Spark是MapReduce的下一代的分布式计算框架。相比更早期的MapReduce的Job和Task的两层,Spark更为灵活,其执行粒度分为Application、Job、Stage和Task四个层次。本文写作基于Spark 2.4.4版本的源码。
【TLDR】本来写文章确实是简练清楚为最佳,不过我发现Spark架构实在是很庞大,其中涉及到的一些架构知识我觉得都很有启发意义,因此这篇文章就被我写得很长。为了简化论述,我将部分细节放到了源码中作为注释,因此正文中是主要内容。
【注】本篇文章经授权已被腾讯技术工程知乎号和微信收录。
Spark Core
RDD
RDD(Resilient Distributed Dataset),即弹性数据集是Spark中的基础结构。RDD是distributive的、immutable的,可以存在在内存中,也可以被缓存。
对RDD具有转换操作和行动操作两种截然不同的操作。转换(Transform)操作从一个RDD生成另一个RDD,但行动(Action)操作会去掉RDD的壳。例如take是行动操作,返回的是一个数组而不是RDD了,在Scala中可以看到。
1 | scala> var rdd1 = sc.makeRDD(Seq(10, 4, 2, 12, 3)) |
转换操作是Lazy的,直到遇到一个Action操作,Spark才会生成关于整条链的执行计划并执行。这些Action操作将一个Spark Application分为了多个Job。
常见的Action操作包括:reduce、collect、count、take(n)、first、takeSample(withReplacement, num, [seed])、takeOrdered(n, [ordering])、saveAsTextFile(path)、saveAsSequenceFile(path)、saveAsObjectFile(path)、countByKey()、foreach(func)。
我们需要注意的是,有一些Transform操作也会得到一个Job,例如sortBy,这是因为这个Job是用来初始化RangePartitioner,然后Sample输入RDD的partition边界的,和sortBy的业务无关,在实践中所占用的时间也是远小于实际占用的时间的。
RDD的常见成员
-
def getPartitions: Array[Partition]:获得这个RDD的所有分区,由Partition的子类来描述 -
def compute(partition: Partition, context: TaskContext): Iterator[T] def getDependencies: Seq[Dependency[_]]:用来获取依赖关系
包含ShuffleDependency、OneToOneDependency、RangeDependency等。part: Partitioner
Partitioner是一个abstract class,具有numPartitions: Int和getPartition(key: Any): Int两个方法。通过继承Partitioner可以自定义分区的实现方式,目前官方提供的有RangePartitioner和HashPartitioner等。
HashPartitioner是默认分区器,对key的hashCode取模,得到其对应的RDD分区的值。注意这里的hashCode可能还是个坑,例如Java里面数组的hashCode并不蕴含数组内容的信息,所以可能相同的数组被分到不同的分区。如果我们有这样的需求,就需要自定义分区器。
RangePartitioner会从整个RDD中Sample出一些Key。Sample的Key的数量是基于生成的子RDD的partition数量来计算的,默认是每个partition取20个,再乘以分区数,最懂不超过1e6个。得到总共要sample多少个之后,我们要乘以3,再平摊到父RDD上。乘以三的意思是便于判断Data skew,如果父RDD的某个partition的数量大于了乘以3之后平摊的值,就可以认为这个partition偏斜了,需要丢这些partition进行重新抽样。-
def getPreferredLocations(partition: Partition): Seq[String]
常见RDD
RDD是一个抽象类abstract class RDD[T] extends Serializable with Logging,在Spark中有诸如ShuffledRDD、HadoopRDD等实现。每个RDD都有对应的compute方法,用来描述这个RDD的计算方法。需要注意的是,这些RDD可能被作为某些RDD计算的中间结果,例如CoGroupedRDD,对应的,例如MapPartitionsRDD也可能是经过多个RDD变换得到的,其决定权在于所使用的算子。
我们来具体查看一些RDD。
ParallelCollectionRDD
这个RDD由parallelize得到1
2scala> val arr = sc.parallelize(0 to 1000)
arr: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24HadoopRDD1
class HadoopRDD[K, V] extends RDD[(K, V)] with Logging
FileScanRDD
这个RDD一般从spark.read.text(...)语句中产生,所以实现在sql模块中。1
2
3
4
5class FileScanRDD(
@transient private val sparkSession: SparkSession,
readFunction: (PartitionedFile) => Iterator[InternalRow],
@transient val filePartitions: Seq[FilePartition])
extends RDD[InternalRow](sparkSession.sparkContext, Nil) {MapPartitionsRDD1
class MapPartitionsRDD[U, T] extends RDD[U]
这个RDD是
map、mapPartitions、mapPartitionsWithIndex操作的结果。
注意,在较早期的版本中,map会得到一个MappedRDD,filter会得到一个FilteredRDD、flatMap会得到一个FlatMappedRDD,不过目前已经找不到了,统一变成MapPartitionsRDD1
2
3
4
5
6scala> val a3 = arr.map(i => (i+1, i))
a3: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[2] at map at <console>:25
scala> val a3 = arr.filter(i => i > 3)
a3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at filter at <console>:25
scala> val a3 = arr.flatMap(i => Array(i))
a3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at flatMap at <console>:25join操作的结果也是MapPartitionsRDD,这是因为其执行过程的最后一步flatMapValues会创建一个MapPartitionsRDD1
2
3
4
5
6
7
8scala> val rdd1 = sc.parallelize(Array((1,1),(1,2),(1,3),(2,1),(2,2),(2,3)))
rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[8] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(Array((1,1),(1,2),(1,3),(2,1),(2,2),(2,3)))
rdd2: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[9] at parallelize at <console>:24
scala> val rddj = rdd1.join(rdd2)
rddj: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[12] at join at <console>:27ShuffledRDD
ShuffledRDD用来存储所有Shuffle操作的结果,其中K、V很好理解,C是Combiner Class。1
class ShuffledRDD[K, V, C] extends RDD[(K, C)]
以
groupByKey为例1
2
3
4
5scala> val a2 = arr.map(i => (i+1, i))
a2: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[2] at map at <console>:25
scala> a2.groupByKey
res1: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[3] at groupByKey at <console>:26注意,
groupByKey需要K是Hashable的,否则会报错。1
2
3
4
5
6
7scala> val a2 = arr.map(i => (Array.fill(10)(i), i))
a2: org.apache.spark.rdd.RDD[(Array[Int], Int)] = MapPartitionsRDD[2] at map at <console>:25
scala> a2.groupByKey
org.apache.spark.SparkException: HashPartitioner cannot partition array keys.
