏蔽中断,它通常是来自外部设备的中断。这是因为除了一些硬件故障,来自外部 IO 设备的中断常是可以等待的,所以属于可屏蔽中断。当 IF 标志为1时,CPU 可以不响应可屏蔽中断,而是将它缓存起来,在开中断后会传给 CPU。当 CPU 在响应一个异常时,所有的可屏蔽中断都将被屏蔽,而如果此时再出现一个异常,即产生了 double fault 故障,一般来说系统就会宕机。
Linux的中断
Linux上每一个CPU都拥有一个中断栈,这个始于Linux2.6的版本,在此之前,中断共享其所在的内核栈,后来Linux认为对每个进程提供两页不可换出的内核栈太奢侈的,所以就将其缩小为1页,并且将中断栈独立了出来。
中断处理的原则是快,否则很容易被覆盖。因此,中断上下文又被称为原子上下文(《Linux内核设计与实现》),该上下文中的代码不允许阻塞,这是因为中断上下文完全不具备进程的结构,因此在睡眠之后无法被重新调度。
在操作系统如Linux中,中断还可以被分为软件中断(内部中断)和硬中断,硬中断是来自硬件的中断,它可以是可屏蔽的,也可以是不可屏蔽的。软件中断一般是由int指令产生的,由操作系统提供,在Linux中软中断对应于中断号48-255。软件中断是不可屏蔽的(不然干嘛调用int呢),但在操作系统中软件中断也可能是由一个硬中断产生的,例如一个来自打印机的硬中断可能产生一个软件中断给内核中的相关处理程序。我们需要区分软件中断和软中断,前者指的是INT指令,后者特指Linux的一种中断推后处理机制(在Windows和Linux的分别被称为中断延时处理和中断下半部)。
x86中断向量/中断描述符
在实模式中使用中断向量表,在保护模式中使用中断描述符表IDT。从上文中我们得到不可屏蔽中断占用了IDT的0-31,其中前半是异常,后半是外部中断。
Intel使用了三种中断描述符:中断门、任务门、陷阱门。而Linux中则分为五种,即中断门、系统门、系统中断门、陷阱门、任务门。
中断程序的注册和处理
需要使用中断的驱动程序会调用request_irq()向内核注册一个中断号irq和中断处理函数irq_handler_t handler,并激活对应的中断线。request_irq()会接受一个flag,flag中的一个选项IRQF_DISABLED表示禁用所有中断,如果不设置这个值,那么该中断处理程序可以被非同种中断打断,这也就是说Linux中硬中断是可以嵌套的。不过Linux禁止来自同种类中断的打断,它会挂起后来的中断,这主要是为了防止重入现象的发生,从而简化系统实现。Linux通过巧妙的机制来防止同种类中断重入。
1 | // 当中断来临时,IRQ_PENDING被设置,表示正在排队 |
需要特别注意的是“只要非同种中断发生就可以抢占内核”这句话也是不准确的,因为开中断发生在中断处理函数handle_IRQ_event中,此时如果没有设置IRQF_DISABLED,Linux就会立马开中断。
1 | irqreturn_t handle_IRQ_event(unsigned int irq, struct irqaction *action) |
但是在这个函数前的一条调用链中都是关中断的,这是CPU的一个特性,即中断发生时触发中断门会自动关中断,也就是置IF为0,可参考这篇文章。关中断的好处在于可以防止中断嵌套,防止内核抢占,但不能禁止来自SMP架构下其他处理器的并发访问,为了解决这种并发访问,通常的做法是借助于例如自旋锁的机制。此外在关中断时要注意关中断会导致异步IO、调度等一系列依赖中断的功能失效,所以屏蔽中断后一定要尽快执行完临界区内代码。
此外,flag中还有一些其他的选项,例如IRQF_SAMPLE_RANDOM,这个被Linux用来实现随机数,会将每次的中断间隔填入内存熵池。与之对应的是IRQF_TIMER,这个表示系统时钟中断,显然系统时钟具有固定间隔,是不适合用来实现随机数的。
中断的开启与关闭
我们使用local_irq_disable和local_irq_enable来控制当前处理器的中断,对应到x86架构上就是常见的 cli 和 sti 命令。不过 Linux 更推荐使用local_irq_save来禁止中断、local_irq_restore来恢复到原来的状态(因为可能一直就是禁止中断的)。
1 | static inline void native_irq_disable(void) |
《Linux内核设计与实现》指出在2.5版本前存在一个禁止所有处理器中断的内核函数cli(),这个函数非常暴力,乃至它实际上提供了对其他所有中断处理程序的互斥访问机制,在这一把全局大锁下我们实际上就可以保证共享数据的互斥了,也就不要像后面版本中那样关闭本地中断后还需要用自旋锁来维护。取消这个全局大锁的好处是使用细粒度的锁能提高性能。
相对于local_系更轻量级的方案是只禁用一种中断,也就是disable_irq、disable_irq_nosync系列,他们禁止中断控制器上的指定中断线irq,其中_nosync系列立即返回,而前面的需要等待已有的中断处理完毕,其实就是在调用_nosync之后调用synchronize_irq去等待,借助于raw_spin_lock_irqsave。《Linux内核设计与实现》指出disable_irq和enable_irq不是幂等的,因此要成对调用才能确保正确回到原始状态。此外还指出这个是保证不会sleep的,但是我在4.17的内核中看到现在的实现是wait_event一个事件,里面涉及一个might_sleep宏的调用。
共享中断
Linux的中断是可以共享的,也就是说同一个中断可以有多个处理程序响应。一个共享中断,例如定时器中断,必须通过request_irq设置IRQF_SHARED标志。
中断下半部
Linux中,中断下半部可以被硬中断打断,所以可以认为硬中断具有更高的“优先级”(不过Linux中并没有中断优先级的概念,虽然也有个中断线程化的东西)。这道理是显然的,因为我们又要快速地响应设备,又不能在中断上下文停留过久,所以才发明了中断下半部这个东西。
Linux中的中断下半部的实现有三种机制:Orignial Bottom Half机制、Task Queue机制、软中断Softirq机制、tasklet和工作队列,其中前两种已被替代。
Orignial Bottom Half(BH)
使用32个链表串联,全局中只有一个BH能够运行。
Task Queue
软中断
从2.3开始,软中断和tasklet被引入,其中tasklet是基于软中断实现的。软中断和软中断之间是不会抢占的,事实上它们被抢占也就是如之前提到的只能被硬中断抢占,但包括相同类型的软中断都可以在SMP的不同CPU上并行执行。注意软中断处理函数属于中断上下文,从而在处理软中断时也不允许休眠,所以其实软中断的优先级还是很高的。
Linux中使用softirq_action结构表示软中断,Linux中设置了一个长度为32的softirq_action数组来存放这些中断。
1 | struct softirq_action { |
可以看出,软中断实际上很像一个回调函数。那么软中断和回调函数之间有什么区别呢:
- 软中断能够实现不同优先级代码的跳转
- 软中断的重入性和回调函数不同
软中断的检查与执行一般出现在以下几种情况:
- 从硬中断返回时。这是一个很常见的情况,因为从硬中断返回之后往往会立即开启软中断,但是在软中断时可以自由地抢占了。
- ksoftirqd内核线程。
这个内核线程是为了处理可能存在的大量的软中断。对于如网络子系统之类的使用软中断的系统,他们可能会频繁的触发软中断,并且在软中断处理函数中可能还会重复触发软中断。这样就会存在大量的软中断抢占其他任务执行时间的问题。对于这个问题,单纯地选择执行完所有当前的软中断或者所有重复触发的软中断都放到下一跳执行都是不合适的。 - 来自网络子系统等显式要求检查软中断的部分。
软中断的执行非常有意思,通过移位操作来实现按顺序check并执行32个软中断的行为,具体可以查看《Linux内核与实现》
虽然不如硬中断处理函数那么严苛,但由上可见软中断的使用还是有很大限制的,目前使用软中断的主要有网络IO、SCSI、内核定时器、tasklet等、RCU等。
但注意工作队列由内核线程eventX执行,允许被调度甚至睡眠。
Linux的外部中断处理过程可以参考文章。
tasklet
相对于softirq,相同类型的tasklet在一个时刻只有一个在执行。tasklet通过TASKLET_SOFTIRQ和HI_SOFTIRQ两个软中断触发,实际上也是出于中断上下文之中的,所以不能睡眠。
进程与线程设施
进程模型
五状态进程模型包括新建、就绪(等待CPU)、阻塞(等待事件)、运行和退出。在五状态模型之外,还有挂起操作。挂起操作指的是将进程交换到外存,这常常是由于内存紧张或者该进程被阻塞的缘故。挂起不同于阻塞或者就绪,被挂起的进程犹如进入一个平行世界,当等待的事件到达时,它能够从挂起阻塞直接切换成挂起就绪。一个挂起的进程必须脱去挂起这层壳之后才能重新进入五状态模型,如一个挂起就绪态进程必须换回到内存切换成就绪态才能被调度。
在 Linux 中,进程的状态主要有 TASK_RUNNING、TASK_INTERRUPTIBLE、TASK_UNINTERRUPTIBLE、_TASK_TRACED、_TASK_STOPPED。
TASK_RUNNING表示进程处于执行或者排队等待执行的状态,此时进程可能位于用户态,也可能位于内核态。TASK_INTERRUPTIBLE表示进程正在被阻塞,等待条件达成或者信号。TASK_UNINTERRUPTIBLE是不可中断的睡眠状态,这是指这个进程不响应SIGKILL等外部信号,因此必须是十分短暂的,在ps -aux命令中显示为 D。
顺带一提,僵尸进程 Z 也不能响应外部信号,僵尸进程的资源已经被全部释放,只留下包括task_struct在内的一点信息用来给父进程提供返回码等信息。如果此时父进程被阻塞而不能回收子进程,那么子进程就会进入僵尸状态。
还要注意区别僵尸进程和失去父进程的孤儿进程。
fork 出的子进程默认会拷贝父进程的一系列资源,包括内存(包括堆栈)、文件描述符(特别地 exec也会保留文件描述符,可以参考我有关 subprocess 的文章)、信号设定、Nice优先级值、工作目录等。
线程模型
Linux 根据调度者在内核内还是内核外将线程分为用户线程和核心线程,前者一般更利于并发使用多核处理器资源,后者则需要较多地考虑上下文切换的开销。为此在设计时往往会引入一对多或者一对一多对多等线程模型,例如使用一个核心线程去调度多个用户线程。
pthread(POSIX threads) 是 POSIX 下的一套线程模型,而 Linux 对这套模型或者接口的实现跟随时间先后有 LinuxThreads 和 NPTL 等几种方式。
- LinuxThreads
LinuxThread 轻量级线程选择直接复用进程,这是一个简单做法。无论是fork()还是pthread_create(),最后都是调用do_fork(),普通进程和轻量级进程(线程)的区别在于调用参数不同。线程的创建一般会使用CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND等clone_flags参数选项,表示共享地址空间、文件系统、描述符和信号处理,而fork只有CLONE_CHLD。
在 Linux 内核 2.6 出现之前进程是(最小)可调度的对象,当时的 Linux 不真正支持线程。LinuxThreads 计划使用系统调用clone()来提供一个内核级的线程支持。但是这个解决方法与真正的 POSIX 标准有一些不兼容的地方,尤其是在信号处理、进程调度和进程间同步原语方面。 - NPTL
Native POSIX Thread Library(NPTL)是 Linux 内核中实践 POSIX Threads 标准的库,是 POSIX 线程模型的新实现。我们可以在 glibc 库源码的nptl目录下可以看到它被用来实现了 pthread 系列函数接口。这里的POSIX Threads标准也就是一系列pthread_开头的函数。
信号
Linux中信号是一个实现异步的机制。信号分为同步信号(synchronous signal)和异步信号(asynchronous signal)。同步信号类似于SIGFPE、SIGSEGV,通常标记着一个无法恢复的错误,来自当前执行上下文中,通常由一个trap陷入内核,并由一个trap handler触发。异步信号则来自当前的执行上下文之外
系统调用
在稍后的论述中,我们将看到进程在用户态和内核态之间切换时常伴随有很多奇妙的工作,不过首先来先行讨论一下系统调用。进程从用户态进入内核态可以通过系统调用、异常(如缺页异常)和来自外部设备的硬中断,而系统调用是最常见的一种,也是应用程序唯一主动进入内核的机制。
Linux的系统调用以asmlinkage long sys_打头,据说asmlinkage保证从栈中提取函数的参数,其实就是CPP_ASMLINKAGE __attribure__((syscall_linkage)),其中CPP_ASMLINKAGE就是在C++上用extern "C"导出符号。system_call系统调用负责系统调用并陷入内核,从前它是一个int 0x80指令,现在它是sysenter指令,它精简了int的流程。这是因为保护模式中CPU首先从中断描述符表(IDT)中取出对应的门描述符,比较中断描述符级别DPL和int调用者级别CPL,我们禁止CPL>DPL的调用,但是对于系统调用来说比较描述符的这一步是能省掉的,因为我们可以确定这个CPL和DPL。system_call从eax中获得系统调用号,并定位到对应的NR_调用位置。
需要特别注意的是由于内核抢占和SMP的关系,系统调用一定要是可重入的。因此系统调用时完全可以被信号打断的,当然也可以在调用前通过SIG_IGN、sigprocmask()、pthread_sigmask()的方法去屏蔽掉信号以防止系统调用被打断。
调度
多任务系统常使用非抢占式(cooperative)或者抢占式(preemptive)的调度策略,Linux支持抢占式的任务调度。和处理器的流水线设计类似,一个好的调度策略需要balance延迟和吞吐量,也就是说它应该能在一定程度上识别和预测出IO型和计算型的程序,并且分别给予它们更短的响应时间或者吞吐量。此外,调度的时间间隔,或者说每个进程所拥有的时间片的大小也对应着处理器流水线深度的情况,太频繁的调度会导致系统在调度器上浪费太多的资源,所以我们也要控制调度的切换代价。Linux的调度算法从简单粗暴,变为了O(1),并在最后使用了RSDL也就是目前的CFS算法。
CFS调度算法
CFS根据NICE给每个进程分配一个处理器使用比,一个实际消耗使用比小于当前进程的进程将抢占当前进程。注意到这种策略相对于传统的,按照NICE值给高优先级进程分配更长时间片要更为贴近现实,因为NICE值较高(也就是优先级较低)的进程通常是计算密集型的,而如果按照NICE值,这些进程将获得较短的时间片,反而是优先级高的获得较多的时间片,旱的旱死,涝的涝死。此外,直接用NICE去标定时间片还会涉及定时器节拍改变导致时间片改变、优化NICE到时间片映射的问题,最终的结论是进程之间的切换频率如果非固定的,效果会更好。
CFS理论上希望一个进程能运行多久取决于处理器使用比,因此指定目标延迟(如20ms)的情况下,每个进程实际能得到的运行时间就和它占到的比例以及总的可运行进程数有关了。当然,我们的分配也是要有最小粒度的,例如最小的时间片长度不能小于1ms。Linux使用task_struct中的sched_entity结构来描述。在具体实现的时候我们并不会望文生义地来做,而是在结构sched_entity中使用vruntime表示加权的虚拟运行时间,这里的加权指的是默认进程的权重比上当前进程的权重。在update_urr中,Linux使用now - curr->exec_start计算出delta_exec时间并使用__update_curr,将未加权的加入到sum_exec_runtime,加权的加入到vruntime中。根据CFS的原则,我们现在应当从CFS队列cfs_rq(这里rq表示run queue的意思,在Linux源码中有很多这样的简写)中调用__pick_next_entity()选取vruntime最小的进程,Linux在这里使用了红黑树来实现。
Linux的调度器
schedule()函数负责选中最高优先级的调度类中最高优先级的进程,整个过程最后会到idle类,对应到Linux中的0号(idle)进程。有多个调度类的原因是由于Linux中不但存在普通进程(对应于CFS),还存在实时进程。在选中之后,schedule()会调用context_switch()来进行上下文切换。
一般来说,schedule()函数是由进程调用的,当进程死亡(调用do_exit)、阻塞等需要放弃当前时间片时就会调用schedule()。我们现在考虑最主要的等待某个条件而陷入阻塞的情况,这时候线程会将自己放入等待队列,等待一个condition。这个过程涉及到多个函数,其中DEFINE_WAIT宏用来创建一个wait_queue_entry结构,add_wait_queue负责将一个进程增加到等待队列,prepare_to_wait负责等待队列上的一个进程置入睡眠,finish_wait负责将一个进程移出等待队列。这些函数中都使用了内部结构spin_lock来维护等待队列。《Linux内核设计与实现》书中举了下面的典型的用例,我们看到整个过程用while所维护,期间会发生若干次schedule()。此外我们发现进程可能会被信号所唤醒,也就是所谓的虚假唤醒/伪唤醒,这时候我们同样退出循环,而不是继续循环等待,这也就是为什么我们在后面看到使用条件变量要while-wait的原因。唤醒操作由wake_up()函数负责,它会负责调用try_to_wake_up,该函数会唤醒等待队列上的所有进程,注意系统中有很多个这样的等待队列,每个等待队列上的所有进程等待同一个事件。一般来说,wake_up的调用者就是使得条件达成的那一方,这个和条件变量的逻辑是相同的。
刚才说到有虚假唤醒,其实还有无效唤醒,也就是进程带着condition进入睡眠。
1 | // 3.11.10 |
Linux的抢占
被动式的调度指的是使用一个调度器决定哪一个任务会在下一刻运行,而不是由进程主动放弃处理器。由调度器决定暂时停止一个任务并让另一个任务开始执行的行为就是抢占式(preempt)调度。抢占式调度分为用户抢占和内核抢占两种。
先前提到,进程可以通过主动调用schedule()来放弃剩余时间片,但对于时间片耗尽的情况,内核中的scheduler_tick()函数(此时关中断,需要在2.6版本左右查看)会通过set_tsk_need_resched(p)函数设置一个need_resched标志,这个标志从逻辑上讲应该是全局性的,但为了方便从高速缓存中读取,它自2.2版本后被放到了每一个进程的task_struct中,自2.6内核后放到thread_info中。此外在刚才的try_to_wake_up()唤醒过程中,如果被唤醒的进程的优先级更高,这个标志也会被设置。从系统调用/中断处理程序中返回的情况也包括在内,这也对应着用户抢占。
用户抢占
Linux的用户抢占并不是在用户态下,而是发生在进程即将从内核态返回用户态时,这对应两种情况,从系统调用返回和从中断处理程序返回。如果不开启内核抢占,抢占式调度会给每一个进程的运行分配一个固定或者动态计算的时间片(timeslice),进程在内核态的运行会直至结束(主动放弃(yield)/时间片耗尽/阻塞)。这样的假设方便了内核的编写,特别是在单处理器(UP)下,因为我们考虑到在内核态中不存在对进程上下文的切换,所以内核并不需要考虑对临界资源的竞争访问问题,因此用户程序也可以假设在一次系统调用过程中不需要保护内核临界资源。但需要注意的是中断仍然存在,所以在进入临界区前还需要关中断。
内核抢占
通过内核抢占,系统允许高优先级的进程抢占低优先级的进程的内核态,这将能提高系统的实时性能。内核抢占可能发生在中断处理程序返回到内核空间前、内核代码具有抢占性、内核代码显式调用调度器schedule、内核中的任务被阻塞时。此外,内核抢占是可以被关闭的,即所谓的关抢占的几种情况:
当内核调度器scheduler正在运行时
这个是显然的,我们可以直接在schedule()函数中看到相应实现1
2
3
4
5
6
7
8
9
10
11
12
13
14// 2.6.11
// /include/linux/preempt.