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$combineByKeyWithClassTag$1.apply(PairRDDFunctions.scala:84)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$combineByKeyWithClassTag$1.apply(PairRDDFunctions.scala:77)CoGroupedRDD1
class CoGroupedRDD[K] extends RDD[(K, Array[Iterable[_]])]
首先,我们需要了解一下什么是
cogroup操作,这个方法有多个重载版本。如下所示的版本,对this或other1或other2的所有的key,生成一个RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2])),表示对于这个key,这三个RDD中所有值的集合。容易看到,这个算子能够被用来实现Join和Union(不过后者有点大材小用了)1
2def cogroup[W1, W2](other1: RDD[(K, W1)], other2: RDD[(K, W2)], partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))]UnionRDD1
class UnionRDD[T] extends RDD[T]
UnionRDD一般通过union算子得到1
2scala> val a5 = arr.union(arr2)
a5: org.apache.spark.rdd.RDD[Int] = UnionRDD[7] at union at <console>:27CoalescedRDD
常见RDD外部函数
Spark在RDD之外提供了一些外部函数,它们可以通过隐式转换的方式变成RDD。
PairRDDFunctions
这个RDD被用来处理KV对,相比RDD,它提供了groupByKey、join等方法。以combineByKey为例,他有三个模板参数,从RDD过来的K和V以及自己的C。相比reduce和fold系列的(V, V) => V,这多出来的C使combineByKey更灵活,通过combineByKey能够将V变换为C。需要注意的是,这三个函数将来在ExternalSorter里面还将会被看到。1
2
3
4
5
6
7
8
9def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = {
//实现略
}OrderedRDDFunctions
这个用来提供sortByKey、filterByRange等方法。
Spark的架构概览
Spark在设计上的一个特点是它和下层的集群管理是分开的,一个Spark Application可以看做是由集群上的若干进程组成的。因此需要区分Spark中的概念和下层集群中的概念,例如常见的Master和Worker是集群中的概念,表示节点;而Driver和Executor是Spark中的概念,表示进程。根据爆栈网,Driver可能位于某个Worker节点中,或者位于Master节点上,这取决于部署的方式
在官网上给了这样一幅图,详细阐明了Spark集群下的基础架构。SparkContext是整个Application的管理核心,由Driver来负责管理。SparkContext负责管理所有的Executor,并且和下层的集群管理进行交互,以请求资源。
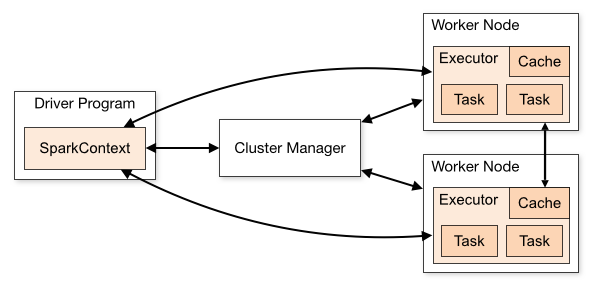
在Stage层次及以上接受DAGScheduler的调度,而TaskScheduler则调度一个Taskset。在Spark on Yarn模式下,CoarseGrainedExecutorBackend和Executor一一对应,它是一个独立于Worker主进程之外的一个进程,我们可以jps查看到。而Task是作为一个Executor启动的一个线程来跑的,一个Executor中可以跑多个Task。在实现上,CoarseGrainedExecutorBackend继承了ExecutorBackend这个trait,作为一个IsolatedRpcEndpoint,维护Executor对象实例,并通过创建的DriverEndpoint实例的与Driver进行交互。在进程启动时,CoarseGrainedExecutorBackend调用onStart()方法向Driver注册自己,并产生一条"Connecting to driver"的INFO。CoarseGrainedExecutorBackend通过DriverEndpoint.receive方法来处理来自Driver的命令,包括LaunchTask、KillTask等。这里注意一下,在scheduler中有一个CoarseGrainedSchedulerBackend,里面实现相似,在看代码时要注意区分开。
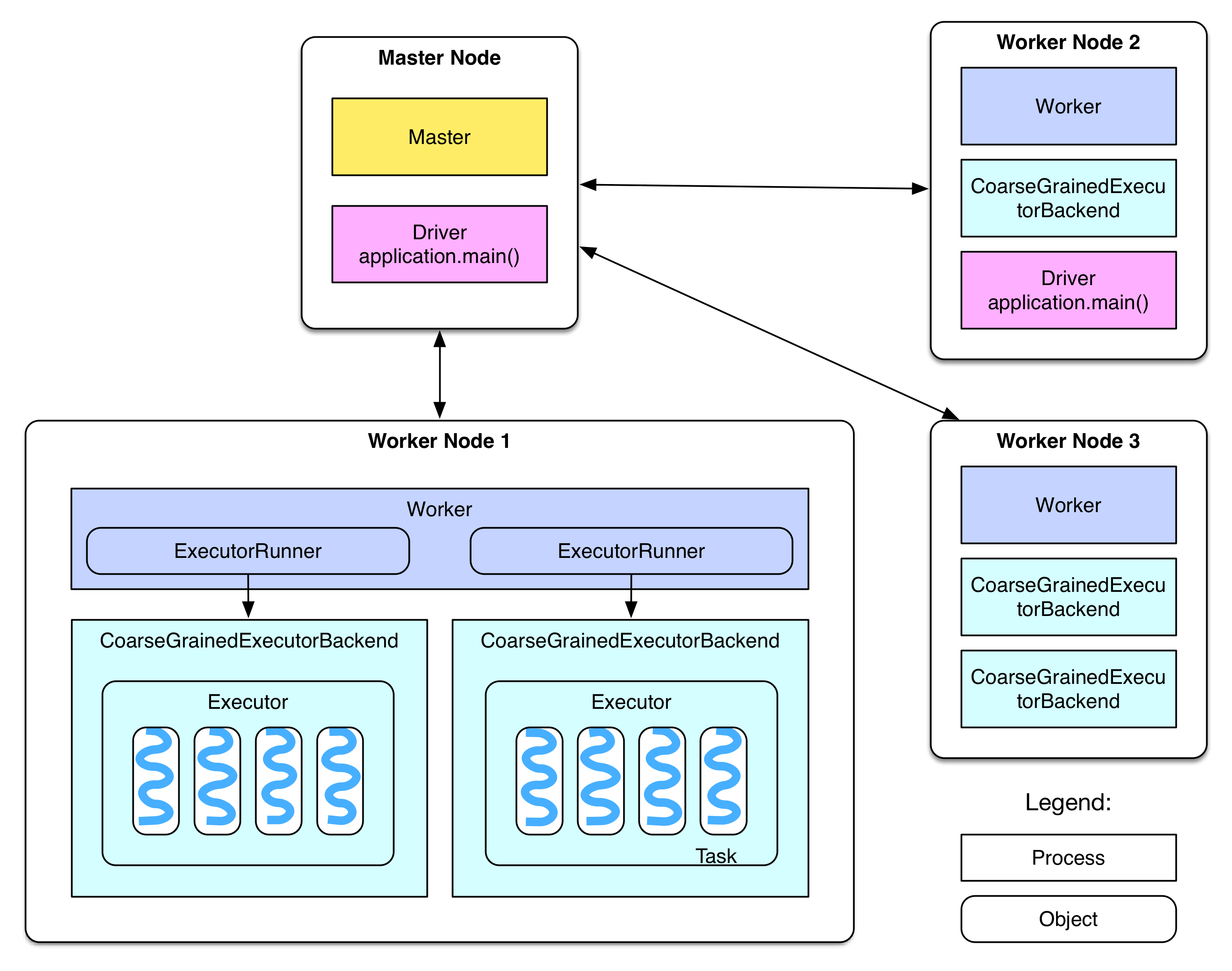
有关Executor和Driver的关系,下面这张图更加直观,需要说明的是,一个Worker上面也可能跑有多个Executor,每个Task也可以在多个CPU核心上面运行
Spark上下文
在代码里我们操作一个Spark任务有两种方式,通过SparkContext,或者通过SparkSession
SparkContext方式
SparkContext是Spark自创建来一直存在的类。我们通过SparkConf直接创建SparkContext1
2val sparkConf = new SparkConf().setAppName("AppName").setMaster("local")