do { \
inc_preempt_count(); \
barrier(); \
} while (0)
// /kernel/sched.c
need_resched:
preempt_disable();
prev = current;
release_kernel_lock(prev);
need_resched_nonpreemptible:
rq = this_rq();另及,Linux通过内核抢占锁
preempt_count来跟踪一个进程的可抢占性,当内核代码具有抢占性时(此时preempt_count为0,且need_resched被设置),则调用preempt_schedule_irq -> schedule进行内核抢占,这过程的发生场景之一就是从时间中断返回。我们看到这里关中断实际上是自增了preempt_count使它不等于0。这里的do{}while(0)是出于宏的考虑,防止和其他语法结构(如没有括号的if)混用导致错误。中断的bottom half
通常有上文所述的三种方式,当内核执行软中断和tasklet禁止内核抢占,但注意此时可以被硬中断打断。当进程持有自旋锁读写锁
这实际上是为了保护临界资源,在有关自旋锁的讨论中会详细说明。事实上当进程持有锁时preempt_count会自增,释放锁时preempt_count会自减,这也就是使用preempt_count的缘由,进程持有锁的数量直接影响到它的可抢占性。内核正在处理中断
这时候也就是所谓的中断上半部,中断在操作系统中拥有最高的优先级,我们也在前文中论述了中断上下文中不能睡眠的原因,这里不能抢占的原因也是类似的。内核操作Per-CPU data structures
在SMP架构中,不同的CPU仍然会维护一些私有数据,此时抢占可能造成一个进程被调度到另一个CPU上去,此时Per-CPU变量就会发生改变。我们可以查看相关代码1
2
3
4// 2.6.39.4
// /include/linux/smp.h而
get_cpu就是获得当前的CPU,我们看到首先这一步骤就关了抢占,其中smp_processor_id会调用raw_smp_processor_id这个宏,然后根据不同的CPU来讨论。例如对x86来说,这个宏是#define raw_smp_processor_id() (percpu_read(cpu_number)),然后是#define percpu_read(var) percpu_from_op("mov", var, "m" (var))。然后我们就可以根据获得的CPU号操作unsigned long my_percpu[NR_CPUS]这样的每个CPU独有的数据了。注意所有这样的操作是不需要加锁的,因为这是当前CPU独有的数据,而内核抢占又被关闭了,所以不存在并发访问问题。
《Linux内核设计与实现》中指出了对每个CPU维护私有数据的好处:- 减少了竞态条件和锁的使用,这个在上面已经提到
- 减少了缓存失效的可能
根据MESI,同一数据可能存在于多个CPU的缓存中,这样一个CPU造成的修改会导致缓存失效。而一些性能不佳的代码会造成缓存抖动,也就是缓存的不停刷新,这样极大地降低了效率。Linux2.6内核提供了per_cpu接口能够缓存对齐(cache-align)所有数据,这样可以保证不会讲其他处理器的数据带到同一缓存上。
关中断
这是一种特殊情况,关中断后抢占机制自然无法实现了,Linux关中断通常借助于local_irq_disable或者local_irq_save。
可重入、异步信号安全、线程安全与中断安全
可重入函数
考虑单线程模型,一般来说执行流程是不会被外部打断的,但考虑可重入(reentrant)性仍然是有必要的。一个典型的场景是signal机制(借助于软中断实现)。例如,我们在函数func涉及读写全局变量errno,在这个过程中被signal中断,而中断处理程序也会访问这个errno,那么当继续进行func时就可能读到无效的errno。很多的系统调用是可重入的,一般来说不可重入函数具有以下几个特征:
- 在未保护的情况下访问全局或者局部静态变量
我们希望可重入函数只访问自己栈上的变量。
这里注意,严格意义上errno这个全局变量是怎么都避免不了的,但幸好这个变量有着明确的修改时间,所以我们推荐**在信号处理函数一开始保存errno**,退出时恢复errno的做法,从而保护了调用前后的现场。 - 调用
malloc/free函数
因此我们在信号处理函数里面应当避免使用malloc,这是因为如果我们在主逻辑里面malloc时被signal了,这时候信号处理对malloc的调用就有可能破坏内核数据结构。 - 调用标准IO等对硬件有副作用的函数
- 调用
longjmp之类的函数
POSIX中还描述了异步信号安全(async-signal-safe)的概念,并列举了一系列信号安全的系统调用。从本质上讲一个异步信号安全的函数要不是可重入的,要不对信号处理函数来说是原子的,即不能被打断。
线程安全
异步可重入和线程安全是两个不同的概念,线程安全指一个函数能够同时被多个线程安全地调用。
一般来说线程安全的函数不一定是可重入的,如malloc,而反之则一般是成立的。所以我们可以体会到Linux提供的signal机制虽然能够实现异步,但是却添加了许多需要考虑的成分。
中断安全
内核和运行时向外提供的并发与同步设施
多进程与多线程
进程是UNIX设计模型中的一个重要部分,UNIX推崇以多进程+IPC的方式组成应用系统,充分贯彻了KISS的方针。在UNIX产生的年代,这种方式无疑是很健壮的。
从定义上看,进程是资源分配的最小单位,那么线程是程序执行的最小单位。线程通常和同一程序下的其他线程共享一套地址空间,其中包含应用程序拥有的程序代码与资源,每个线程自己维护一套运行上下文。
同步与异步
在进程IPC中同步和异步是两种编程模型,描述了IPC中被调用者的行为。在同步模型中一个调用只有在等到结果(也就是被调用者完成计算)时才返回,被调用者并不会进行通知。而异步模型中调用会立即返回,而由被调用者选择在结果达到后通过回调函数或者信号等机制进行通知。UNP书中还强调异步过程中用户不需要手动将数据从内核复制到用户(即不需要在被通知后调用read等函数),但我觉得这是异步过程所必须具备的特性,而不是其根本的区分点。
需要和同步异步进行区分的是阻塞和非阻塞的概念,这两个描述了调用结果未到达时调用者的状态。阻塞调用会直接睡眠线程,而非阻塞调用不会阻塞线程。在非阻塞同步调用中,当调用者还没有收到来自调用者的返回时,调用者可以原地进行轮询等待,此时虽然逻辑无法持续,但线程并没有进入睡眠。此外,非阻塞模型还可以是异步的,此时线程可以继续执行下面无关返回值的逻辑,消息到达时线程收到一个异步信号或者回调,或者采用类似协程的方法。
IO多路复用是一种特殊的同步模型,它们在消息到来前必须在一个循环中轮询,而不是立即返回并跳出循环。
- IO 多路复用并不属于同步阻塞模型,因为当一个 fd 在等待结果时,线程可能在处理来自其它 fd 的 IO,因此并不一定会进入睡眠。
- IO 多路复用也不属于同步非阻塞模型,因为当没有任何一个 fd 产生 IO 事件时,线程还是会被阻塞的。
UNP 还特别指出 poll 函数中仍然需要手动将数据从内核复制回来,并把它作为多路复用和异步之间的一个区别。
以 UNIX 套接口为例,SS_NBIO 和 SS_ASYNC 标志分别表示非阻塞和异步的选项,其中非阻塞套接口在请求资源不满足时会返回 EWOULDBLOCK,而异步套接口则会通过 SIGIO 信号来通知进程。
协程
协程(Coroutine)是具有多个入口点的函数。协程内部可通过 yield 放弃剩余的 CPU,此时处理器可能被调度到执行其他的函数。虽然线程也可以通过睡眠实现切换的功能,但因为其本身涉及用户态与内核态的上下文切换,开销较大。对于套接字等 IO 密集型的应用,协程在提高 CPU 使用率上比线程轻很多。
协程根据其底层实现可以分为 stackful 和 stackless 两种:
- stackless 不保存调用栈和寄存器等上下文
stackless 的协程实现例如 C++ 中的 setjmp、Python 中的生成器、Rust 中的 await/async 等。
stackless 的协程通常需要用户显式通过 yield 来交出控制权。
stackless 的协程通常具有传染性,这是因为堆栈本身就是系统用来维护上下文的工具。如果不使用堆栈,那么不同任务使用的寄存器信息以及局部变量,就需要被手动维护。这样的好处是省掉开一个栈帧的开销,我们可以只选择有用的进行保存,减少一些“空间放大”。坏处就是传染性,因为这一堆上下文不能透过栈来传递。 - stackful 即栈式构造,这时候协程拥有自己的堆栈等上下文
stackful 的协程类似于 C++ 中的 ucontext、libco,以及 Go 内置的 goroutine 等。
协程根据对 CPU 控制权的转移方式可以分为对称(symmetric)协程和非对称协程(asymmetric):
- 对称协程在转移时可以转移到其指定的任一对称协程
- 非对称协程只能转移到其“调用者”
一般来说,对于 Iterator 类的协程,也就是目的是用来给用户序贯返回对象的,会使用这种方案。
理论上已经证明了这两种协程在表达能力上是等价的,但显然非对称协程在使用上更友好。
还可以分为两类:
- First Class 协程
- Constraint 协程
这一类的协程用来实现特殊的目的,不能被程序员直接操纵,比如有 Iterator 抽象。例如 Python 的 generator。
C++下协程的实现方式
基于 ucontext
ucontext 是 POSIX 上的一套用于保存上下文的库,这里上下文包括寄存器(通用和浮点)、信号等。
黑科技1
Protothreads基于C的是围绕switch展开的一系列黑科技实现的协程。我们首先看它定义的一些原语,原来这就是一个简易的,关于行号的状态机。我在这里模仿Protothreads实现了一个简易版的协程
1 |
|
回想 C++ 实现协程需要实现的一个核心问题,并不是调度,而是实现从多个入口点进入。这就意味着需要在退出协程函数时记录下已经到了哪里,然后在下一次进入函数时回到这个地方。对于第一个需求,可以借助于 __LINE__ 这个宏表示执行到的行号,每次将这个行号赋值给一个 int。对于第二个需求,可以借助于 switch 实现跳转。这里用 switch 而不用 goto 的原因是 switch 能够根据 int 变量来实现 goto 的功能,而 goto 需要依赖静态的 label。这种巧妙的机制不禁让我想起了称为Duff’s device的优化方案。
不过这种机制有一个语法缺陷就是在里面嵌套的switch语句会产生干扰。
基于setjmp和longjmp
setjmp和longjmp类似跨栈帧的带上下文的goto。int setjmp(jmp_buf env)负责将函数当前的上下文保存在jmp_buf中。
约束线程间并发行为(有锁)
线程间实现互斥与同步的任务常具有下面两种形式:
- 多个线程同时访问一个共享资源,需要维护该共享资源的完整性。这就是 Race condition 问题,将在本节讨论。
- 一个线程向另一个线程通告自己的结果/等待另一个线程的结果,这将在章节数据共享中讨论。
总的来说,为了实现同步,等待资源的一方可以处于用户态(忙等)或者内核态(睡眠),而获得资源的一方可以选择锁进行同步,或者使用原子操作保证自己访问不被打断。这分别下面的基于锁和原子操作的工具。Linux、Windows和C++11的标准库中都对这些工具提供了不同程度的支持,具体可参考文档。
Race condition
竞态条件常出现在逻辑电路这样的硬件环境中,对于软件环境而言,当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件(race condition),导致竞态条件发生的代码区称作临界区。
为了解决竞态条件,有下面的思路:
- 确保只有当前进行修改的线程才能看到不变量被修改的中间状态。
需要临界资源保护起来,前面看到的互斥量等属于这种机制。 - 借助于锁无关编程技术,将对数据结构的修改分解为若干个不破坏不变量的原子操作。
- 借助于事务的STM技术,将所需要的操作存储于日志中,再合并提交。
不变量
不变量(invariant)是某个特定数据结构始终保持的特性。例如通过链表的前向指针始终能到达前驱结点。
不变量对应的特性常常在更新过程中被破坏,特别是当更新涉及到修改多个值,或者需要多个过程时。这就类似于在最终一致性系统的窗口内强一致性被破坏。当不变量遭到破坏时,才会产生竞态条件(C++ Concurrency in Action: Ch3)。
volatile
在有关 CPU 缓存一致性的章节中,讨论了 volatile、寄存器、主存和 CPU 缓存之间的关系。现在讨论 C++ 中的 volatile。
C++ 中的 volatile 并不以任何形式保证线程安全,它仅用来告知编译器期修饰的变量是易变的,要避免对其进行优化:
- 将变量缓存到寄存器中而不是每次都从内存读取。
volatile不禁止编译器或者处理器进行重排或乱序。
需要通过编译器屏障或者内存屏障来实现这一点。
volatile 关键字有时是有用的,例如可以在自旋锁中防止多次循环中始终读取寄存器中的值。但滥用 volatile 不仅不会提高程序的安全性,而且会导致程序变慢。
内核锁
内核锁一般基于内核对象互斥量/信号量,它们通常是阻塞锁,会导致线程进入睡眠。锁的存在通常限制了并发范围,变并行访问为串行访问。在使用锁维护临界资源时应当争取让序列化访问最小化,真实并发最大化。
互斥量
在C++中一般不直接使用 std::mutex,而使用 lock_guard、scoped_lock 和 unique_lock。它们利用了 RAII 来自动管理加锁解锁操作,从而可以应用到包括互斥量的所有 Lockable 的对象上。
unique_lock 相比于 lock_guard 更灵活这体现在:
用户能够手动地加/解锁,例如在条件变量中就需要
unique_lock以便解锁,而在取得对临界资源后进行处理时也可以暂时解锁。可移动
以下面的代码为例,这里1处是一个直接返回lk,编译器可能进行 NRVO。当然即使不这么做,2作为一个直接初始化操作,也可以接受get_lock返回的将亡值,从而完成移动构造std::unique_lock<std::mutex>。因此这里锁的控制权从get_lock转移到了process_data。1
2
3
4
5
6
7
8
9
10
11
12std::unique_lock<std::mutex> get_lock()
{
extern std::mutex some_mutex;
std::unique_lock<std::mutex> lk(some_mutex);
prepare_data();
return lk; // 1
}
void process_data()
{
std::unique_lock<std::mutex> lk(get_lock()); // 2
do_something();
}有些时候,我们可能需要将某些 lock_guard 保存在一个容器中,此时有两种做法:
- 利用 emplace 系列函数进行本地构造
但这使得我们无法用 get_lock() 函数返回了。
我觉得后续也许可以引入一个 emplace_by 函数。或者这里也可以利用 operator T 进行一些优化。 - 用 unique_lock 替换 lock_guard
- 利用 emplace 系列函数进行本地构造
根据 C++ Concurrency in Action,一般会将 mutex 和临界资源一起放到一个类中进行管理,此时宜保证该临界资源是非 public 的,并且不会以引用或者指针的形式传出。这些场景例如:
- 成员函数直接返回指针或者引用
- 友元函数
- 一个接受函数指针 P 作为参数的函数,且 P 接受了临界成员的指针或引用,并将其泄露到类外
因此要避免在持有锁时调用用户传入的函数。
std::recursive_mutex 互斥量
在大多数时候,我们是否一定需要 std::recursive_mutex 呢,还是往往这是一个架构问题?在一个线程中,会遇到这样的情况:
- 模块 A 加锁
- 模块 A 调用模块 B
- 模块 B 处发生事件,需要调用模块 A 中的另一个方法
- 模块 A 再次加锁
这个问题的核心在于,1-2 阶段加锁顺序和调用顺序是正的,而 3-4 阶段是反的,从而产生死锁。当然可以采用一些办法解决:
- 将锁透传,但一个模块 A 的锁为什么要给到模块 B 呢?这个我认为破坏了封装性。
- 在调用模块 B 之前解锁,但这个未必可行,可能在解锁的时候产生了 race。当然,我们可以为这个过程引入一个锁来保护过程逻辑。
问题核心在于,这个架构是否可以避免 3-4 这样的回调?如果让模块 B 返回一个 flag 告知模块 A 后续需要调用另一个方法,其实是更好的设计。
场景讨论
我们的愿景是最大化真实并发,因此要追求较小粒度的锁(small granularity),一个较小的粒度表现在锁所保护的临界数据较少,并且持有锁的时间较短,但粒度不可能无限小。
删除链表节点
考虑删除双向链表中的一个节点,需要修改三个节点的数据。但如果对这三个修改以此单独加锁,其实等于没有加锁。一个直截了当的解决方案是在删除过程中锁住整个链表,但粒度有点大了。
如果是仍然希望为每个节点维护一把锁,那么对于删除操作必须获得被删除节点和其相邻的共三把锁,当重新连接节点时,必须在获得当前节点锁的前提下尝试获取下一节点的锁(但一旦持有了下一节点的锁就可以释放当前节点的锁了),以防后继节点产生变化,这有点类似于数据库上的蟹行协议,称为lock coupling。与此同时,在遍历时同样需要按照和删除相同的上锁步骤。我有个朋友当时就对这一点很疑惑,他说我添加删除都上锁了,那为啥访问还需要加锁?锁这玩意,防君子不防小人,那我访问的时候完全可以不去获取锁的嘛,那你那边的线程加不加锁管我什么事,除非加锁、解锁和改指针的操作是原子的。那么在遍历的时候是只锁一个节点就行了,还是要蟹行呢?我们可以举一个很夸张的例子,例如我们从头遍历链表[a,b,c]并试图删除b,其过程是获取a的锁,然后获取b=a.next,然后锁住b,然后移除从a到b的指针。那么我们同时有一个遍历线程,它是龟兔赛跑里面属兔子的,乌龟还没出发,他就遍历到a了,这时候a没有被锁住,然后这位兔子线程释放了a的锁(蛮良心的,睡觉前懂得释放锁),然后拿着a的后继也就是b去睡觉去了。这时候乌龟线程才开始锁住a和b,并删除掉了b。乌龟线程释放完锁继续往后面遍历了,这时候a的后继已经是c了,兔子线程醒来了, 此时他还以为b是真的后继呢!
TODO 这里可以看下 6.852。
线程安全的栈
下面再考虑一个线程安全的栈,其中实现了 empty()、top()、size()、push()、pop() 等常见方法。在多线程下,下面的代码中 pop() 可能使得 top() 的结果无效,这是因为在1和2两个方法间可能有另一个线程执行了pop()。容易看出无论这些方法内部怎么加锁都无法避免这种情况,因为这里的竞态发生在这些方法之间,C++ Concurrency in Action特别指出这属于接口设计的问题。在后面内存模型的部分,我们能看到类似的问题,原子操作虽然避免了竞态,但原子操作之间可能存在的乱序必须要被考虑。书中还指出了另一个更严重的2和3之间竞争的错误,假设有两个线程并行执行该段代码,我们期望的顺序是top[1] -> pop[1] -> top[2] -> pop[2],中括号表示执行该方法的线程。然而实际执行顺序可能是top[1] -> top[2] -> pop[1] -> pop[2]。这就导致了从栈顶开始的两个元素有一个被处理了两次,另一个完全没有被处理。一个简单的解决方案是将这两个调用合并成一个带返回值的pop,使用一个mutex来管理,但Tom Cargill指出这处理方式是有问题的。这涉及到为什么标准库在设计时选择将top()和pop()两个方法,原因是可能发生在成功将元素pop后而拷贝函数失败,这个元素就被丢失,所以先取top()再pop()保证了top()失败情况下可以选择不执行pop()。
1 | stack<int> s; |
死锁
使用互斥量的另一个问题是死锁,这时候锁机制避免了竞态,却可能产生线程对锁的竞争(contention),即线程间互相等待对方的锁。死锁的产生满足四个条件:互斥、占有且请求、不可抢占和循环等待。其中等待且请求条件很关键,当完成一个操作需要获得两个及以上的锁时,死锁往往就会发生。为了解决死锁就要想办法破坏它的四个条件之一。
破坏占有且请求
可以借助于Dijkstra的银行家算法。在C++11中,可以使用标准库函数std::lock来同时上锁,不过现实情境下往往难以在申请锁时就确定自己需要哪些锁。因此在诸如数据库的系统中,会引入两段加锁协议。破坏循环等待
可以永远按照一个顺序来获得锁。以哲学家就餐问题为例,可以将筷子进行编号,并约定哲学家们总是先尝试获得编号较低的筷子,用完后总是先释放编号较高的筷子,这样就能避免死锁问题。
推广来说,在加锁阶段只加锁不解锁,在解锁阶段只解锁不加锁。
注意到约定哲学家们总是先拿起左手边的筷子,再拿起右手边的筷子恰恰会导致死锁问题,因为并不是对每一个哲学家的操作指定一个相对的规则,而是为所有的资源也就是锁的获取直接指定一个绝对的顺序。于是可以发现有时候去确定一个顺序并不是很容易。对swap函数,可以按照参数的顺序来加锁。例如先获得第一个参数的锁,再获得第二个参数的锁。可惜这个是相对的,例如考虑如下面代码所示的两个规则,容易发现这两个线程并行执行时死锁就会发生了。1
2
3
4// thread 1
swap(a, b);
// thread 2
swap(b, a);为了解决这个问题,一个方法是对每个对象求 Hash,从而进行排序。或者还是借助于
std::lock函数。
另一种解决死锁的办法从锁的角度,为锁提供层级。一个已持有低层级锁的线程是不能试图获得高层级的锁的,试图违反这一约定的行为将导致抛出异常或终止程序。注意到不能同时持有相同层级上的锁,所以这些互斥量往往形成一条链。一个层次互斥量 hierarchical_mutex 的实现可以对每个线程使用一个 thread_local 全局变量进行维护当前线程所持有的锁的层级,默认取 UINT_MAX ,这样线程可以获得任何层级的互斥量。
锁的粒度是它保护数据规模与持有时间。所以即使可以避免死锁也要注意锁的粒度对性能的影响。总的原则:
- 一个锁应当被持有尽可能少的时间,并且在持有过程中只应该去完成必要的工作。
- 持有一个锁的同时等待另一个锁,即使不造成死锁,也要考虑其性能问题。
以判定两个int是否相等为例,刚才介绍了个 swap 函数的实现方案,同时对两个互斥量进行加锁。但这里考虑到实际上 int 非常小,所以比较好的是分别对两个 int 加锁,复制并比较两个副本,从而避免同时持有两个锁。注意和前面 top() 和 pop() 所遇到的问题一样,在对 intA 和 intB 的读操作(LOAD)间可能发生另一个线程对 intA 的写操作,导致先前读取到的是旧值。
值得注意的是引起死锁的并不一定是锁,而可以扩展到造成互相等待的其他情况。例如一组线程互相 join 等待对方,相互阻塞,这导致整个程序无法往下运行。或者线程在持有锁时同时等待其他线程。此外即使在一个线程中,也会出现如同死锁的现象。例如下面的代码希望 subroutine1 和 routine 都在 mut 的保护下,但它在。
1 | void subroutine1(){ |
std::lock 的实现
std::lock 的作用是将多个互斥量同时上锁。如果失败时则抛出异常并释放已经获得的锁。下面代码展示了一个线程安全的swap。
1 | class some_big_object; |
std::lock 的实现借助了 try_lock 即 _Try_lock。
1 | template<class _Lock0, class _Lock1, class... _LockN> inline |
自旋锁
自旋锁是一种忙等锁(busy waiting),它适用于短时间锁定某个资源,从而避免内核锁所需要的线程睡眠产生,比如两次线程上下文切换等一系列的开销。诸如 epoll 的函数为了防止在睡眠时丢失事件,在等待 rdllist 的时候也会使用自旋锁。
但持有过长的自旋锁会导致浪费大量 CPU 资源。特别是在单核 CPU 上,自旋锁的使用需要审慎考虑。因为在单核CPU上同一时间只能运行一个线程,这时候如果等待锁的线程先运行,那么它势必进入空等直到时间片用完,因为获得锁的线程势必不能运行以释放锁。因此在单核 CPU 上使用内核锁进入睡眠,而不是用自旋锁忙等是一个好的选择。自旋锁常被用在对称多处理器(SMP)系统中,在多CPU的情况下保护临界区。
自旋锁与中断处理
处理中断时不能使用互斥量、信号量等让线程进入睡眠的锁,因此自旋锁常用于内核中有关中断处理的部分。内核锁必须在进程上下文(对应于中断上下文)中才能使用,这里的关闭中断的目的是为了关闭调度,因为关闭了时钟中断(时钟中断是可以被关闭的),调度器就无法运转了。这样就产生了睡死的现象。
持有自旋锁时不能进入睡眠
自旋锁适用于不能睡眠的场景,但双向地来说,持有自旋锁时也不能进入睡眠,否则会引起死锁。
如果进程 A 获得了自旋锁并且阻塞在内核态,此时内核就可能调度起了进程 B。B 也试图获得自旋锁,但因为 A 持有这自旋锁并在睡眠无法释放,那么 B 将永远自旋,A 将永远睡眠,直到 B 的时间片用尽。此外另一种解释认为对于不关中断的自旋锁在睡眠后可能会被重新调度,从而造成自死锁的现象。
Linux 内核中的自旋锁常伴随关中断和关抢占。在 Linux 中提供了 spin_lock 系列的关闭了抢占而不关中断,而 spin_lock_irqsave、spin_lock_irq、spin_lock_bh 会一道把中断也关了。
关抢占的原因是如果一个低优先级的线程 A 获得自旋锁而紧接着被一个高优先级的进程 B 抢占,那么会造成这两个线程死锁,直到时间片用尽。这就是所谓的优先级反转,或者称为优先级倒置现象。这会严重影响性能。
关中断的原因是类似的,只是现在抢占的“线程”是中断。考虑一个进程 A 获得自旋锁然后被一个中断打断。此时中断处理器也试图获得同一个自旋锁,因为自旋锁不能嵌套上锁,所以中断内部就会死锁,这就是自死锁现象。并且中断处理无法被抢占(但可以被其他中断打断)。可以参考文章和知乎。
这种思想同样值得用在处理异常、信号等会破坏程序执行顺序的地方。
自旋锁的实现
查看原子操作部分。
临界区
相对于互锁访问函数这种“有限的”原子操作,临界区允许对一段代码进行“原子操作”。临界区相对于互斥量比较轻便,这是由于互斥量能够跨进程,并且支持等待多个内核对象。同时线程在进入一个被占用的临界区时会首先尝试自旋锁,在自旋锁循环一定次数失败后再让线程进入睡眠。
临界资源的初始化
临界资源的初始化问题的一个重要的情景就是实现单例模式。在 C++11 后,可以有 Meyers Singleton,它满足满足初始化和定义完全在一个线程中发生,并且发生在所有其他线程访问之前。【Q】似乎这个是Lazy的。
如果希望带参数初始化,还可以使用 std::call_once,或者在 C++11 前使用 pthread_once。
C++11前的朴素方案
在C++11前,可以用下面的代码实现单例。这里用一把大锁保证了不会有两个线程竞争创建/访问 p_singleton的实例。这无疑是正确的,但却开销巨大。因为当实例被唯一地创建好后,这个函数就是纯只读的,不需要锁来保护了。事与愿违的是每次调用这个函数都需要获得锁,因此需要一种仅保护临界资源初始化过程的机制。
1 | Singleton * p_singleton = nullptr; |
双重检查锁定模式
双重检查锁定模式(Double-checked locking pattern, DCLP)指的是在加锁前先进行一次验证是否可以加锁,目的是减少加锁的开销,具体的做法是先检查一遍 p_singleton 是否为 nullptr。
1 | Singleton * p_singleton = nullptr; |
这种加锁方式也是有理论上的风险的,例如 p_singleton 不是原子的,甚至都不是 volatile 的。基于我们与编译器的约定,编译器完全可以认为 p_singleton 的值不会发生变化,因此直接将两层 if 削掉一层。
但即使将 p_singleton 套上 std::atomic、加上 volatile,这个代码仍然是错误的。原因在于 p_singleton = new Singleton() 这条语句不是原子的。因为该语句的执行分为三步
- 分配内存
- 构造对象
- 指针指向对象
尽管实践中编译器没有理由去进行这样的重排,但编译器在理论上可以在2构造对象前执行1内存分配和3指针指向操作。假设线程在1/3步骤完毕之后被挂起而来不及执行2步骤,而另一个线程开始访问 a 处的代码,注意到此时p_singleton已经不是nullptr了,于是函数会返回一段未初始化的内存。
继续思考发现,第一个线程此时已经在初始化 p_singleton,这第二个线程就不应该有机会执行到a处的代码。试想即使第二个线程知道另一个线程在初始化了,那它又能做什么呢?因为这个函数的声明是要么初始化并返回指针,要么直接返回指针。选择前者会破坏第一个线程的初始化过程,选择后一个会造成上面说的结果。不然总不能 throw 吧。因此在 a 处对 p_singleton 进行保护是非常有必要的。
在后面对类型模型的讨论中,将讲解如何通过添加 fence 或者借助 acquire/release 语义来写出一个正确的 DCLP 代码。
call_once方案
在下面的代码中,只会输出一行 Called once。
1 | std::once_flag flag; |
这里的 std::once_flag 不能被拷贝和移动,其实相当于一个锁,call_once 是借助于 runtime 函数 __crtInitOnceExecuteOnce 实现的。
1 | template<class _Fn, |
虽然可以通过 Meyer’s Singleton 来做线程安全的单例,但如果想带参数地初始化是困难的。可以借鉴下面的代码
- 使用 Meyer’s Singleton 声明一个全局单例的 once_flag
- 借助这个 once_flag 就可以 call_once 地初始化单例了
1 | template <typename T, typename F> |
读写锁
相对于临界区,读写锁能提供更精细的控制,它适用于写操作远少于读操作的数据结构。读写锁允许一个写线程独占访问,而多个读线程并行访问。当写线程需要独占访问时,它需要获得一个排它锁。如果此时有另外的线程持有排它锁或者共享锁,那么写线程就会被阻塞。当读线程需要共享访问时,只要没有线程持有排它锁,那么他就可以立即获得共享锁。读写锁的过程可以参照来自博文的论述
1 | Read object begin |
对读写锁 Windows API 提供了所谓的 SRW 系列函数,Linux 提供了 rwlock 系列函数。在C++14中终于提供了std::shared_timed_mutex来实现读写锁,C++17中提供了std::shared_mutex来实现一个没有定时的读写锁。
这从设计上看来这是有点本末倒置的,为什么要在C++17实现一个功能更少的类呢?SoF指出这是出于性能原因。在C++14制定时,原本的std::shared_mutex拥有定时功能,但稍后发现去掉定时功能能够提高效率,例如借助Windows上的SRWLOCK机制可以高效简便实现没有定时的读写锁,所以后来C++14版本的 std::shared_mutex 被重命名到 std::shared_timed_mutex,而一个没有定时的 std::shared_mutex 在 C++17 提供。
在 C++17 中:
- 读锁可以声明为
std::shared_lock<std::shared_mutex>
注意,shared_lock来自 C++14 - 写锁可以声明为
std::unique_lock<std::shared_mutex>,如此跨越三个版本的标准才最终完成的实现,你只有在C++中才能看到。
从实现上来看,无论是关键段、互斥量、信号量,甚至是条件变量都可以实现读写锁。
关键段的实现方式
这里摘录了CSDN上的一个实现。其思想如下互斥量的实现方式
注意读操作时要获取写锁以免脏读。
作为优化,为了避免多个读线程竞争写锁的情况,还需要一个读锁。只有竞争到读锁的线程才能去锁定写锁。其过程如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 写
lock(mutex_write);
write();
unlock(mutex_write);
// 读
lock(mutex_read);
if(readers == 0)
lock(mutex_write);
readers++;
unlock(mutex_read);
read();
lock(mutex_read);
readers--;
if(readers == 0)
unlock(mutex_write);
unlock(mutex_read);信号量的实现方式
这里的Swait(sem, t, d)表示信号量sem的 P 操作需要t个资源,并且会消耗d个资源。Ssignal(sem, d)表示信号量sem的 V 操作产生d个资源。这里Swait类似std::lock,可以同时对若干个信号量上锁,从而避免死锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14// 初始化
max_reader = n; // 最多允许n个读者读
Sinit(sem_read, max_reader);
Sinit(sem_write, 1);
// 写
Swait(sem_write, 1, 1; sem_read, max_reader, 0);
write();
Ssignal(sem_write, 1);
// 读
Swait(sem_write, 1, 0; sem_read, 1, 1);
write();
Ssignal(sem_read, 1);条件变量的实现方式
约束线程间并发行为(无锁)
无锁情况下,主要存在下面几个问题:
- Race condition
- GC
- 编译器和处理器的重排和乱序
锁无关和原子操作
加锁操作的弱点
加锁操作通常存在下面一些问题:
- 加锁本身让一段逻辑变得串行。
如果能有序地组织各个线程“各行其道”,就能避免程序中引入很多的串行逻辑。 - 使用锁,则发生竞态时线程进行睡眠而不是立即重试,从而产生上下文切换的开销。
- 加锁容易造成死锁。
- 优先级反转问题
也就是持有锁的线程因为优先级较低,所以没有被调度。
在极端情况下,一个持有锁的线程崩溃了,也可以理解为处于调度的最低优先级(永远都不会被调度)。
因此,我们去探寻一些不使用锁的解决方案。
锁无关简介
锁无关(Lock-Free)是一种比无干扰(Obstruction-Free)高层次的并发模型,它是一个容易混淆的概念。如果算法中不使用锁,称为 Lockless。但锁无关并不是不用锁,而是确保各个线程在访问共享资源时之间不会互相阻塞,从而使得整个程序整体上能够始终向后执行。也就是说,如果线程 T1 被阻塞在某个操作上,那么一定有另一个线程 T2 在某个操作上成功了,通常我们也会这样证明一个算法是锁无关的。如果使用内核锁,如果一个获得内核锁的线程被挂起或者挂掉,这容易导致其他拥有锁的线程陷入永久等待。
相应的还有一个无阻塞(Non-blocking)的概念,无阻塞的限制条件要弱于锁无关。属于无阻塞算法而不属于无锁算法的常见例子是自旋锁。在自旋锁中:
- 所有的线程都不会进入睡眠,因此是非阻塞算法。
- 考虑当获得锁的线程因为一些原因被暂停时,所有的其他线程仍然需要在原地自旋忙等,因而自旋锁不是无锁算法。
内核锁和死锁的关系
死锁或者竞态问题和不使用锁之间并不存在必然关系。如下所示,如果两个线程并行执行这段代码,则同样可能死锁
1 | while (x == 0) { |
如原子操作、CAS 之类的范式,它们本身都是不涉及到锁的。但为了确保读写成功,往往需要尝试若干次,但这个多次尝试造成的等待本身不属于锁无关的范畴。并且这个等待的过程中,总有人能持续推进。
其实锁机制本身也是和等待没有关系的,因为有些操作中的等待是客观的,不能看到锁,就想到阻塞和等待。即使不停 while 去轮询,没有锁,但还是存在忙等。
原子操作
原子操作是常见的实现锁无关编程的方式。
An operation acting on shared memory is atomic if it completes in a single step relative to other threads。
- When an atomic store is performed on a shared variable, no other thread can observe the modification half-complete.