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")SparkSession方式
SparkSession是在Spark2.0之后提供的API,相比SparkContext,他提供了对SparkSQL的支持(持有SQLContext),例如createDataFrame等方法就可以通过SparkSession来访问。
在builder.getOrCreate()的过程中,虽然最终得到的是一个SparkSession,但实际上内部已经创建了一个SparkContext,并由这个SparkSession持有。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23val spark: SparkSession = SparkSession.builder() // 得到一个Builder
.master("local").appName("AppName").config("spark.some.config.option", "some-value")
.getOrCreate() // 得到一个SparkSession
// SparkSession.scala
val sparkContext = userSuppliedContext.getOrElse {
val sparkConf = new SparkConf()
options.foreach { case (k, v) => sparkConf.set(k, v) }
// set a random app name if not given.
if (!sparkConf.contains("spark.app.name")) {
sparkConf.setAppName(java.util.UUID.randomUUID().toString)
}
SparkContext.getOrCreate(sparkConf)
// Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions.
}
applyExtensions(
sparkContext.getConf.get(StaticSQLConf.SPARK_SESSION_EXTENSIONS).getOrElse(Seq.empty),
extensions)
session = new SparkSession(sparkContext, None, None, extensions)
SparkEnv
SparkEnv持有一个Spark实例在运行时所需要的所有对象,包括Serializer、RpcEndpoint(在早期用的是Akka actor)、BlockManager、MemoryManager、BroadcastManager、SecurityManager、MapOutputTrackerMaster/Worker等等。SparkEnv由SparkContext创建,并在之后通过伴生对象SparkEnv的get方法来访问。在创建时,Driver端的SparkEnv是SparkContext创建的时候调用SparkEnv.createDriverEnv创建的。Executor端的是其守护进程CoarseGrainedExecutorBackend创建的时候调用SparkEnv.createExecutorEnv方法创建的。这两个方法最后都会调用create方法
1 | // Driver端 |
Spark的任务调度
Spark的操作可以分为两种,Transform操作是lazy的,而Action操作是Eager的。每一个Action会产生一个Job。
Spark的Transform操作可以分为宽依赖(ShuffleDependency)和窄依赖(NarrowDependency)操作两种,其中窄依赖还有两个子类OneToOneDependency和RangeDependency。窄依赖操作表示父RDD的每个分区只被子RDD的一个分区所使用,例如union、map、filter等的操作;而宽依赖恰恰相反。宽依赖需要shuffle操作,因为需要将父RDD的结果需要复制给不同节点用来生成子RDD,有关ShuffleDependency将在下面的Shuffle源码分析中详细说明。当DAG的执行中出现宽依赖操作时,Spark会将其前后划分为不同的Stage,在下一章节中将具体分析相关代码。这里需要注意的一点是coalesce这样的操作也是窄依赖,因为它涉及的输入分区是有限的。
在Stage之下,就是若干个Task了。这些Task也就是Spark的并行单元,通常来说,按照当前Stage的最后一个RDD的分区数来计算,每一个分区都会启动一个Task来进行计算。我们可以通过rdd.partitions.size来获取一个RDD有多少个分区。一般来说,初始的partition数是在HDFS中文件block的数量。
Task具有两种类型,ShuffleMapTask和ResultTask。其中ResultTask是ResultStage的Task,也就是最后一个Stage的Task。
下面提出几个有趣的问题:
- Job是可并行的么?
官网指出,within each Spark application, multiple “jobs” (Spark actions) may be running concurrently if they were submitted by different threads。所以如果你用多线程跑多个Action,确实是可以的。这也是容易理解的,因为跑一个Action相当于就是向Spark的DAGScheduler去提交一个任务嘛。 - Stage是可并行的么?
可以。Stage描述了宽依赖间的RDD的变化过程,而RDD的变化总体上是一个DAG。因此可以认识到,对于两个NarrowDependency的Stage,它们确实是可以并行的。
启动一个任务
Executor
1 | private[spark] class Executor( |
TaskRunner
1 | class TaskRunner( |
1 | private[spark] abstract class Task[T]( |
失败重试
spark.yarn.maxAppAttempts
YARN申请资源的重试次数。spark.yarn.max.executor.failures
Spark应用程序的最大Executor失败次数,默认numExecutors*2。
Spark的存储管理
为了实现与底层细节的解耦,Spark的存储基于BlockManager给计算部分提供服务。类似于Driver和Executor,BlockManager机制也分为BlockManagerMaster和BlockManager。Driver上的BlockManagerMaster对于存在与Executor上的BlockManager统一管理。BlockManager只是负责管理所在Executor上的Block。
BlockManagerMaster和BlockManager都是在SparkEnv中创建的,
1 | // Mapping from block manager id to the block manager's information. |
Driver节点和Executor节点的BlockManager之间的交互可以使用下图来描述,在此就不详细说明。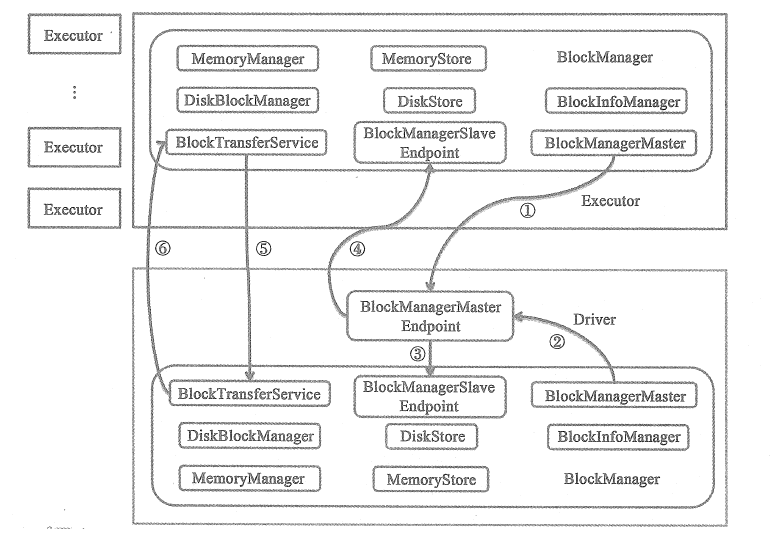
BlockId和BlockInfo
抽象类BlockId被用来唯一标识一个Block,具有全局唯一的名字,通常和一个文件相对应。BlockId有着确定的命名规则,并且和它实际的类型有关。
如果它是用来Shuffle的ShuffleBlockId,那么他的命名就是
1 | String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId |
抑或它是用来Broadcast的BroadcastBlockId,他的命名就是
1 | "broadcast_" + broadcastId + (if (field == "") "" else "_" + field) |
或者它是一个RDD,它的命名就是
1 | "rdd_" + rddId + "_" + splitIndex |
通过在Spark.log里面跟踪这些block名字,我们可以了解到当前Spark任务的执行和存储情况。
BlockInfo中的level项表示这个block的存储级别。
1 | // BlockInfoManager.scala |
持久化
Spark提供了如下的持久化级别,其中选项为useDisk、useMemory、useOffHeap、deserialized、replication,分别表示是否采用磁盘、内存、堆外内存、反序列化以及持久化维护的副本数。其中反序列化为false时(好绕啊),会对对象进行序列化存储,能够节省一定空间,但同时会消耗计算资源。需要注意的是,cache操作是persist的一个特例,等于MEMORY_ONLY的persist。所有的广播对象都是MEMORY_AND_DISK的存储级别
1 | object StorageLevel extends scala.AnyRef with scala.Serializable { |
想在Spark任务完成之后检查每一个RDD的缓存状况是比较困难的,虽然在Spark EventLog中,我们也能看到在每一个RDD的RDD Info中有一个StorageLevel的条目。RDDInfo的源码建议我们可以通过(Use Disk||Use Memory)&&NumberofCachedPartitions这样的条件来判断一个RDD到底有没有被cache。但实际上,似乎EventLog里面的NumberofCachedPartitions、Memory Size、Disk Size永远是0,这可能是只能在执行过程中才能看到这些字段的值,毕竟WebUI的Storage标签就只在执行时能看到。不过(Use Disk||Use Memory)在cache调用的RDD上是true的,所以可以以这个RDD为根做一个BFS,将所有不需要计算的RDD找出来。
Checkpoint
Save
相对于持久化,这里指的是保存数据到文件或者数据表。
RDD的overwrite问题
一个蛋疼的事情是RDD的诸如saveAsTextFile不能够像DF的API一样直接指定overwrite为true,导致无法复写的情况。为此,需要借助于hdfs的API手动来判断是否exist。
1 | val conf = new org.apache.hadoop.conf.Configuration() |
RDD的save问题
saveAsTextFile会写到多个文件里面,如下所示,如果我们save到这个文件夹,那么会在下面创建_SUCCESS、part-000000这样的文件
那么我们读的时候,比较方便的是用下面的方法
1 | spark.read.text(path).rdd.collect().mkString("") |
但这样会导致读出来的string周围有中括号包起来。因此要用下面的办法去掉
1 | text = if(textRaw.endsWith("]")){ |
不过,我们有另一种办法,就是绕过spark,而直接用hadoop的api来读取。
1 | val conf: Configuration |
BlockInfoManager
BlockInfoManager用来管理Block的元信息,例如它维护了所有BlockId的BlockInfo信息infos: mutable.HashMap[BlockId, BlockInfo]。不过它最主要的功能还是为读写Block提供锁服务
本地读Block