- When an atomic load is performed on a shared variable, it reads the entire value as it appeared at a single moment in time. Non-atomic loads and stores do not make those guarantees.
原子操作指的是不可被中断的一系列操作。原子操作保证当前操作中不发生线程切换,因此保证了其他的线程不可能访问这个资源。
对 C++ 中原子操作的特别说明
下面对 C++ 中的原子操作做一个特别说明,展示声明一个 std::atomic 变量是必要的。除非放弃遵守 C++ 标准,那么不要尝试仅通过 non-atomic 变量,和一些 volatile、atomic_thread_fence 等怪异手段来约束不同线程间不同变量的操作行为。
atomic 对象是线程间 order 的桥梁
C++11 前根本没有考虑对多线程或者内存模型提供语言级别的支持,而这点 Java 就做得比较好。事实上,它规定 data race,即并发地去修改一个对象是 UB 的,所以编译器优化可以不考虑多线程的情况,可能导致错误。在线程 A 中对 x 的修改,以及在线程 B 中对 y 的修改,可能是互相不可见的。为了约束跨线程间 store/load 的顺序,只有求助语言外的工具,例如 CPU 指令或者操作系统正面的支持。
下面展示了早期 GCC 编译器的问题,可以发现,一个线程是没办法感知某个变量是可能在线程外被修改的。
1 | extern int v; |
在这个问题中考虑调用 f(0),单线程情况下肯定不会执行 v=1。在 gcc 生成的代码中,也确实看到 if 被优化掉了,始终执行 movl %eax, v,显然编译器认为 f 并不会被修改。但在多线程下,set_v 完全有可能在线程外被修改。
在 C++11 之后,增加了原子操作的定义,其中也定义了各种 order,例如 Happens-before 啥的。通过原子变量和原子操作,就可以指定 order。一般的思路是这样的:
- 单线程的 Sequenced-before,单线程中的各个操作是有序的。
- atomic 对象和 atomic 对象之间可能构成 synchronizes-with 关系。
那么通过两个 atomic 对象之间构成的桥梁,就可以联系两个线程之间的其他的哪怕是 non-atomic 的对象了。所以 atomic 对象是不可或缺的。
store/load的原子性
知道 x86 汇编要求对任意位置的1字节,以及对2/4/8对齐的2/4/8长度的整型读取都是原子的,但是 C++11 前却不能假设甚至是对一个 int 赋值的操作是原子的,而在 C++11 后就可以使用 std::atomic 来显式声明一个原子变量。
这是因为考虑一些违反 strict aliasing 的胡乱 cast 破坏了对齐,C++ 无法保证从内存 load 一个 plain 的值是原子的。
原子操作的分类
原子操作可以分为简单的原子 Store Load,以及更为复杂的 RMW 操作,比如 CAS、FAA、TAS、TTAS 等。
1 | std::atomic<>::fetch_add() |
一般来说可以借助原子的 CAS,即 C++ 中的 compare_exchange_weak,实现其他的原子操作。
通过解答下面两个问题,可以看到原子操作的一般使用场景:
能通过原子操作实现复杂的逻辑么?
答案是可以的,下面的代码乐观地前置了大部分操作,但是对其他线程可见的只有最后一步到位的compare_exchange_weak修改。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16uint32_t atomicDecrementOrHalveWithLimit(std::atomic<uint32_t>& shared)
{
uint32_t oldValue = shared.load();
uint32_t newValue;
do
{
if (oldValue % 2 == 1)
newValue = oldValue - 1;
else
newValue = oldValue / 2;
if (newValue < 10)
break;
}
while (!shared.compare_exchange_weak(oldValue, newValue));
return oldValue;
}能通过原子操作操作多个变量么?
答案是可以的,可以将多个变量封装到一个 struct 里面,然后操作这个 struct。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19struct Terms
{
uint32_t x;
uint32_t y;
};
std::atomic<Terms> terms;
void atomicFibonacciStep()
{
Terms oldTerms = terms.load();
Terms newTerms;
do
{
newTerms.x = oldTerms.y;
newTerms.y = oldTerms.x + oldTerms.y;
}
while (!terms.compare_exchange_weak(oldTerms, newTerms));
}
如何判断是不是原子操作
举个例子,i++ 是原子操作么?答案并不是。可 i++ 不就是一条 INC 指令么,为什么不是原子?别忘了执行只是流水线的一部分,还有访存、解码、写回呢。所以需要考虑三个维度:
- 内存
- CPU 缓存
- 寄存器和指令
在这些维度中,还需要考虑是否对齐。
1 |
|
互锁访问函数和CAS操作
操作系统提供的原子 API 常借助于某些 CPU,比如 Intel 处理器提供的指令。这些指令能够对某些类型实现某些原子操作。对 SMP 架构而言,会出现多个核心并发写的情况,这个涉及到后面的内存模型,并且这里可以暂时忽略这个问题。
Windows API 提供了一系列 Interlocked 开头的互锁访问函数,这些函数在处理器层面被保证独占访问。其中一个很关键的便是 InterlockedCompareExchange(PLONG dest, LONG value, LONG old) 函数,这个函数提供了对 LONG 类型的原子的 CAS 操作。显然,通过内核锁能够方便地实现原子语义,但内核锁会导致线程睡眠,而这可以通过 CAS 避免。
例如下面的 InterlockedExchange 函数,设置新值并返回老值,这就利用了 CAS。
1 | LONG InterlockedExchange(LONG volatile * target, LONG value){ |
这里的 do-while 循环保证了在 InterlockedCompareExchange 失败之后再来一遍能够再来一遍直到成功。但是不能将这个循环和自旋锁中的忙等混淆,从而认为 CAS 不是锁无关的。这是因为:
- CAS 实际上并没有“持有”临界资源,它只需要一个指令就能结束战斗。
因此,某个线程被 block 住了,或者被睡眠了,也不会导致其他线程忙等或者死锁。反而因为竞争减少了,可能导致 CAS 成功率变高。 - 如果这里的 CAS 失败了,说明另外一个线程的 CAS 成功了。
因此可以看出 CAS 在这里对竞争访问实际上是“消极防御”的态度,也就是**乐观锁(Optimistic Locking)**。乐观锁是一种非独占锁,它并不是向内核锁一样直接让竞争者们睡眠,而是延后做冲突检查,并在检查失败时返回一个失败的状态。相对应的,之前的内核锁和自旋锁等机制属于悲观锁、独占锁。
原子操作底层实现
原子操作一般有两种实现方式:
- 使用锁或者 CPU 的指令等机制来维持原子性
- 当出现并发写等破坏原子性的情况时让操作失败
如果最终要执行,则需要在一个循环不断尝试。
需要注意的是,原子操作并不一定就能够提高效率,或者说 scalability:
- 对共享对象操作的原子指令可能造成 cache invalidation,也就是需要重新刷新缓存行。
- 原子操作本身也是不意味着就快,如下图
- 如果冲突过多,那么 CAS 会频繁失败,还不如悲观锁。
在 std::atomic 这一章中讨论了 CAS 操作:
- 对于通常情况,可能会使用自旋锁甚至内核锁
- 对于一些特殊类型,比如 int 等,会借助于 CPU 的原子操作,而 CPU 原子操作的实现可能借助于总线锁、缓存锁等机制
细究上面 WINAPI 的InterlockedCompareExchange,容易猜到它的实现方式来自于 CPU 的硬件支持,因为它只能为特定数据类型提供服务。事实上,这里用了x86中的cmpxchg命令。
下面介绍一下 LOCK 指令对总线锁和缓存锁的选用:
- 总线锁
LOCK#信号就是总线锁,处理器使用LOCK#信号达到锁定总线,来解决原子性问题。当一个处理器往总线上输出LOCK#信号时,其它处理器的请求将被阻塞,此时该处理器此时独占共享内存。
总线锁这种做法锁定的范围太大了,导致 CPU 利用率急剧下降,因为LOCK#把CPU和内存之间的通信锁住了,这使得锁定时期间,其它处理器不能访问内存,所以总线锁的开销比较大。 - 缓存锁
如果访问的内存区域已经缓存在处理器的缓存行中,P6 系统和之后系列的处理器则不会声明LOCK#信号,它会对 CPU 的缓存中的缓存行进行锁定.在锁定期间,其它 CPU 不能同时缓存此数据,在修改之后,通过缓存一致性协议来保证修改的原子性,这个操作被称为“缓存锁”。
需要注意,虽然总线锁和缓存锁可能有较大的性能开销,但这只是处理器级别针对于单个指令而言的,最多会导致某些指令执行变慢。而内核锁则涉及操作系统,特别是线程间的上下文切换了。
特别地,当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行时,也会使用总线锁。
诸如 BTS、BTR、BTC、XADD、XCHG、ADD、OR 等指令自带总线锁。注意CMPXCHG应该不默认是原子的,对于单核,可以不加 LOCK;但是对于多核,需要加 LOCK。
CAS操作的实现
1 |
|
看一下反汇编 g++ --std=c++11 cas.cpp -o cas -S,可以发现是通过 lock cmpxchgl 实现的_ZStanSt12memory_orderSt23__memory_order_modifier 是 std::operator&(std::memory_order, std::__memory_order_modifier)。
1 | .cfi_startproc |
下面看复杂类型
1 | struct Comp { |
使用CAS操作实现的无锁链表
因为文章太长,所以被拆出来一篇新文章。
CAS 和 LL/SC
ABA问题
伴随着 CAS 的是可能存在的 ABA 问题。原则上,这不是 CAS 造成的,毕竟 CAS 只是比较相等而已。但问题是相等并不代表没有发生变化,所以单纯使用 CAS 未必能达到我们预期的效果。具体来说,使用 CAS 操作时,我们实际的目的是检查某个对象和 T 时刻相比是否发生变化。但 ABA 问题指出很多时候,用等号比较值一样不代表对象就没有发生变化。简而言之,用等号是一个“浅层的”的比较,当涉及多个对象时,不能因为一个对象不变,就判断所有对象组成的系统就不变。
例如以栈 A -> B -> C为例,很可能一个线程在试图 pop 栈顶 A 的时候被调度走,新的线程先弹出 A 再弹出 B再压入 A。这时候老线程被调度回来,发现栈顶还是 A,就会认为栈没有发生变化,即依旧是 A -> B -> C,但实际上栈已经变成了 A -> C 了。
1 | def pop(): |
刚才的例子是对一个栈来说的,A/B/C 是不同的数据对象,有的人可以说,比较栈里面的全部元素不就行了?在下面的一个例子中可以看到,即使对于相同的对象,也是会产生问题的。可以发现,值相等,并不代表对象 X 没有经历变化。
1 | X is $100. |
考虑下面的执行顺序,Thread 2 会 Fail 掉,最后 X 还是 100。
1 | 1 - 2 - 3 |
但是对于下面的执行顺序,X 只有 50 了。
1 | 1 - 3 - 2 |
可以看出,这其实还是一个逻辑上的问题:对于前者来说,Thread 1 和 Thread 2 可以理解为发送了重复的请求;对于后者来说,可以理解为 Thread 2 是一个新的请求,只是恰巧和 Thread 1 的判断条件相等。
ABA 问题的解决有如下的一些思路。
Tagged state reference
一个通常的做法,是添加一个额外的 tag。例如在 CAS 时,可以添加一个 counter,表示对象被修改的次数。这样 ABA 就会变成 ABA’。
Deferred reclamation
此类方案包括 HazardPointer 和 RCU 等。核心思路是延迟 GC。
【Q】为什么延迟 GC 可以解决 ABA 问题呢?需要考虑 ABA 出现的常见场景。如果我们删除了一个对象,然后又创建了一个同类型的新对象,那么这个新的对象很可能和老对象有着相同的内存地址,从而产生 ABA 问题。
如果我们能保证每次修改对象,会导致其地址改变,就可以用其地址而不是值来判断相等了。
指令集
诸如 ARM 等架构会提供一个 LL/SC,即 load linked, store conditional 命令。This effectively separates the notion of “storage contains value” from “storage has been changed”. Since these instructions provide atomicity using the address rather than the value, routines using these instructions are immune to the ABA problem.
原子操作与锁的关系
上面的讨论能够直观地发现原子操作和锁的关系:
- 原子操作看起来是“独善其身”的只能管住自己,原子操作之间、原子操作和非原子操作之间可能发生乱序或重排。
- 锁像大哥,能护住一段代码。
由此思考如何通过原子操作来组织其他的那些非原子操作呢?这就要引入下面讨论的内存模型的问题。
原子操作(以C++为例)
上面章节概览了锁无关编程和原子操作的概念。从现在开始,我们将讨论C++11标准库提供的原子操作机器具体实现。
因为本段过长,所以被移动到新文章中。
其他的同步原语
在上面的几个章节中,论述了基于锁和基于原子操作的同步原语。还有一些其他的同步原语,例如 RCU、MCS Lock 等。
Hazard Pointer
被迁移至Hazard Pointer。
RCU
RCU(Read Copy Update)是 Linux2.6 引入的一种替代读写锁的方法。其思想是在多个读者能和一个写者并行,写者在访问值时首先拷贝一个副本,对副本进行修改,再在适当的时候将新的数据一次性写回,这个时机就是所有读者完成读取之后。由此看出这种方法能够很好地适应读多写少的情况:
- 读者端不需要任何锁来保证同步,也不会被写者阻塞。
- 写者端的任务加重了
首先,它仍然要处理和其他写者的竞争问题。
然后它具有复制开销,还需要监听所有读者的信号以确定数据的修改时间。
下面描述了写操作的流程:
- 对旧数据建立一块副本,对副本进行修改
- 等待前面所有的读者完成读取
这时候 RCU 实际上向专门的垃圾回收器注册一个 callback 并等待器通知,这段时间称为 grace period。 - 写者将原来的数据替换为新的数据
- 写者删除旧的数据
MCS Lock
MCS Lock是一种高性能的自旋锁,通过保存执行线程申请锁的顺序信息解决了传统自旋锁的“不公平”问题。MCS Lock 具有 Owner 和 Next 两个域,初始值都为0。当内核线程申请锁时,会 return Next++ 值作为自己的 Ticket Number。如果返回的 Ticket Number 等于申请时的 Owner,则直接获得锁,否则该线程就进行忙等。
普通的 MCS Lock 要求线程自旋在同一个共享变量上,因此涉及对该共享变量的频繁修改,这给诸如 NUMA 架构的系统会导致缓存失效的问题。因此有了 MCS Spinlock 这个基于链表的数据结构。MCS Spinlock 维护多个被组织为链表的自旋变量 waiting,其初始值为1。每个节点的申请者都自旋在 waiting 上等待其 prev 释放锁,当 waiting 变为0时结束自旋。
通过内存模型约束线程对变量的读写顺序
这一篇主要还是围绕 C++ 的内存模型来讲解的,通过讲述语言的实现,来介绍 OS 和 CPU 微架构层面的相关知识。
理解线程间的同步难点之一就是需要从编译器与 CPU 两个层面考虑行为对造成的的影响,也就是考虑编译器重排、CPU 的缓存以及 CPU 的乱序对读写逻辑可能造成的影响。当试图使用原子操作去解决非原子操作间的同步问题时,需要选择恰当的内存模型来保证安全性。
具体到语言层面,需要关注 C++ 的 as-if rule。它实际上屏蔽了很多编译器或者 CPU 的实现细节。因为只要保证结果和预想的一样,那么编译器是否重排,CPU 是否乱序,标准是不会指定的。但在本文中,依然会使用重排或者乱序的概念,因为这更直观。
as-if rule
as-if rule指出,C++ allows any and all code transformations that do not change the observable behavior of the program.