本地读方法位于BlockManager.scala中,从前叫getBlockData,现在叫getLocalBlockData,名字更易懂了。getLocalBlockData的主要内容就对Block的性质进行讨论,如果是Shuffle的,那么就借助于ShuffleBlockResolver。ShuffleBlockResolver是一个trait,它有两个子类IndexShuffleBlockResolver和ExternalShuffleBlockResolver,它们定义如何从一个logical shuffle block identifier(例如map、reduce或shuffle)中取回Block。这个类维护Block和文件的映射关系,维护index文件,向BlockStore提供抽象。
1 | // BlockManager.scala |
我们看getLocalBytes函数,它带锁地调用doGetLocalBytes
1 | def getLocalBytes(blockId: BlockId): Option[BlockData] = { |
上面的这一段代码会在spark.log中产生类似下面的Log,我们由此可以对Block的用途,存储级别等进行分析。
1 | 19/11/26 17:24:52 DEBUG BlockManager: Getting local block broadcast_3_piece0 as bytes |
doGetLocalBytes负责根据Block的存储级别,以最小的代价取到序列化后的数据。从下面的代码中可以看到,Spark认为序列化一个对象的开销是高于从磁盘中读取一个已经序列化之后的对象的开销的,因为它宁可从磁盘里面取也不愿意直接从内存序列化。
1 | private def doGetLocalBytes(blockId: BlockId, info: BlockInfo): BlockData = { |
Spark的内存管理
在Spark 1.6之后,内存管理模式发生了大变化,从前版本的内存管理需要通过指定spark.memory.useLegacyMode来手动启用,因此在这里只对之后的进行论述。
Spark内存布局
如下图所示,Spark的堆内存空间可以分为Spark托管区、用户区和保留区三块。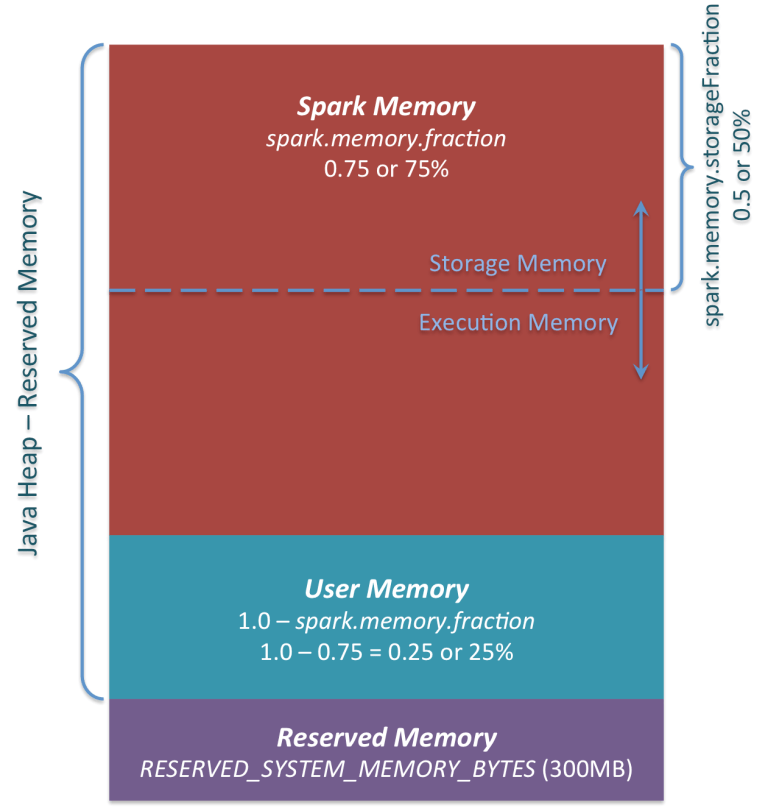
其中保留区占300MB,是固定的。托管区的大小由spark.memory.fraction节制,而1 - spark.memory.fraction的部分用户区。这个值越小,就越容易Spill或者Cache evict。这个设置的用途是将internal metadata、user data structures区分开来。从而减少对稀疏的或者不常出现的大对象的大小的不准确估计造成的影响(限定词有点多,是翻译的注释、、、)。默认spark.memory.fraction是0.6。
1 | // package.scala |
Spark的托管区又分为Execution和Storage两个部分。其中Storage主要用来缓存RDD、Broadcast之类的对象,Execution被用来存Mapside的Shuffle数据。Storage和Execution共享的内存,spark.storage.storageFraction(现在应该已经改成了spark.memory.storageFraction)表示对eviction免疫的Storage部分的大小,它的值越大,Execution内存就越小,Task就越容易Spill。反之,Cache就越容易被evict。默认spark.memory.storageFraction是0.5。
1 | // package.scala |
Storage可以借用任意多的Execution内存,直到Execution重新要回。此时被Cache的块会被从内存中evict掉(具体如何evict,根据每个Block的存储级别)。Execution也可以借用任意多的Storage的,但是Execution的借用不能被Storage驱逐,原因是因为实现起来很复杂。我们在稍后将看到,Spark没有一个统一的资源分配的入口。
除了堆内内存,Spark还可以使用堆外内存。为什么要有这个东西呢?原因是提高内存使用率、提高Shuffle时排序的效率等。由于Spark任务的性质,使用堆外内存能够更精细化地管理,而不需要通过JVM里面的GC,并且序列化数据的占用空间也可以被精确计算。此外,序列化也能节省内存开销。堆外内存在Spark 2.0之后由Tachyon迁移到了JDK Unsafe API实现。可通过配置spark.memory.offHeap.enabled参数启用堆外内存,并由spark.memory.offHeap.size参数设定堆外空间的大小。除了没有other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
MemoryManager
Spark中负责文件管理的类是MemoryManager,它是一个抽象类,被SparkEnv持有。在1.6版本后引入的UnifiedMemoryManager是它的一个实现。
1 | // SparkEnv.scala |
UnifiedMemoryManager实现了诸如acquireExecutionMemory等方法来分配内存。通过在acquireExecutionMemory时传入一个MemoryMode可以告知是从堆内请求还是从堆外请求。需要注意的是,这类的函数并不像malloc一样直接去请求一段内存,并返回内存的地址,而是全局去维护每个Task所使用的内存大小。每一个Task在申请内存(new对象)之前都会去检查一下自己有没有超标,否则就去Spill。也就是说MemoryManager实际上是一个外挂式的内存管理系统,它不实际上托管内存,整个内存还是由JVM管理的。
对Task的Execution内存使用进行跟踪的这个机制被实现ExecutionMemoryPool中,如下面的代码所示。
1 | // ExecutionMemoryPool.scala |
当然,有ExecutionMemoryPool就也有StorageMemoryPool,他们都不出所料继承了MemoryPool。而以上这些Pool最后都被MemoryManager所持有。
1 | // MemoryManager.scala |
请求内存的流程
我们知道,在Shuffle操作中有两个内存使用大户ExecutorSorter和ExternalAppendOnlyMap,都继承了Spillable,从而实现了在内存不足时进行Spill。我们查看对应的maybeSpill方法,它调用了自己父类MemoryConsumer中的acquireExecutionMemory方法。由于从代码注释上看似乎MemoryConsumer包括它引用到的TaskMemoryManager类都与Tungsten有关,所以我们将在稍后进行研究。目前只是列明调用过程,因为如果其中涉及要向Spark托管内存请求分配,最终调用的还是UnifiedMemoryManager中的对应方法。
1 | // Spillable.scala |
下面,我们来看acquireExecutionMemory的详细实现。它前面会首先根据memoryMode选择使用的MemoryPool,是堆内的,还是堆外的。然后它会有个函数maybeGrowExecutionPool,用来处理在需要的情况下从Storage部分挤占一些内存回来。我们可以在稍后详看这个方法。现在,我们发现acquireExecutionMemory会往对应的MemoryPool发一个调用acquireMemory。
1 | // UnifiedMemoryManager.scala |
由于我们讨论的场景就是请求堆内的执行内存,所以就进入ExecutionMemoryPool.scala查看相关代码。在Spark中,会尝试保证每个Task能够得到合理份额的内存,而不是让某些Task的内存持续增大到一定的数量,然后导致其他人持续地Spill到Disk。
如果有N个任务,那么保证每个Task在Spill前可以获得至少1 / 2N的内存,并且最多只能获得1 / N。因为N是持续变化的,所以我们需要跟踪活跃Task集合,并且持续在等待Task集合中更新1 / 2N和1 / N的值。这个是借助于同步机制实现的,在1.6之前,是由ShuffleMemoryManager来仲裁的。
1 | // ExecutionMemoryPool.scala |
Tungsten内存管理机制
Tungsten不依赖于Java对象,所以堆内和堆外的内存分配都可以支持。序列化时间相比原生的要加快很多。其优化主要包含三点:
- Memory Management and Binary Processing
- Cache-aware computation
- Code generation
这个是为了解决在Spark 2.0之前SparkSQL使用的Volcano中大量的链式next()导致的性能(虚函数等)问题。
在内存管理部分,能看到诸如TaskMemoryManager.java的文件;在稍后的Shuffle部分,能看到诸如UnsafeWriter.java的文件。这些Java文件在实现上就有对Tungsten的使用,因为用到了sun.misc.Unsafe的API,所以使用Tungsten的shuffle又叫Unsafe shuffle。
在MemoryManager中持有了Tungsten内存管理机制的核心类tungstenMemoryAllocator: MemoryAllocator。并设置了tungstenMemoryMode指示其分配内存的默认位置,如果MEMORY_OFFHEAP_ENABLED是打开的且MEMORY_OFFHEAP_SIZE是大于0的,那么默认使用堆外内存。
TaskMemoryManager
TaskMemoryManager这个对象被用来管理一个Task的堆内和对外内存分配,因此它能够调度一个Task中各个组件的内存使用情况。当组件需要使用TaskMemoryManager提供的内存时,他们需要继承一个MemoryConsumer类,以便向TaskMemoryManager请求内存。TaskMemoryManager中集成了普通的内存分配机制和Tungsten内存分配机制。
普通分配acquireExecutionMemory
我们跟踪TaskMemoryManager.acquireExecutionMemory相关代码,它先尝试从MemoryManager直接请求内存
1 | // TaskMemoryManager.scala |
如果请求不到,那么先尝试让同一个TaskMemoryManager上的其他的Consumer Spill,以减少Spill频率,从而减少Spill出来的小文件数量。主要是根据每个Consumer的内存使用排个序,从而避免重复对同一个Consumer进行Spill,导致产生很多小文件。
1 | ... |
现在,我们对排序得到的一系列sortedConsumers进行spill,一旦成功释放出内存,就立刻向MemoryManager去请求这些内存,相关代码没啥可看的,故省略。如果内存还是不够,就Spill自己,如果成功了,就向MemoryManager请求内存。
1 | ... |
Tungsten分配allocatePage
TaskMemoryManager还有个allocatePage方法,用来获得MemoryBlock,这个是通过Tungsten机制分配的。TaskMemoryManager使用了类似操作系统中分页的机制来操控内存。每个“页”,也就是MemoryBlock对象,维护了一段堆内或者堆外的内存。页的总数由PAGE_NUMBER_BITS来决定,即对于一个64位的地址,高PAGE_NUMBER_BITS(默认13)位表示一个页,而后面的位表示在页内的偏移。当然,如果是堆外内存,那么这个64位就直接是内存地址了。有关使用分页机制的原因在TaskMemoryManager.java有介绍,我暂时没看懂。
需要注意的是,即使使用Tungsten分配,仍然不能绕开UnifiedMemoryManager机制的管理,所以我们看到在allocatePage方法中先要通过acquireExecutionMemory方法注册,请求到逻辑内存之后,再通过下面的方法请求物理内存
1 | // TaskMemoryManager.scala |
Spark Job执行流程分析
Job阶段
下面我们通过一个RDD上的Action操作count,查看Spark的Job是如何运行和调度的。特别注意的是,在SparkSQL中,Action操作有不同的执行流程,所以宜对比着看。count通过全局的SparkContext.runJob启动一个Job,这个函数转而调用DAGScheduler.runJob。Utils.getIteratorSize实际上就是遍历一遍迭代器,以便统计count。