在下面的 Memory Model 的论述中,会遇到很多 as-if rule 的场景。我们不应该关注实际的实现,这实际上取决于编译器。
目前已知的 as-if rule 的反例是 C++17 之后的 guaranteed copy elision。可以看我有关 C++ 右值的论述。
多线程中面临的问题
在 C++11 之前,编译器和处理器达成的协议是不能改变单线程程序的行为,但对跨线程之间的行为没有任何的规定。在 C++11 开始,才引入了内存模型。
以编译器优化为例,下面代码使用 g++7 编译。在 O0 下,按照 1-2 顺序;开启 O1 后,g++7 就会进行 Store-Store 重排,将 2 提到 1 前面,先对 b 赋值,再对 a 赋值;并且还去除了一部分没用的代码。
1 | int main(){ |
对单线程来说,这样的优化并没有任何问题。但对于多线程来说则可能出现问题:
- 由于去除部分代码的原因,从 O1 的汇编来看,不能在 a 处观察到
a == 1 && b == 1。而假设 O0 汇编在进行到 b 处被抢占,那么其他的线程有机会看到以上的情况。 - 另一方面,在 O1 中先对 b 赋值再对 a 赋值,仍然会出现问题。
假如说在 3 和 4 间有另外一个线程观察a和b,得到b为 123,而此时a为不确定值。
而如果编译器不进行重排,理想中的原始结果是a为 43,b为不确定值。
在多线程程序中,不能假设所有环境下程序的行为一如代码所“暗示”一样。编译器或处理器可以在不同线程间对不同变量间进行读写乱序。这显然是属于合理优化的一部分。
例如在单线程中将对 B 的写提到对 A 的读前面是没有问题的,但是对多线程来说,这往往就会出现问题。大部分时候不需要操心,这是因为:
- 使用了 mutex 等锁
但这会让程序片段处于串行状态,在一些时候可能影响性能。 - 部分处理器 如 x86 也提供了 TSO 模型,蕴含了 acquire/release 语义,并也可以通过一些指令命令编译器在某些地方减少优化。
可见性和有序性
可见性:一个线程对变量的写操作对其它线程后续的读操作可见,这里见的是结果。可见性要求 CPU 在对缓存行写操作后能够保证至少在某个时间点前必须写回内存,从而保证其他线程能读到最新的值。
有序性:数据不相关变量在并发的情况下,实际执行的结果和单线程的执行结果是一样的,不会因为重排/乱序的问题导致结果不可预知。
在CppReference中,有下面的定义,我们将分小节来介绍
Sequence Points
在 C++98/03 的标准中定义了 sequence point 来描述求值顺序,在 C++11 中已经用 Sequence before 来代替了。
At certain specified points in the execution sequence called sequence points, all side effects of previous evaluations shall be complete and no side effects of subsequent evaluations shall have taken place.
Sequenced-before 【单线程】
在单线程中,如果 A Sequenced-before B,那么 A 在 B 之前执行。这个先后根据 eval order 来判断。
如果 A 不 Sequenced-before B,且 B 不 Sequenced-before A,那么这两个操作是:
- unsequenced 的:既可以以任意顺序发生,也可以 overlap 地发生(也就是在这个单线程中,组成 A 的指令和组成 B 的指令interleave 地执行)
- indeterminately sequenced 的:只可以以任意顺序发生,不能 overlap 地发生
总结一下规则,这里有个简单的翻译。先介绍一下 full expression,它指的是 an expression that is not a subexpression of another expression。例如:
- an unevaluated operand
例如 typeid, sizeof, noexcept, decltype。 - a constant expression
- an immediate invocation(Since C++20)
指的是 consteval 修饰的 - an entire initializer, including any comma-separated constituent expressions the destructor call generated at the end of the lifetime of a non-temporary object
注意,int a = 1这样的初始化语句也是 full expression 了。 - an expression that is not part of another full-expression
比如整个 entire expression statement,for/while 循环,if/switch 循环,return 中的表达式等。
还包括对 expression 的隐式转换,临时变量的析构,default member initializers (when initializing aggregates),以及其他涉及到函数调用的 language construct。
- (Each value computation and side effect) of a full expression is sequenced before (each value computation and side effect) of the next full expression.
- The value computations (but not the side effects) of the operands to any operator are sequenced before the value computation of the result of the operator (but not its side effects).
后面还有一堆我就不翻译了。但最重要的就是分号以前的一堆东西是 full expression。
Sequenced-before 和 as-if rule 是否冲突?
考虑下面代码,根据 Sequenced-before 规则,3 是 Sequenced-before 4 的,因此 3 要在 4 之前执行。但这不符合事实,因为编译器可以重排 3 和 4。
原因是 as-if rule,它要求只要外部观测起来的行为是不变的,那么编译器就可以做任何优化。因为,先计算 a 和 b 都不影响 printf 阶段的结果,所以 reorder 是可以发生的,即使看起来违背了 Sequenced-before 原则。
1 | int main(){ |
Carries dependency 【单线程】 (until C++26)
在单线程中,如果 A Sequenced-before B,那么对于下列情况,可能A Carries dependency into B,也就是说 B 依赖 A:
- A 的值被作为 B 的操作数,但不包括下列情况:
- B 是 std::kill_dependency 调用。
- A 是
&&、||、?:、,的左操作数。原因很简单,短路原则。
- A 写到 scalar object M,B 从 M 读。
- A carries dependency into another evaluation X, and X carries dependency into B
Modification order
Modification order 是对原子操作而言的:所有对某个 atomic 变量操作都是 total order 的。
可以概括成下面四种情况:
- Write-write coherence
如果写 atomic M 的 evaluation A,它 happens-before 了写 M 的 evaluation B,那么在 M 的 modification order 中,A 是比 B 早的。 - Read-read coherence: if a value computation A of some atomic M (a read) happens-before a value computation B on M, and if the value of A comes from a write X on M, then the value of B is either the value stored by X, or the value stored by a side effect Y on M that appears later than X in the modification order of M.
- Read-write coherence
如果对原子变量 M 的读 A happens-before 同一个原子变量上的写 B。再令这个 A 它是来自于写操作 X 的,那么 X 在 M 的 modification order 上先于 B。 - Write-read coherence: if a side effect (a write) X on an atomic object M happens-before a value computation (a read) B of M, then the evaluation B shall take its value from X or from a side effect Y that follows X in the modification order of M
Dependency-ordered before
在线程间,对于下面两种情况,操作 A dependency-ordered before 操作 B:
- 线程1中A对M执行了release;线程2中,B对M执行了comsume,并且B读取的是A写的值(by any part of the release sequence headed (until C++20))。
- A dependency-ordered before X,并且X carries a dependency into B。
Inter-thread happens-before
在线程间,A Inter-thread happens-before B,当满足下面几种情况之一:
- A synchronizes-with B
- A dependency-ordered before B
- A synchronizes-with some evaluation X, and X is sequenced-before B
- A is sequenced-before some evaluation X, and X inter-thread happens-before B
- A inter-thread happens-before some evaluation X, and X inter-thread happens-before B
Happens before (until C++26)
Happens before 实际上是想引入一个可见性保证:如果 A happens-before B,那么在 B 中一定能看到 A 的结果
不考虑线程,A happens-before B,当满足下列两种情况之一:
- A sequenced-before B
- A inter-thread happens before B
如果一个 evaluation 修改了一个内存位置,并且其他的 evaluation 读或者写了相同的内存位置,并且至少一个 evaluation 不是 atomic 的,那么就存在 data race,除非两个 evaluation 之间已经存在了 happens-before 关系。
Visible side-effects
对于标量 M 的写入操作 A,对于对同一个标量 M 的读操作 B 是 side-effect visible 的,如果
- A happens-before B。
- 在 A 和 B 之间没有其他对 M 的副作用 X 了。
If side-effect A is visible with respect to the value computation B, then the longest contiguous subset of the side-effects to M, in modification order, where B does not happen-before it is known as the visible sequence of side-effects. (the value of M, determined by B, will be the value stored by one of these side effects)
Note: inter-thread synchronization boils down to preventing data races (by establishing happens-before relationships) and defining which side effects become visible under what conditions
Synchronizes-with 【原子操作】
An atomic operation A that performs a release operation on an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release sequence headed by A.
即 synchronizes with 的条件式:
- 原子操作 A 对 atomic 对象 M 执行了一个 release 操作
- 原子操作 B 对 atomic 对象 M 执行了一个 acquire 操作
- 原子操作 B takes its value from any side effect in the release sequence headed by 原子操作 A
一个常见的例子是 atomic_thread_fence(memory_order_acquire) 是 synchronizes-with atomic_thread_fence(memory_order_release)的。
但请注意,这个顺序并不是代码层面,而是执行层面的。preshing的这篇文章中描述了具体的条件,也就是说 load(acq) 需要正好去读 store(rel) 写进去的那个 value。
let’s just say it’s sufficient for the read-acquire to read the value written by the write-release. If that happens, the synchronized-with relationship is complete.
如下图所示,如果 load 早于 store 被执行,那么两者之间就没有 synchronizes-with 关系,因为它是读的别的 store 写入的 value。这也是 C++ 标准所谓“atomic operation B must “take its value” from atomic operation A”的意思。
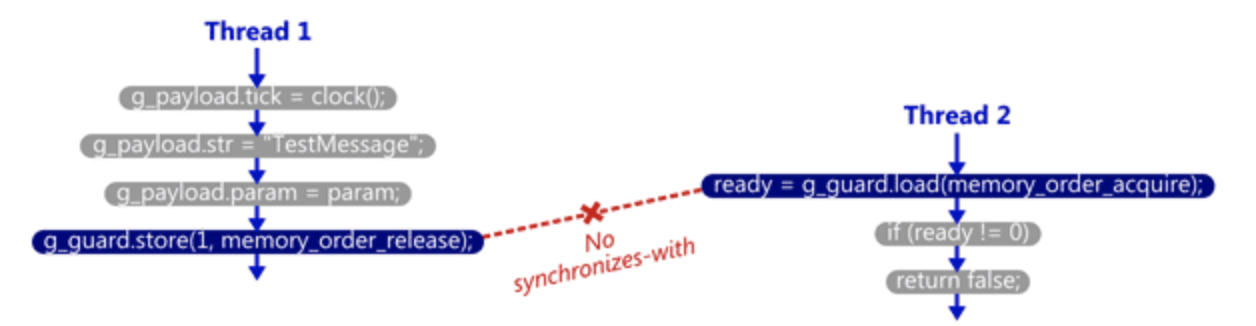
结合上文看出,Synchronizes-with 是一种取得 Happens before 关系的方式。但需要注意,初学者经常犯的错误之一,就是常常希望通过直接比较某原子量来在多线程中同步非原子量,但这在 Relax 这种弱 Memory Order 约束的内存模型下是不可靠的。
例如,在下面的代码中,语句4并不一定成立。这是因为2和3之间并没有任何Synchronizes-with关系,并且1、2,以及3、4之间都可以进行重排。
1 | int data; |
coherence-ordered-before
对于同一个原子变量M,原子操作A是coherence-ordered-before原子操作B,当满足下列之一:
- A is a modification, and B reads the value stored by A
- A precedes B in the modification order of M
- A reads the value stored by an atomic modification X, X precedes B in the modification order, and A and B are not the same atomic read-modify-write operation
- A is coherence-ordered-before X, and X is coherence-ordered-before B
Release sequence
After a release operation A is performed on an atomic object M, the longest continuous subsequence of the modification order of M that consists of
- 【until C++20】Writes performed by the same thread that performed A
- Atomic read-modify-write operations made to M by any thread
is known as release sequence headed by A
内存一致性模型综述
广义上的一致性模型包括Strict Consistency、Sequential Consistency、Causal Consistency、Processor Consistency、FIFO consistency、Cache Consistency、Slow Consistency、Release consistency、Entry Consistency、General Consistency、Local Consistency等。在C++中提供了六种内存模型(memory order)来描述不同线程之间相同/不同数据的读写的顺序。
程序并发执行的实际过程和程序员想象的可能是不一样的。例如下面的程序1和2,程序员觉得执行顺序可能是 ACBD 等等,但肯定不会是 CABD 这样的顺序。
1 | 1 2 |
但是因为计算机允许重排和乱序,所以 CABD 这样的顺序是实际可能发生的!这不就乱套了么?所以内存模型用来限制重排和乱序。也就是说,如果我们很在乎重排和乱序,就可以通过内存模型去限制,甚至完全禁用。当然,可能会导致性能上的影响。但如果不在乎,计算机则可以充分自由地进行重排。
在研究内存一致性模型时,需要考虑下面几点:
- 区分读和写
- 区分对同一变量的操作和不同变量的操作
- 区分线程内和跨线程
- 区分跨内存模型之间的交互关系
比如 acquire 对 plain(raw) store 的影响。 - 微架构方面
例如多核 CPU 之间的 Cache。
内存模型:Relaxed
自由模型(Relaxed ordering)是最弱的模型,它对线程间的执行顺序不做任何 synchronizes-with 的假设,但同线程的变量仍然遵循 happens-before 假设。所以,这实际上是允许编译器对访问不同变量进行重排的。根据 CppReference,Relaxed Ordering 的目的是保证了当前变量的原子性。
Litmus test:Message Passing
【可以参考CPU 的缓存一致性协议这一章节】
考虑下面的代码,Relaxed Ordering 仍然保证:
- 1 先于 2,且 3 先于 4,这里是 Sequenced-before 的原则。
- 且 3 读到 1
但 z 可能为0,即可能看到 y 变成 1,而 x 仍然是 0。这是由于 x 和 y 是两个不同变量,Relaxed 不关注它们之间的关系。
1 | std::atomic<int> x = 0, y = 0; |
但实际在 x86 下的 MSVC2015 上测试下,发现 z 始终不为 0,这是为什么呢?我在 StackOverflow 上提了个问题,它的解答我觉得比较全面:
std::memory_order_relaxed会禁止编译器重排x和y的 Store-Store,可以理解成下面的代码1
2
3
4
5
6
7
8
9
10atomic<int> x, y;
x.store(1, std::memory_order_relaxed);
y.store(1, std::memory_order_relaxed);
// is similar to...
volatile bool x, y;
x = true;
asm volatile("" ::: "memory"); // Tells compiler to stop optimizing here,
// but issues no instructions
y = true;但是 CPU 可能重排
x和y的 Store-Store;并且因为 Store buffer 的存在,x可能被延迟写入内存
关于这个,可以参考 CPU 的缓存一致性协议这一章节。因为 x86 的 TSO 提供了 acquire/release 语义,保证了当 3 是 true 时,在 2 前的对 3 后的可见
所以结论是:由于特定平台的一致性模型要强于 Relaxed Ordering,所以 std::memory_order_relaxed 只是保证强于等于自由模型,在自己的 x86 电脑上编译该测试可能得到不同的结果。
Out of thin air 问题:第1部分
在 https://www.cl.cam.ac.uk/~pes20/cpp/notes42.html 和 https://www.hboehm.info/c++mm/thin_air.html 中有一些论述。但我觉得 https://aaronyoo.medium.com/1-understanding-out-of-thin-air-values-with-c-11-relaxed-atomics-5a2027fd9f4c 这里讲的是最清楚的。
下面的代码在 relaxed 语义下交换原子变量 x 和 y 的值,但这是个错误范例,比如可能读到 x=y=10/20。这里的 r1 和 r2 可以理解为 thread local 的变量,目的是将中间交换的过程变得可见。
1 | x = 10, y = 20 |
无论 CPU 是如何执行的,至少我们期望两个线程中的 load,要不看到初始值,要不看到另一个线程 store 之后的值。
Out of thin air 问题指,x 和 y 的 load 可能都会读到 42,或者其他任意不知道从哪里来的值。如下所示,线程 1 执行 y = x,线程 2 执行 x = y。可能读到 x 和 y 是 42。
1 | x = 0, y = 0 |
问题在于,y = r1 和 r2 = y 这两个之间是否有 happen-before 关系。不妨:
- 考虑 acq/rel 语义,
r2 = y是 take its value fromy = r1的,所以是有 Synchronizes-with 关系,也就实际上是 happen-before 的。 - 但对于 relaxed 语义,并没有这样的约束
r2 未必是要读到 y 那次写入的值了。比如假定预测了 r2 是 42,那么x = r2得到的 x 也可以是 42。
进而,前面的r1 = x和y = r1,也都可以得到 42。
当然,看到这里可能会有疑问,这还能绕回来循环论证么?但这里只是根据 relaxed 定义说这个是合法的,并不是一定这样做。事实上谁会这样做?
anyway,进而因为看到 y 实际上是赋值了42 了,所以 CPU 会认为自己的 speculative 是正确的,从而产生 42 这个值。
上述代码可以被编译器优化为下面的形式
1 | x = 0, y = 0 |
从 C++14 开始,Out-of-thin-air 被标准禁止。
Out of thin air 问题:第2部分
例子来自 cppreference。在这个例子中,是允许输出 r1 == r2 == 42 的。
Thread 1 中 A sequenced-before B,Thread 2 中 C sequenced before D。Nothing prevents D from appearing before A in the modification order of y, and B from appearing before C in the modification order of x。
1 | // Thread 1: |
事实上,The side-effect of D on y could be visible to the load A in thread 1 while the side effect of B on x could be visible to the load C in thread 2.
在SoF上有相关提问。它的意思是,既然 A 一定在 B 前面,C 一定在 D 前面,假如 D 又在 A 前面了,就得到了 C -> D -> A -> B 这样的顺序。那岂不是和 B 又能在 C 前面矛盾了么?
解释是:
- sequenced before 也遵循 as-if rule,所以 CPU 也可以乱序,只要观测的结果不变就行。
- 所以理论上,
C -> D和A -> B并不具备“传递性”。
另一个问题进一步做了阐释。
内存模型:acquire/release 以及 release/consume
acquire/release 模型相对灵活一点。
acquire 只对应读(Load)操作使用,release 只对应写(Store)操作使用。如果对写使用 acquire fence,或者对读使用 release fence 会怎么样呢?很简单,C++ 中不允许:
- 对读,不允许
memory_order_release和memory_order_acq_rel。 - 对写,不允许
memory_order_consume和memory_order_acquire和memory_order_acq_rel。
稍弱一点的 memory_order_release 和 memory_order_consume 只用来保证当前操作涉及到的对象的可见性。因此,consume 语义可以被替换为 acquire 语义,因为 aquire 语义是更强的。
对 STORE/LOAD 操作,下面直接翻译CppReference,在阅读时需要注意“当前线程”和“其他线程”的区别。
同时需要注意,这里不能理解为对 atomic 变量的读会等待对 atomic 的写完成,更准确的说法是**a release store synchronizes with an acquire load that takes its value from the store.**。可以参考“Synchronizes-with”的介绍。
acquire-release 配对:
memory_order_acquire的 Load(R)
在当前线程上,任何后面的 R、W 都不能重排到自己这个 R 之前。也就是禁止 load-store 和 load-load 重排。
在其他线程中的所有 release 相同 atomic 变量的 W,都对当前线程可见。
直觉上来看,acquire 是获得锁。那么不能把被锁保护的东西(读和写)提到获得锁前面。另外,必须要先释放锁再获得锁。memory_order_release的 Store(W)
在当前线程上,任何前面的 R、W 都不能重排到自己这个 W 操作之后。也就是禁止 load-store 和 store-store 重排。
在当前线程中的所有 W,对其他线程中所有 acquire 相同的 atomic 变量的 R,都是可见的。
直觉上来看,release 是释放锁。那么不能把被锁保护的东西(读和写)放到释放锁后面。另外,必须要先释放锁再获得锁。
看着很绕,实际记住两点就行:
- 对当前线程,不能和这个 R/W 重排
- 对当前变量,前面的 W 对后面的 R 可见
下面,CppReference 强调了 synchronizes-with 的含义,虽然之前提到过了,但是这里再次翻译一下
如果线程 A 上的 release atomic store 和线程 B 上的 acquire atomic load 读写同一个变量,并且线程 B 恰恰是读的线程 A 的写入。那么线程 A 上的 store synchronizes-with 线程 B 上的 load。
从线程 A 来看,所有的 non-atomic 和 relaxed atomic 写,如果它们 happen-before release atomic store,则它们在线程 B 中有 visible side-effects。也就是说,一旦线程 B 中的 atomic load 完成了,线程 B 保证能见到线程 A 写入的任何数据。当然,这个也只在 B 真的返回了 A 存储的变量,或者返回 a value from later in the release sequence 时成立。
这样的 acquire-release 同步需要这些不同的线程读写同一个变量才成立。其他的线程可能见到和这些同步线程不一样的 order。
互斥锁,例如 std::mutex,或者 atomic spinlock,是 release-acquire 同步的例子。当这个锁被线程 A release,并被随后线程 B acquire,那么线程 A 的关键段(也就是 release 前)中所有发生的一切,都在线程 B acquire 之后可见。当然,线程 B 也是在执行同一个关键段。
acquire-consume 配对:
memory_order_consume的 Loadmemory_order_release的 Store
在当前线程中的所有W,在其他线程中consume相同atomic变量的操作,如果W carry a dependency into the atomic variable,那么是对这些线程是可见的。这里涉及到consume order,可能翻译不准确。
注意,从 C++17 开始,acquire-consume 配对被 revise,所以暂时不建议使用这个。
总结注意点
- 简单来说,acquire load 不能把后面的操作往前提,release store 不能把前面的操作往后提。
- 在当前线程上,不能避免
c.store(release)被排到c.load(acquire)后面,也就是所谓的Store-Load重排。
memory_order_acq_rel
涉及 RMW 操作,例如 exchange 时,需要指定 memory_order_acq_rel。这是因为 exchange 本身同时有 load 和 store。
memory_order_acq_rel 表示即是 acquire 的,又是 release 的,类似于 acquire 和 release 的合并。那么和memory_order_seq_cst有啥区别呢?
其中一个比较是 acquire/release 需要互相配合才有效,但是 memory_order_seq_cst 对于普通的 load 都是有效的。
Demo acquire/release
可以参考下面的Demo。其中a/b/c都是 atomic variable。
1 | c = 0; |
进行下面三点分析:
- 在 Thread 1 中 release store c。因为当前线程所有的 RW 都不能重排到
c.store之后,所以1/2都不能排到3后面。 - 在 Thread 2 中 acquire load c。因为当前线程所有的 RW 都不能重排到
c.load之前,所以5/6都不能排到4前面。 - 考虑 c:
其实下面两句话是一个意思:
Thread 1 中的 release store c 要求对 Thread 2中所有的 acquire load c 是可见的。
Thread 2 中的 acquire load c 要求 Thread 1 中的所有的 release store c 对其可见,所以它能看到这个c=3这个值。
上面的讨论保证了当c的值为3之后,一定会读到a和b的值是2。无论a和b是以什么方式访存的,都不会影响最终结果。
特别地,可以用专业术语描述一下对应的行为:
- 1 Sequenced-before 2
- 2 Sequenced-before 3
- 3 Dependency-ordered before 4
- 4 Sequenced-before 5
- 5 Sequenced-before 6
Demo release/consume
如下所示,对a的赋值和对c的赋值涉及两个内存地址,所以a和c的赋值可能会进行乱序。
1 | a = 0; |
内存模型:Sequential
顺序一致性(sequential consistency, SC)要求程序中的行为从任意角度来看,序列顺序都是一致的(have single total order)。
即,该多线程程序的行为和一个单线程程序的行为一致,类似于不是并行的并发。可以类比为数据库的 Sequential 隔离等级。
SC 禁止了任何四种类型的读写重排,因此可以认为 SC 下每次读到的都是最新值。
不能太乐观
虽然 SC 是 C++ 下最强的一致性模型,但不能有“无脑 SC”就行了的看法。
出于正确性原因
从实现上讲,可以把 SC 简单理解成:
- 给 Load 加 Acquire
- 给 Store 加 Release
- 给所有 SC 的操作,赋予 global total order
它实际暗示了 SC 操作和非 SC 操作之间并没有 global total order,这是比较 tricky 的。包含两个层面:- SC 操作和非 SC 的 atomic 操作之间没有 global total order
- SC 操作和 plain 操作之间更没有 global total order
换种说法,SoF 上指出:
atomic(seq_cst)和atomic(seq_cst)始终不会重排- 在
atomic(seq_cst)附近的non-atomic甚至是atomic(non-seq_cst)形式的STORE-LOAD都可能会被重排
例如下面:- 1 和 3 的
STORE-LOAD肯定不会被重排,因为都是atomic(seq_cst) - 2 和 3 的
STORE-LOAD就可能被重排,因为 2 不是atomic(seq_cst)1
2
3
4std::atomic<int> a, b, c;
a.store(2, std::memory_order_seq_cst); // 1: movl 2,[a]; mfence;
c.store(4, std::memory_order_release); // 2: movl 4,[c];
int tmp = b.load(std::memory_order_seq_cst); // 3: movl [b],[tmp];
- 1 和 3 的
Litmus test:Store buffer
下面的代码,C++11 是可以同时见到 r1 和 r2 为 0 的。此时操作 1/2 之间并没有 global total order,3/4 也是这样。
此时可将两个 memory_order_seq_cst 直接理解为只起到了 memory_order_acquire 的作用。而只有在 x.load 读到了 x.store 的值时,x.store(..., release) 与 x.load(..., seq_cst) 才能建立 happens-before 的关系
1 | // https://godbolt.org/g/2NLy12 |
稍微进行修改,C++11 下,也是可以同时见到 r1 和 r2 为 0 的。但在 X86 上实际是见不到的,这是因为 x.store(memory_order_seq_cst) 会产生一个 Full Barrier,即 mfence。
1 | // https://godbolt.org/g/mVZJs0 |
出于性能原因
Litmus test:读写不同变量
在 C++ Concurrency in Action 中举了一个例子,使用四个线程运行下面四个函数:
- 其中两个写线程分别将 x 和 y 设置为 true
- 两个读线程分别尝试按照
x -> y和y -> x的顺序读取
以read_x_then_y为例,它循环等到读到 x 为 true,然后读取 y,如果 y 也是 true,则设置 z 为 1。
在 SC 下,可以断言无论如何 z 永远不可能为 0,也就是两个读线程至少有一个能看到 x 和 y 同时被设为 true。
1 | std::atomic<bool> x = false, y = false; |
容易看出:
- 将四个函数按照任意排序执行,那么上面的断言是正确的
注意到即使read_x_then_y在write_x前被调用也有 while 循环兜底 - 可以构造出下面的执行序列,上面断言就不成立了,即 z 会是 0 了
1
2
3
4
5
6
7Parallel 0 Parallel 1
(3)find y = 0
(2)set y = 1
(b)read until y = 1
(4)find x = 0
(1)set x = 1
(a)read until x = 1
如何选择内存模型?
- 如果只是想实现单变量的原子操作,使用 Relaxed 就行了
通过fence/barrier约束线程对变量的读写顺序
C++层面的fence及其实现
常见的 fence 包括:
- thread fence(memory/CPU barrier)
- signal fence(compiler barrier)
signal fence
signal fence 类似下面的东西,参考Wikipedia。
1 | // gcc |
gcc版本
关于这条命令可以参考SoF上的回答,以及扩展形式的 GCC 汇编介绍。
这里简单解释一下,实际上是用 asm 声明了一个空指令,但是后面的memoryclobber 会告诉编译器这个空指令可能访问任意内存,因此编译器会防止这条指令前后的访存操作跨过自己重排。并且这条指令还会将寄存器中的值 flush 回内存,并重新读取。
直接指明指令可能会访问哪些内存。比如下面语句表示可能会读x写y,并且涉及内存操作。1
2
3WRITE(x)
asm volatile("": "=m"(y) : "m"(x):) // memory fence
READ(y)MSVC版本,根据MSDN,
_ReadWriteBarrier限制了编译器可能的重排C++11标准库版本
std::atomic_signal_fence在 MSVC 上也是利用 Compiler Barrier 实现的。
一个 signal fence 的作用是- 强制单线程和该线程上的异步中断之间的顺序性
- 强制单核上运行的多线程之间的顺序性
注意到在 SMP 架构下这一点难以保证,所以对于多线程程序往往需要更强的 thread fence。
thread fence
thread fence 也就是所谓的内存屏障。根据 cppreference,它的作用是同步 non-atomic 和 relaxed atomic 之间的 order。
一个简单的例子
【Q】thread fence 是否只对 atomic 变量起作用呢?比如对于 plain(non-atomic) 变量呢?
答案是:可以起作用,但必须借助于 atomic 变量。
不妨用下面SoF上的错误的例子进行解释。这个代码中存在 data race。
1 | bool isDataReady = false; |
这个程序存在下面的问题:
while(!isDataReady)会被干成死循环,或者直接干掉
这是因为编译器不知道isDataReady可能会被其他线程改。
【Q】不过我印象里 C++ 编译器会倾向于假设while(x)不是死循环?- 理论上,因为读
isDataReady这个 bool 不是原子的,所以可能脏读 - 对
isDataReady的修改可能其他线程不可见
看评论,因为isDataReady不是原子的,所以可能这个修改可能不会立即体现到内存上。
而如果需要使用 fence/fence 同步的机制,则需要一个原子变量。这里没有,所以行为未知。
full/general thread fence
1 | // x86 |
我们需要注意的是内存屏障是相当耗时的操作,甚至还要超过原子操作,内存屏障还会干扰CPU的流水线,导致性能的降低。
MSVC 的 atomic_thread_fence实现
介绍标准库atomic_thread_fence函数的实现
1 | // MSVC |
可以发现ARM架构下就直接上_Memory_barrier()了。
而由于x86自带的acquire/release语义,除非是最强的memory_order_seq_cst,否则atomic_thread_fence等价于atomic_signal_fence。
而x86实现memory_order_seq_cst下的thread fence则比较奇特,为啥不直接插入一个MemoryBarrier(),而是利用了一个原子操作呢?结论是_Atomic_exchange_4这个函数会自动生成一个LOCK XCHG,这个指令是一个full memory barrier,类似于mfence。
当然,SoF上老哥还提到了这个实现很傻逼,不如直接用mfence。有人说这是因为32位的CPU上不支持mfence,但是老哥自己在godbolt验证了在64架构下的GCC9已经能编译出mfence了。
进一步的,在这篇文章中,答主列出了四种实现Seq的方法,并且指出GCC用了第一种,MSVC用了第二种,虽然有bug(2012版本),所以MSVC在这块的实现确实是不需要借鉴的。
- LOAD (without fence) and STORE + MFENCE
- LOAD (without fence) and LOCK XCHG
- MFENCE + LOAD and STORE (without fence)
- LOCK XADD ( 0 ) and STORE (without fence)
acquire/release thread fence
下面说明acquire/release fence。需要注意,这两个模型即使组合起来也不能禁止其前面的W和后面的R重排,可以看Store-Load章节。
注意,这里的重排到前和后,并不是针对的fence,而是针对的fence周围的read和write。
【Q】这个是对当前线程,还是所有线程而言的?
【Q】fence中涉及fence,fence前面的rw,fence后面的rw三个。这里不仅是前面的不能排到后面去,也包括了后面的不能排到前面来?看起来是的,以LoadStore乱序为例,
acquire fence
1 | std::atomic_thread_fence(std::memory_order_acquire); |
fence后面的RW不能与fence前面的R重排。也就是后面的RW不能重排到原本在fence前面的所有R前。
即不能重排load-store,load-load。
例如下面的是不行的,其中==表示acquire fence。
load-store
总共3!中顺序,除了原始的哪一种,其它所有的顺序都不允许。
直觉来看,如果允许 load-store 会有问题。例如如果 load 排到 store 后面,那么读到的就可能是一个后面写入的值。可以结合之前的atomic load 和 store 来理解。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19R1 W2
== -x-> R1
W2 ==
R1 W2
== -x-> ==
W2 R1
R1 ==
== -x-> W2
W2 R1
R1 R1
== -x-> W2
W2 ==
R1 ==
== -x-> R1
W2 W2load-load
1
2
3R1 R2
== -x-> ==
R2 R1
release fence
1 | std::atomic_thread_fence(std::memory_order_release); |
fence前面的RW不能和fence后面的W重排。也就是前面的RW不能重排到原本在fence后面的所有W后。
即不能重排load-store,store-store。类似于 acquire fence,它同样禁止 load-store。
fence/atomic同步、fence/fence同步
进一步看一下cppreference
Fence-atomic synchronization
在下列条件下,线程 A 中的一个 release fence F synchronizes-with 线程 B 中的 atomic acquire 操作 Y,如果:
- 存在一个任意 memory order 的 atomic store X
比如下面的 X store - Y 读取 X 写的值,或者如果 X 是一个 release 操作且这个值被 release sequence headed by X 写入
- 在 thread A 中,F sequenced-before X
在线程 A 中,F sequenced-before X。
这个情况下:
- 考虑线程 A 中所有的非原子及 relax atomic store 操作
比如 α。 - 如果它们 sequenced-before F
在线程 A 中,α sequenced-before F。 - 那么将 happen-before
如下所示,所有的 α happen-before β。 - 线程 B 中 Y 之后的所有对同一位置的非原子及 relax atomic load 操作
比如 β。
1 | thread A thread B |
Atomic-fence synchronization
An atomic release operation X in thread A synchronizes-with an acquire fence F in thread B, if
- there exists an atomic read Y (with any memory order)
- Y reads the value written by X (or by the release sequence headed by X)
- Y is sequenced-before F in thread B
In this case, all non-atomic and relaxed atomic stores that are sequenced-before X in thread A will happen-before all non-atomic and relaxed atomic loads from the same locations made in thread B after F.