1 | // RDD.scala |
在参数列表里面的下划线_的作用是将方法转为函数,而方法和函数的定义和区别可参考我的另一篇文章。
下面查看runJob函数。比较有趣的是clean函数,它调用ClosureCleaner.clean方法,这个方法用来清理$outer域中未被引用的变量。因为我们要将闭包func序列化,并从Driver发送到Executor上面。序列化闭包的过程就是为每一个闭包生成一个可序列化类,在生成时,会将这个闭包所引用的外部对象也序列化。容易发现,如果我们为了使用外部对象的某些字段,而序列化整个对象,那么开销是很大的,因此通过clean来清除不需要的部分以减少序列化开销。此外,getCallSite用来生成诸如s"$lastSparkMethod at $firstUserFile:$firstUserLine"这样的字符串,它实际上会回溯调用栈,找到第一个不是在Spark包中的函数,即$lastSparkMethod,它是导致一个RDD创建的函数,比如各种Transform操作、sc.parallelize等。
1 | // SparkContext.scala |
我们发现,传入的func只接受一个Iterator[_]参数,但是其形参声明却是接受TaskContext和Iterator[T]两个参数。这是为什么呢?这是因为runJob有不少重载函数,例如下面的这个
1 | def runJob[T, U: ClassTag]( |
下面我们查看DAGScheduler.runJob函数,它实际上就是调用submitJob,然后等待Job执行的结果。由于Spark的DAGScheduler是基于事件循环的,它拥有一个DAGSchedulerEventProcessLoop类型的变量eventProcessLoop,不同的对象向它post事件,然后在它的onReceive循环中会依次对这些事件调用处理函数。
我们需要注意的是partitions不同于我们传入的rdd.partitions,前者是一个Array[Int],后者是一个Array[Partition]。并且在逻辑意义上,前者表示需要计算的partition,对于如first之类的Action操作来说,它只是rdd的所有partition的一个子集,我们将在稍后的submitMissingTasks函数中继续看到这一点。
1 | def runJob[T, U](...): Unit = { |
下面我们具体看看对JobSubmitted的响应
1 | // DAGScheduler.scala |
这里createResultStage所返回的ResultStage继承了Stage类。Stage类有个rdd参数,对ResultStage而言就是finalRDD,对ShuffleMapStage而言就是ShuffleDependency.rdd
1 | // DAGScheduler.scala |
下面我们来看看checkBarrierStageWithNumSlots这个函数,因为它会抛出BarrierJobSlotsNumberCheckFailed这个异常,被handleJobSubmitted捕获。这个函数主要是为了检测是否有足够的slots去运行所有的barrier task。屏障调度器是Spark为了支持深度学习在2.4.0版本所引入的一个特性。它要求在barrier stage中同时启动所有的Task,当任意的task执行失败的时候,总是重启整个barrier stage。这么麻烦是因为Spark希望能够在Task中提供一个barrier以供显式同步。
1 | // DAGScheduler.scala |
下面开始创建Job。ActiveJob表示在DAGScheduler里面运行的一个Job。
1 | // DAGScheduler.scala |
Job只负责向“叶子”Stage要结果,而之前Stage的运行是由DAGScheduler来调度的。这是因为若干Job可能共用同一个Stage的计算结果,所以将某个Stage强行归属到某个Job是不符合Spark设计逻辑的。我这么说的原因有一下两点
- 在下面的论述中可以看到,在
getMissingParentStages中会调用getOrCreateShuffleMapStage去取某个Stage。 - 根据爆栈网,
Stage中定义了一个jobIds,它是一个HashSet,也暗示了其可以被复用。1
2
3
4private[scheduler] abstract class Stage(...) extends Logging {
...
/** Set of jobs that this stage belongs to. */
val jobIds = new HashSet[Int]
Stage阶段
Stage是如何划分的呢?又是如何计算Stage之间的依赖的?我们继续查看submitStage这个函数,对于一个Stage,首先调用getMissingParentStages看看它的父Stage能不能直接用,也就是说这个Stage的rdd所依赖的所有父RDD能不能直接用,如果不行的话,就要先算父Stage的。在前面的论述里,我们知道,若干Job可能共用同一个Stage的计算结果,而不同的Stage也可能依赖同一个RDD。
1 | private def submitStage(stage: Stage) { |
下面具体查看getMissingParentStages这个函数,可以看到,Stage的计算链是以最后一个RDD为树根逆着向上遍历得到的,而这个链条的终点要么是一个ShuffleDependency,要么是一个所有分区都被缓存了的RDD。
1 | private def getMissingParentStages(stage: Stage): List[Stage] = { |
Task阶段
下面是重头戏submitMissingTasks,这个方法负责生成TaskSet,并且将它提交给TaskScheduler低层调度器。partitionsToCompute计算有哪些分区是待计算的。根据Stage类型的不同,findMissingPartitions的计算方法也不同。