Fence-fence synchronization
A release fence FA in thread A synchronizes-with an acquire fence FB in thread B, if
- There exists an atomic object M,
- There exists an atomic write X (with any memory order) that modifies M in thread A
在thread A中有个对atomic对象M的atomic写(但是order不论)。 - FA is sequenced-before X in thread A
在这个写之前放个FA(acquire fence)。 - There exists an atomic read Y (with any memory order) in thread B
在thread B中有个对atomic对象M的atomic读(但是order不论)。 - Y reads the value written by X (or the value would be written by release sequence headed by X if X were a release operation)
- Y is sequenced-before FB in thread B
在这个读之后放个F(release fence)
In this case, all non-atomic and relaxed atomic stores that are sequenced-before FA in thread A will happen-before all non-atomic and relaxed atomic loads from the same locations made in thread B after FB.
那么thread A中所有FA之前的non-atomic/relaxed操作,一定happen-before thread B中所有FB之后的non-atomic/relaxed操作。也就是 α happend-before β。
1 | thread A thread B |
thread fence 和 barrier 指令间的关系
有一种理解对内存屏障进行如下的区分:
- Store Barrier强制所有屏障前的store指令,都在屏障指令执行之前被执行,并drain store buffer的数据。
- Load Barrier强制所有屏障后的load指令,都在屏障指令执行之后被执行,并且一直等到load缓冲区被该CPU读完才能执行之后的load指令。
- Full Barrier同时具有Store和Load Barrier的全部作用。
但根据前面对sfence/lfence/mfence的介绍,其实sfence和lfence都不能对应Store/Load Barrier。
Store-Load乱序问题
在前面的讨论中提到了x86的Store-Load乱序问题,对于x86,Loads May Be Reordered with Earlier Stores to Different Locations,但对于相同地址则不会乱序。
在这篇博文中记录了一个有关Store-Load乱序的实验。在实验中,X的写操作可能被延迟到Y的读操作之后,尽管我们插入了compiler barrier。
这时候需要一个full/general memory barrier,也就是实现让它前面所有的Load/Store操作对它后面的Load/Store操作都是可见的,包括了禁止Store-Load类型的乱序。在同一篇博文中指出可以使用插入一个mfence,以实现full/general memory barrier。
在C++中,可以插入一个atomic_thread_fence(memory_order_seq_cst),它可以始终产生一个full memory barrier。
因此在x86上至少要对LOAD/STORE其中的一个加上MFENCE,或者用一个LOCK指令,而这也实现了类似memory_order_seq_cst的效果。在章节内存模型的实现中还有更多说明。
下面的代码不一定是等价的
1 | atomic<int> x, y |
通过fence和barrier实现同步
一般来说,如果需要实现同步,则直接使用原子变量(atomic variable)会安全很多。但其实通过加入 Compiler Barrier 和 Memory Barrier 是可以实现六种内存模型的 atomic store 和 atomic load 的。
atomic variable VS atomic fence
我们可以用fence替换atomic store/load。
可以结合下面两张图对比
| atomic variable | atomic fence |
|---|---|
 |
 |
Acq/Rel
在SoF中指出acquire/release 一个 atomic variable 可以通过在 relax 后面加一道对应 memory order 的 thread fence 来替换。
这里注意,fence 加在 load 后面,store 前面。可以从 fence 禁止重排的类型来理解。
1 | // 对于 load |
但其实这里的替换未必是等价的:
- A memory barrier with acquire semantic establishes stronger ordering constraints. Although the acquire operation on an atomic and on a memory barrier requires, that no read or write operation can be moved before the acquire operation, there is an additional guarantee with the acquire memory barrier. No read operation can be moved after the acquire memory barrier.
尽管 atomic acquire 操作,或者 acquire 的 memory barrier 要求没有 RW 操作可以被移动到这个 acquire 之前。但 aquire memory barrier 还有一个额外的保证,也就是没有读操作可以被移动到这个 aquire 之后。 - The relaxed semantic is sufficient for the reading of the atomic variable var. The std::atomic_thread_fence(std::memory_order_acquire) ensures that this operation can not be moved after the acquire fence.
这个感觉和上面一个意思
此外,如果不显式加入 fence 的话,编译器可以视情况生成等价的更好的代码。
而在x86等强内存模型架构cpu上,也不一定生成fence,例如单独的atomic_thread_fence(memory_order_acquire)就可以简化为nop。
SeqCst
而memory_order_seq_cst则需要额外的MFENCE或者LOCK,这个之前已经说过。
下面的代码是等价的
1 | if (var.load(std::memory_order_acquire) == 0) |
无等待
无等待(Wait-Free)是比锁无关更高层面的并发。无等待指的是程序中的每个线程都可以一直运行下去而不阻塞。
无锁编程实战
读写共享对象
来自 yubai 大佬的共享对象的并发读写。
多个线程对下面这个对象进行读写。显然,这个超过了128bit,没法一次原子操作来搞定。
1 | struct GConf |
- 读写锁
容易读者和锁者互相阻塞。 - COW 第一版
这个也介绍过,在更新的时候原子地 swap 指针。
一个要点是,旧的 Version 不能立刻被析构,而应该维护一个引用计数。
但我们很快想到,类似于实现单例的过程,取对象指针,以及根据指针读取该对象的引用计数并判断要不要 swap 这两个操作并不是原子的。 - COW 第二版
一个简单的办法是将上面两个阶段用锁保护起来。这个锁是全局的。 - COW 第三版
现在需要设计一个无锁的办法。 - HazardPointer
使用内存模型解决双重检查锁定模式(DCLP)存在的问题
在之前的章节中,我们曾经提到过双重检查锁定模式中存在的问题,对此文章Double-Checked Locking is Fixed In C++11指出我们可以通过适当的 fence 或者 atomic store/load 语义来解决。
使用atomic store/load语义
对于下面的代码,解答几个问题:
为什么第一个 load 至少是 acquire 的?
因为m_instance.load(acquire)一定能看到m_instance.store(release),所以也一定能看到tmp = new Singleton。
如果都是 relaxed,那么锁是约束线程间行为的最后一道屏障了。那么m_instance.store可能会被 reorder 到锁的作用域退出之后,就会出现下面的情况。1
2
3
4
5
6
7
8
9
10
11
12T2: if (tmp == nullptr) {
T2: }
T2: } // 锁被释放了
T1: Singleton* tmp = m_instance.load(std::memory_order_acquire);
...
T1: std::lock_guard<std::mutex> lock(m_mutex);
...
T1: tmp = new Singleton;
T2: tmp = new Singleton;
T2: m_instance.store(tmp, std::memory_order_release);为什么这里只需要acquire和release就够了?
为什么第二个load是relaxed的?
首先这里有个锁保护着,只有一个线程能执行第二个load。
然后第二个load是Sequenced-before后面的store的。为什么还要锁?
这个之前讲过,tmp = new Singleton不是原子的。
1 | std::atomic<Singleton*> Singleton::m_instance; |
使用fence
主要是几点:
- 为什么对m_instance的读写仍然要是原子的?
- 在load后和store前插入fence
1 | std::atomic<Singleton*> Singleton::m_instance; |
上面的代码可以对应到下面的图上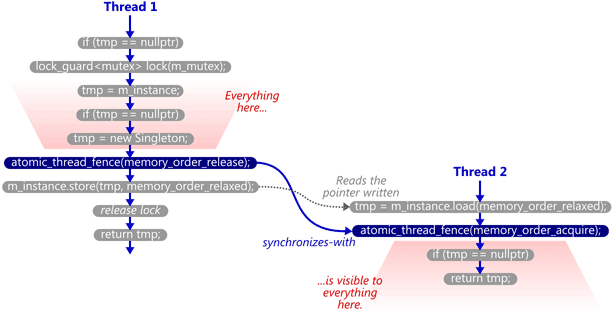
基于CAS实现自旋锁
摘录自博客。
可以通过 i++ 的方式来检验对错。
1 | class SpinLock { |
上面的实现比较基础,但是有个问题,其他线程可以直接调用unlock来解锁。事实上,我们可以加一下线程唯一性的东西,保证只有持有锁的线程才能解锁。
此外,在下面介绍如何通过std::atomic_flag实现自旋锁。
无锁队列
被移动到Lockfree Queue。
多线程并发模型
在本章节中将讨论多线程编程中变量共享与消息传递机制。
共享 vs 通信
通过共享来通信,和通过通信来共享,是并发编程中的两种不同模式。
虚假唤醒(spurious wakeup)
条件变量的通信模型可能导致虚假唤醒/伪唤醒(spurious wakeup)的问题。
虚假唤醒指的是在条件变量上等待的线程被唤醒之后,却发现条件不满足。这样看下来,似乎线程毫无缘由地就被唤醒了。
为什么会发生这种现象呢?考虑:
- 条件
condition被满足 - 线程 A 被唤醒
- 线程 B 被唤醒
- 线程 B 获得锁,从 wait 返回,并重置了
condition
注意,即使是虚假唤醒的情况,cv.wait也是在获得锁之后再返回 - 线程 A 尝试获得锁并从 wait 返回,发现 condition 已经不满足了
可以想到,如果条件满足了,并且只能被一个线程消费,我们整个 notify_all() 把大家都叫起来,肯定会虚假唤醒,其实也就是所谓的惊群效应。
但是如果我们每次都 notify_one(),是不是就不会发生这样的事情呢?其实并不是这样,在很多 notify_one() 的实现中,会唤醒不止一个线程。譬如:
- 在多处理器系统和接收Linux信号时,出于性能因素允许了虚假唤醒存在
- APUE 指出
pthread_cond_signal函数可能唤起多个线程。 - 当等待队列中的Linux线程收到一个系统信号时,会得到虚假唤醒
- Jon Skeet 大神指出其深层次原因是没有任何的保障是一个被唤醒(awakened)的线程一定会被调度(scheduled)
复现虚假唤醒
在SF上记录了一番实验,强行产生虚假唤醒。
1 | con_var.notify_one(); |
可以发现在 notify 和 unlock 两个过程之后的两秒内消费者线程已经被唤醒了,但在拿到锁和条件变量后它发现其实 condition 值并不为 true ,这就产生了一次虚假唤醒。
解决方案
可以将 wait 包裹在一个 while 循环里面,如 wait_for_event 所示。
惊群效应
惊群效应是指多进程在 wait 的时候,如果希望唤起特定的几个,或者不清楚需要唤醒几个,就得使用notify_all()唤醒全部线程。但是最终大部分的唤醒都是无效的,甚至只有一个线程能够真的获得锁。
- notify_one 的常见场景
accept 调用中,当多个线程的套接口 listen 同一个 fd 时,内核只 notify 等待队列最顶部的套接口。 - notify_all 的常见场景
epoll,内核不知道究竟有多少个线程需要被唤醒。
惊群效应的影响是造成性能浪费,例如线程调度造成的上下文切换开销。
一些解决惊群的方案包括:
epoll
Linux 网络内核对 accept 的优化
我们知道,单线程listen/accept往往不能很好处理高并发的连接。因此通常会用多个线程去accept同一个套接字。
如下所示,每一个子进程在 fork 之后,都会去accept,并且send一些数据,然后关闭连接。但是在 Linux 早期版本中,当新的连接到来时,所有睡在accept上的进程都会被唤醒,但是因为只有一个进程最终能accpet成功,这也是惊群现象。
后续版本中,引入了WQ_FLAG_EXCLUSIVE解决该问题。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
int main()
{
int fd = socket(PF_INET, SOCK_STREAM, 0);
int connfd;
int pid;
char sendbuff[1024];
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
serveraddr.sin_port = htons(1234);
bind(fd, (struct sockaddr*)&serveraddr, sizeof(serveraddr));
listen(fd, 1024);
int i;
for(i = 0; i < PROCESS_NUM; i++)
{
int pid = fork();
if(pid == 0)
{
while(1)
{
connfd = accept(fd, (struct sockaddr*)NULL, NULL);
snprintf(sendbuff, sizeof(sendbuff), "accept PID is %d\n", getpid());
send(connfd, sendbuff, strlen(sendbuff) + 1, 0);
printf("process %d accept success!\n", getpid());
close(connfd);
}
}
}
int status;
wait(&status);
return 0;
}SO_REUSEPORT/SO_REUSEADDR
见UDP套接口编程
条件变量 Condition Variable
C++ 中的 condition_variable
锁 lock_guard 和 unique_lock 能够保证线程之间的互斥访问临界资源,但是不能控制这些访问的先后顺序。自然而然地可以想到可以用锁维护一个共享变量记录状态,以实现线程间同步的措施,例如在生产者/消费者模型中用它来描述产品数量。一个比较 naive 的方式是 poll 轮询,注意在实现时仍然是需要锁的,否则可能两个互相竞争的线程同时获得 flag。
1 | bool flag; |
另一种更好的方法是利用条件变量。条件变量(condition variable)利用共享的 mutex 进行线程之间同步,可以理解为实际上是帮用户做了轮询。即维护一个等待列表,线程不是用轮询去 pull,而是等待条件变量的 push 也就是唤醒:
- 当某一个线程所需要的条件不满足时,用户调用
wait阻塞在 CV 上,此时用户必须持有互斥量
wait 的作用是:- 解锁互斥量
这很显然,不然生产者怎么干活呢? - block 当前线程
- 将当前线程放入等待队列上。该线程后续将会被
notify_one/notify_all唤醒。
注意,wait 方法在返回后,会获得锁。这也是符合语义的,因为调用 wait 时本来就需要持有互斥量,不然是 UB。
- 解锁互斥量
- 拥有锁的线程在退出临界区时使用
notify_one/notify_all发出信号通知条件变量,条件变量会唤醒一个/所有正在等待的线程。
不同于其他语言,C++ 中的 wait 还支持传入一个 predicate 参数 stop_waiting。在 wait 结束后,会用 stop_waiting 去检查一下条件是否真的满足。如果不满足说明是虚假唤醒(spurious awakening),会继续 wait。实际上等价于下面的代码。
1 | template< class Predicate > |
条件变量的用法
使用条件变量等待事件通常是类似下面的形式,容易发现期间需要解锁,所以这里只能用 unique_lock 而不能用 lock_guard。
1 | void wait_for_event() |
注意先修改 condition,再 cv.notify_one 和 cv.notify_all。这也是为了保证睡眠线程在收到信号后能够及时观察到条件满足了。
notify 时是否要加锁
理论上 notify 的时候不一定要拥有锁,例如下面 cppreference 中的 demo 就没用锁保护
1 | void signals() |
但需要注意几点问题:
- 修改 condition 必须要加锁
也就是这里 i = 1 必须要用锁保护起来 - 尽管 notify 可以不上锁,但这可能导致 less optimal scheduling of threads,并且你反正已经上过一次锁了。
如下代码展示了不保护 condition 如何导致错误,可能在 wait 部分在检测到 condition 不满足准备 pthread_cond_wait 前,另一个线程修改 condition 并 pthread_cond_signal,这样进入 pthread_cond_wait 的 wait 部分代码就会丢失这次的 signal。
所以在 signal 部分加锁,让两个 Process 不是 interleave 地执行。
1 | Process A Process B |
为什么需要维护一个 condition 变量
不过即使为 signal 部分上锁还可能丢失信号。原因是生产者和消费者竞争同一把锁虽然能够保证 wait 和 signal 是串行的顺序,但可能整个 signal 过程都在 wait 过程前面。陈硕的博客中得到 Case 2 就是这种情况
这一现象广泛出现在使用边缘触发(Edge triggered)机制的程序中,例如 Linux 的信号,pthread_cond_ 系列。相对于水平触发,边缘触发只会唤醒已经等待在 wait 上的线程(可以参考Python的Condition条件变量的实现),因此可能出现丢失信号的问题。例如当 notify 操作早于 wait 操作时,这个 notify 就会丢失了。其实这个也可以认为是虚假唤醒的一种情况。
解决方案就是用一个 condition 来记录。当一个 signal 先于 wait 时,它会设置 condition 为 true。在 wait_for_event 时,有两处地方判断 condition:
- while 的条件
用来防止虚假唤醒,同时也用来检查是否已经有一个前面的 signal 触发过了,还没来得及被消费。 - cv.wait 的 predicate 参数
用来防止虚假唤醒
condition variable 的错误用法
程序在条件不满足时,释放锁并阻塞在 CV 上进入睡眠,这个过程必须是原子的。考虑在释放锁之后另一个线程获得锁并发送了 signal,但此时本线程上还没有来得及阻塞在 CV 上,这个信号就不能被本线程收到了。
几个有关 CV 和 mutex 之间联系的问题
只用 mutex 行不行
我认为这是因为从逻辑上来讲,CV提供了一种新的同步原语。如果使用mutex来进行同步,其实也是可以的。如下面代码所示,两个线程竞争一个mut,以类似轮询的方式来获得同步,不仅很耗资源,而且从逻辑上不够整齐。而CV把consumer的轮询变成了阻塞wait,以provider的通知notify来唤醒,节省了资源,从逻辑上也有了一个完整过程的抽象。1
2
3
4
5
6
7
8
9
10
11def provider(mut):
while 1:
lock(mut)
count++
unlock(mut)
def consumer(mut):
while 1:
lock(mut)
if count:
count--
unlock(mut)只用 condition variable 行不行
一方面,condition是一个临界变量,必须要用锁来保护。所以之前在signal_event中修改 condition 是带锁的。
另一个方面,cv.wait对应的一系列步骤必须要是原子的,否则会造成丢失 signal 的问题。所以也需要用锁保护,在wait中再解锁。
在下一章节中会提到各种 condition variable 的错误用法,我们会详细讨论这两个问题。关于使用CV时使用锁的错误用法在陈硕大牛的博客中还指出了更多的例子,其优化点很多也是为了解决可能的丢失信号的问题。condition variable 是全局一份,还是是生产者和消费者各自创建,通过 mutex 关联
wait 和 notify 需要作用在条件变量,而不是 mutex 上。并且这个条件变量需要在内部维护所有的waiter。我们可以看Python的Condition条件变量的实现来了解这一点。
做到这一点,既可以是全局一份,也可以是各自创建。
信号量的实现
在 POSIX 和 Linux 中分别提供了两种信号量的实现方式。
也可以通过 mutex+cv+counter 来实现信号量。
事件
Windows 内核编程中出现了事件,可以用来替代条件变量的使用。
相比使用条件变量显式等待,事件机制将这个 wait 前置,将处理函数直接 register 给一个代理,当需要 notify 时,代理会直接调用这个处理函数。
事件和回调有什么区别?
- 事件机制更类似于对回调的一种封装,能够更好地实现模块化和组件化
- 事件机制避免阻塞
- 回调不一定是异步的。
基于线程的异步调用
std::thread
std::thread 是实现并行最 de facto 的方式了。
区分 std::thread 和线程实体的生命周期
线程实体是由操作系统管理的,它不等同于 std::thread 对象。特别地,std::thread的生命周期是不同于线程实体的。当主线程退出时所有的子线程释放,或者当子线程执行完毕时子线程释放。而 std::thread 对象遵循所有 C++ 对象的生命周期。
std::thread 是由程序员管理生命周期的,程序员应当在 join() 或者 detach() 后释放 std::thread。如果强行析构一个 joinable 的 std::thread 会导致异常 terminate。
程序员可以通过 std::thread 控制线程实体,直到调用 detach() 之后。而一旦 detach 之后,原有的线程就和 std::thread 无关了,*this 不再管理任何线程。此时 std::thread 对象即使析构也无碍于线程实体。
让子线程主动退出
试图从主线程 fire 掉子线程一个坏主意。如果希望某个线程的生命周期等同于某个对象,则可以在该线程的loop里面去跟踪一个 flag,这个 flag 可以是全局变量,也可以作为参数传入或者直接捕获。当对象需要析构时,设置这个flag使得线程内部的loop检测并最终主动退出,此时只要在主线程中join这个线程即可。
需要注意,在主线程退出前,需要保证所有子线程都退出。否则在主线程退出的过程中可能会析构全局变量,如果此时还有子线程访问该全局变量,则会 Segmentfault。例如 https://github.com/pingcap/tiflash/issues/8060。
注意线程带来的开销
从这个问题可以看出,Linux 创建线程的开销并不是那么小,创建一个线程去处理,相比直接处理该逻辑,可能慢10000倍。所以如果有一堆小的处理逻辑,使用线程池是一个好主意。
其他注意事项
std::thread不能复制,只能移动。std::thread大概率不会被pooling。
线程池
线程池的产生是为了解决维护线程生命周期所带来的开销的问题,同时节约操作系统资源。一个线程池维护多个线程,当任务到来时在池中取出一个线程来执行这个任务。线程池可以动态地进行扩展。
一般对于 IO 型的任务,维护线程池在 2x 或者 2x+2的规模,而对于计算型的任务,盲目加线程是不正确的。甚至对于一些HT超线程的架构线程还要少一点会更好。具体是多少,需要 profile 来看。
工作队列/任务队列
注意这里并不是特指 Linux 中的特定数据结构,而是指一种通用的编程概念。
工作队列(work queue)/任务队列(task queue)维护一组工作线程,调用者将异步任务注册到工作队列中,工作线程竞争运行这些异步任务。由此看到工作队列的实现依赖一个线程安全的队列,可以用 CV 做一个简单的生产者消费者来实现。
使用工作队列需要注意:
- 死锁/优先级反转
例如所有正在执行的任务都阻塞等待锁 A,但持有锁A的任务却因为没有空余的线程而在队列中空等。 - 线程泄露
例如在异步任务中触发了异常,那么控制流就可能跳出 loop 循环,导致该线程无法参与到后面的计算任务中。 - 过载
工作队列模型和其他异步模型的比较
- 与线程池相比
线程池存在一些显著缺点,例如当调用者请求一个空闲进程执行异步任务,单线程池中可用线程为空的时候,此时无论是扩展线程池加入新线程或者等待某一个线程执行完任务重新变为空闲,都会导致调用者所在线程的阻塞。而工作队列能够避免这样的问题。 - 与 future 相比
和线程池一样,工作队列解决一系列的异步计算问题。相比 future,工作队列需要额外考虑任务的调度、负载均衡等问题。
我觉得 future 实际上是一种异步模型。而线程池等更类似于是 future 的一种 executor。
future 模型
条件变量 Condition Variable 的一个重要的应用就是生产者/消费者模型,但对于一些平凡的情况,消费者只等待**一次(one-off)**来自生产者的结果。一个最简单的做法是启动一个计算线程,或者从线程池中取出一个线程去执行,然后同步或者异步地获取它的结果,不过 std::thread 不能直接提供获取返回值的方法。当然,可以使用全局变量、传入指针、回调函数这些做法,这些方案是完全异步的。另一个做法是使用 future 来获取异步任务中的结果。
future 的概念
future 是异步编程中一个非常通用的概念,它表示一个可能还没有被计算完成的值。在 C++ 中被实现为 std::future,在 Python3 中被实现为 concurrent.future,在 Rust 中被实现为 trait Future。尽管 future 的概念在大部分语言中都涉及,但是它们仍然有差别,在 Rust - A CPP Programmer’s Perspective 的《取消安全》章节中,我就介绍了 Rust 的 Future 和 C++ 的 std::future 的本质区别。因此,本文中的 future 机制,围绕 C++ 展开。
std::future 通常是下面提到的 async、promise 等异步机制返回给主线程的一个“句柄”。当需要获取到结果时,可以通过 future::get() 来获取。此时如果异步任务已经完成,则该函数立即返回,否则主线程会阻塞在future::get()上。有点像调用 future.get 的线程在 join 计算线程。
特别地,std::future 也可以调用 wait()、wait_for(const chrono::duration<Rep,Period>& rel_time)等函数进行主动等待。
wait_for 会返回三种状态:
future_status::ready表就绪future_status::timeout表超时future_status::deferred表示这个 future 对应一个 deferred function。即此时还没有执行这个异步任务,我们将在下节进行详细说明。
当多个线程访问 std::future 时,要锁来保护线程安全。但这样的做法没有意义,因为 std::future 只能被 get 一次。如果需要 get 多次,则 C++ 中还提供了 std::shared_future,相比 std::future,它是可以复制的。多个线程可以通过一个 std::shared_future 来跟踪异步任务的结果。需要注意的是,为了保证线程安全,需要对每个线程维护一份 std::shared_future,这个每个线程可以操作自己的一份。
async
std::async 被用来实现一次异步调用。
1 | int main() |
std::async 有两个重载。第二个重载主要是多一个 std::launch 类型的参数,称为 policy,是一个 bitmask 类型:
std::launch::deferred表示异步调用是个 deferred function,它将延迟到对 future 对象调用.wait()或.get()再执行。std::launch::async表示在一个独立线程中运行。
默认 policy 是 std::launch::deferred | std::launch::async,表示这两个二选一,由具体实现来决定。但如果 bitmask 中啥都没有设置,则是 UB。
std::async 能够接受函数指针和函数对象的左值、右值、引用和 std::ref,也能够通过类似 std::bind 一样的机制以引用、std::ref 等方式传入对象的上下文。
优先使用 async 等机制替代 std::thread
相比裸线程,async隐藏了底层的细节,这样可以更关注异步逻辑本身。特别地,它有可能会**使用线程池进行优化(pooling)**,从而避免每次都创建新线程。
此外,裸线程还存在回调地狱(callback hell)的缺点,使用 async 或者后面提到的 future.then 甚至 co_wait 等机制能够让代码更加平展。
future 析构的阻塞问题
如不关注 std::async 的返回值,可能写出下面的代码。即不将 std::async 返回的结果绑定到某个变量或者进行移动。
1 | // https://zh.cppreference.com/w/cpp/thread/async |
那这返回的 std::future 会在整个表达式 1 执行完之后被析构,而这个析构会阻塞到异步操作 f() 结束。所以 std::async 不能被简单地当做 std::thread 来使用。
SoF 中也提到这是一个争议问题,但至少在 C++11 中,future 的析构函数可能会阻塞线程。
此外,我们也不能将返回值通过回调传出去,当然后续可以通过 future.then 实现。
异常
std::async 会 cache 住所有的异常。
wait_for
在 Rust中,trait Future 中的 poll 方法可以返回当前任务的结果,或者 Pending 表示目前还在计算中。在 C++ 中 get 会直接阻塞地获取结果,而不会返回 Pending 这样的状态。因此可以通过下面的方法来检查 future 是否已经 ready,然后只有在 future ready 的时候再取结果,否则就可以干别的。
1 | if (fut.wait_for(0) == std::future_status::ready){ |
此外,wait_for 还可以被来检查某个 future 是不是被 defer 的
1 | auto fut = std::async(func); |
packaged_task
std::packaged_task 可以封装所有 Callable 的对象。它有点类似 std::function 函数对象,但它不能被复制。
不同于 std::async,需要手动 std::packaged_task 来执行它持有的 Callable。因此这也允许我们使用不同的 Executor,例如:
- 可以自己指定线程池来执行,而不是像
std::async一样是一个盲盒 - 也可以将它移动到某个
std::thread中,起一个单独的线程来执行
1 | int f(int x, int y) { return std::pow(x,y); } |
std::packaged_task 的另一个用法是将某个任务打包,然后派发给另一个线程执行。
std::packaged_task 有两种执行方式:
operator()
make_ready_at_thread_exit
表示只有在当前线程退出,并且 thread local storage 都析构之后,再将返回的 future 的 ready 设置为 ready。
例如下面 cppreference 提供的这个 demo。如果使用operator(),则在 my_task 执行完之后,result 立刻变为 ready。如果使用 make_ready_at_thread_exit,则需要在 worker 线程退出之后,result 才会变为 ready。因此可以看到此时在 worker 线程中打印 result 都是 timeout 而非 ready。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22void worker(std::future<void>& output)
{
std::packaged_task<void(bool&)> my_task{ [](bool& done) { done=true; } };
auto result = my_task.get_future();
bool done = false;
my_task.make_ready_at_thread_exit(done); // execute task right away
// my_task(done)
std::cout << "worker: done = " << std::boolalpha << done << std::endl;
auto status = result.wait_for(std::chrono::seconds(0));
if (status == std::future_status::timeout)
std::cout << "worker: result is not ready yet" << std::endl;
output = std::move(result);
}
int main()
{
std::future<void> result;
std::thread{worker, std::ref(result)}.join();
auto status = result.wait_for(std::chrono::seconds(0));
if (status == std::future_status::ready)
std::cout << "main: result is ready" << std::endl;
}使用 make_ready_at_thread_exit
1
2
3worker: done = true
worker: result is not ready yet
main: result is ready使用 operator()
1
2worker: done = true
main: result is ready
std::packaged_task 还提供了 reset 这个方法,方便复用。
promise
在上面的两种派发任务-等待获取结果的模型中,主线程是作为等待任务结果的一方,而将执行任务的异步线程则是产生结果的一方。std::future对象由调用者(这里是主线程)持有,调用者会使用std::async或者std::packaged_task等启动一个任务,并且在需要结果时调用返回的 future 对象的get方法。对于异步线程来说,调用者对自己是透明的,只能通过执行完任务正常返回完成向调用者同步。
但在使用std::promise时,异步线程需要显式向调用者设置值std::promise::set_value()或传递异常std::promise::set_exception()。
因此promise实际上为被调用者提供一个显式向调用者同步的方法。被调用者显得更加主动,而且它现在可以返回一个异常。
基于future组织链式调用
future.then
future模型有一个美中不足就是最后get时候归根到底是一个同步的过程,并可能会阻塞。相比之下,如果我们自己创建线程或者线程池,然后通过回调来返回值,则更为灵活,是完全的异步,当然也可能带来回调地狱的问题。
能不能两相结合呢?。实际上有一个提案称为future.then就是用来解决这个问题的。其风格类似于CPS,利用了回调链的机制避免了调用future::get()形成阻塞。
future.then 目前还没有进入 C++ 标准,因此 C++ 中目前还需要借助于线程池、事件或者 IOCP 的方式来实现异步。
await
future.then机制降低了流程操控的复杂度,不过写起来仍然很繁琐,而且存在回调地狱的问题。相比之下,await 能够拍平这些回调函数,让整个异步程序看起来和同步一样。
在链式调用的过程中,整个流程难以在中间直接abort,为此Rust先后提出了try!和?这样的机制。
C++也引入了co_await、co_yield、co_return三个函数,但截至目前它们尚未进入C++标准,但这种由C Sharp流行开来的异步编程范式其实十分优雅,我们将在一个单独的专题进行讨论。
多进程并发模型
通信和共享内存
常见的并发模型有两种思路:
- 通过共享内存来通信
多个线程通过锁或者原子操作对变量进行有序访问。
先前讨论了 future 等基于线程的共享内存的模型,它们在多线程环境中非常实用。可以发现在 future 等模式中信息的交互是一次性的,即调用者在启动异步任务后很难再去操作异步任务,而异步任务更是看不到调用者。 - 通过通信共享内存
包含 Communicating Sequential Process(CSP) 和 Actor 模型,在多进程情况下会更得心应手。
Actor 模型
Actor 模型围绕具名节点,称为Actor展开,消息从一个 Actor 直接发送到另一个 Actor,而并不需要通过诸如 Channel 的桥梁。特别地,Actor 是与线程无关的,一个线程上驱动多个 Actor。更进一步地,Actor 的消息传递也是异步的,消息的发送和接受可以在任意时间发生。
Actor 之间进行严格地隔离,实现 Share nothing 的机制,每一个 Actor 同时只能处理一个消息,多余的消息会存放在 Mailbox 里面。这样实际上消息的处理过程是独占的。
CSP 模型
相比 Actor,CSP 模型围绕一个中间桥梁,例如 golang 中的 Channel。不同的节点向对应的 Channel 获取或者发送消息,因此在耦合性上要比 Actor 模型松一点。相比 Actor 模型,CSP 模型要求发送方在接收方准备好接受消息时才能发送消息,所以同步性要更强一点。
以 golang 为例,Channel 一般具有4个基本操作:
- 创建
c = make(chan int, buffer_size) - 发送
c <- - 接受
<- c - 关闭
close(c)
Channel 的 C++ 实现
这篇文章中讲述了使用 C++ 模拟 golang 中的 Channel 的一个方案。首先 Channel 一个最基础的功能就是收发消息,这个可以通过一个队列来实现。
并发编程中的基础架构
在设计高性能的并发代码时,需要注意以下几点:
- 充分利用局部性假设,是同一线程中的数据紧密联系
- 减少线程上所需的数据量
- 让不同线程访问不同位置,避免伪共享,这里也是将内存分配对齐到缓存行大小的一个重要原因。
响应式(reactive)架构
网络编程相关
Reference
- https://coolshell.cn/articles/8239.html
- https://www.zhihu.com/question/24301047
大家对于memory order的理解,我在修订文章时,采用了一些更为简洁的说法 - https://preshing.com/20130922/acquire-and-release-fences/
2013年的老文章 - https://acg.cis.upenn.edu/papers/dac11_litmus.pdf
有关litmus test - https://preshing.com/20140709/the-purpose-of-memory_order_consume-in-cpp11/
preshing对memory_order_consume的讲解 - https://sites.utexas.edu/jdm4372/2018/01/01/notes-on-non-temporal-aka-streaming-stores/
对Non temporal store的讲解 - https://www.modernescpp.com/index.php/acquire-release-fences
对atomic thread fence的讲解,acquire和release - https://www.zhihu.com/question/24301047
如何理解memory order。以及TSO的论述 - https://ljalphabeta.gitbooks.io/a-primer-on-memory-consistency-and-cache-coherenc/content/%E7%AC%AC%E5%9B%9B%E7%AB%A0-total-store-order%E5%92%8Cx.html
讲解TSO模型 - http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2013/n3710.html
- http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p1217r0
以上两篇,讲解out of thin air - https://www.cl.cam.ac.uk/~pes20/cpp/notes42.html
这个讲解out of thin air更易懂 - https://zhuanlan.zhihu.com/p/31386431
知乎对happens before和sync-with的讲解,我觉得讲得不好 - http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.07.23a.pdf
一篇有关 MESI 的文章 - http://concurrencyfreaks.blogspot.com/2013/05/lock-free-and-wait-free-definition-and.html
http://ifeve.com/lock-free-and-wait-free/ 的原文