1 | // DAGScheduler.scala |
这个outputCommitCoordinator是由SparkEnv维护的OutputCommitCoordinator对象,它决定到底谁有权利向HDFS写数据。在Executor上的请求会通过他持有的Driver的OutputCommitCoordinatorEndpoint的引用发送给Driver处理
1 | // DAGScheduler.scala |
用getPreferredLocs计算每个分区的最佳计算位置,它实际上是调用getPreferredLocsInternal这个函数。这个函数是一个关于visit: HashSet[(RDD[_], Int)]的递归函数,visit用(rdd, partition)元组唯一描述一个分区。getPreferredLocs的计算逻辑是这样的:
- 如果已经visit过了,就返回Nil
- 如果是被cached的,通过
getCacheLocs返回cache的位置 - 如果RDD有自己的偏好位置,例如输入RDD,那么使用
rdd.preferredLocations返回它的偏好位置 - 如果还没返回,但RDD有窄依赖,那么遍历它的所有依赖项,返回第一个具有位置偏好的依赖项的值
理论上,一个最优的位置选取应该尽可能靠近数据源以减少网络传输,但目前版本的Spark还没有实现
1 | // DAGScheduler.scala |
下面,我们开始attempt这个Stage,我们需要将RDD对象和依赖通过closureSerializer序列化成taskBinaryBytes,然后广播得到taskBinary。当广播变量过大时,会产生一条Broadcasting large task binary with size的INFO。
1 | // DAGScheduler.scala |
下面,我们根据Stage的类型生成Task。
1 | // DAGScheduler.scala |
我们将生成的tasks包装成一个TaskSet,并且提交给taskScheduler。
1 | // DAGScheduler.scala |
如果tasks是空的,说明任务就已经完成了,打上DEBUG日志,并且调用submitWaitingChildStages
1 | // Because we posted SparkListenerStageSubmitted earlier, we should mark |
Shuffle
Shuffle机制是Spark Core的核心内容。在Stage和Stage之间,Spark需要Shuffle数据。这个流程包含上一个Stage上的Shuffle Write,中间的数据传输,以及下一个Stage的Shuffle Read。如下图所示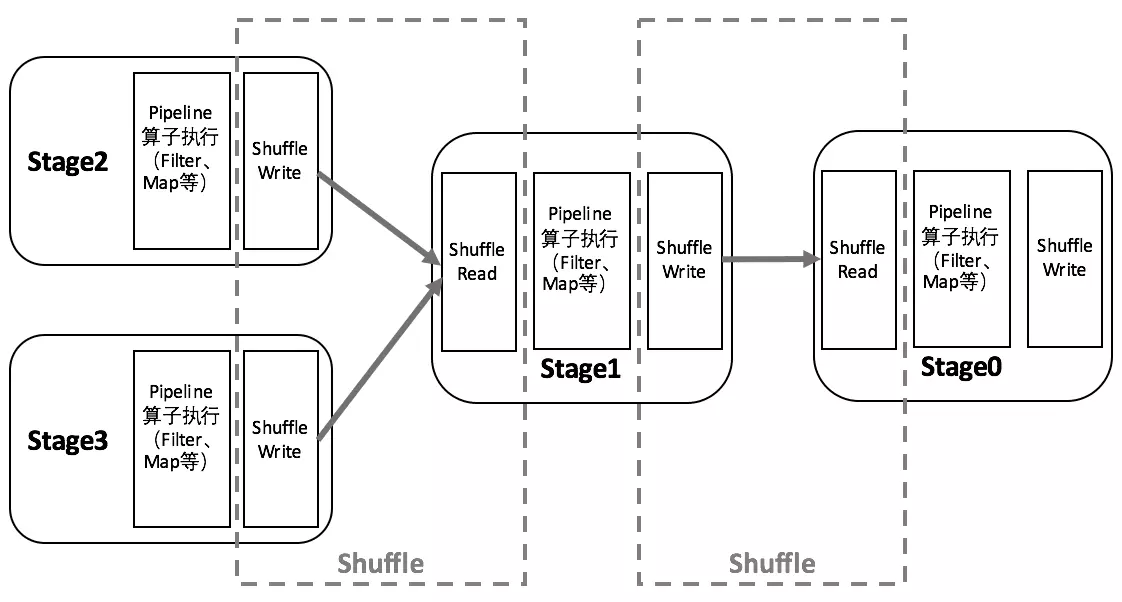
Shuffle类操作常常发生在宽依赖的RDD之间,这类算子需要将多个节点上的数据拉取到同一节点上进行计算,其中存在大量磁盘IO、序列化和网络传输开销,它们可以分为以下几点来讨论。
当Spark中的某个节点故障之后,常常需要重算RDD中的某几个分区。对于窄依赖而言,父RDD的一个分区只对应一个子RDD分区,因此丢失子RDD的分区,重算整个父RDD分区是必要的。而对于宽依赖而言,父RDD会被多个子RDD使用,而可能当前丢失的子RDD只使用了父RDD中的某几个分区的数据,而我们仍然要重新计算整个父RDD,这造成了计算资源的浪费。
当使用Aggregate类(如groupByKey)或者Join类这种Shuffle算子时,如果选择的key上的数据是倾斜(skew)的,会导致部分节点上的负载增大。对于这种情况除了可以增加Executor的内存,还可以重新选择分区函数(例如在之前的key上加盐)来平衡分区。
Shuffle Read操作容易产生OOM,其原因是尽管在BlockStoreShuffleReader中会产生外部排序的resultIter,但在这之前,ExternalAppendOnlyMap先要从BlockManager拉取数据(k, v)到自己的currentMap中,如果这里的v很大,那么就会导致Executor的OOM问题。可以从PairRDDFunctions的文档中佐证这一点。在Dataset中并没有reduceByKey,原因可能与Catalyst Optimizer的优化有关,但考虑到groupByKey还是比较坑的,感觉这个举措并不明智。
Map side combine
Map side combine指的是将聚合操作下推到每个计算节点,在这些节点上预先聚合(Aggregate),将预聚合的结果拉到Driver上进行最终的聚合。这有点类似于Hadoop的Combine操作,目的是为了减少通信,以及为了通信产生的序列化反序列化开销。
Map side combine可以体现在一些新的算子的替换,例如groupByKey -> reduceByKey。
Shuffle考古
在Spark0.8版本前,Spark只有Hash Based Shuffle的机制。在这种方式下,假定Shuffle Write阶段(有的也叫Map阶段)有W个Task,在Shuffle Read阶段(有的也叫Reduce阶段)有R个Task,那么就会产生W*R个文件,分别表示从W中某个Task传递到R中的某个Task。这样的坏处是对文件系统产生很大压力,并且IO也差(随机读写)。由于这些文件是先全量在内存里面构造,再dump到磁盘上,所以Shuffle在Write阶段就很可能OOM。
为了解决这个问题,在Spark 0.8.1版本加入了File Consolidation,以求将W个Task的输出尽可能合并。现在,Executor上的每一个执行单位都生成自己独一份的文件。假定所有的Executor总共有C个核心,每个Task占用T个核心,那么总共有C/T个执行单位。考虑极端情况,如果C==T,那么任务实际上是串行的,所以写一个文件就行了。因此,最终会生成C/T*R个文件。
但这个版本仍然没有解决OOM的问题。虽然对于reduce这类操作,比如count,因为是来一个combine一个,所以只要你的V不是数组,一般都没有较大的内存问题。但有的时候我们可能会强行把结果concat成一个数组。考虑执行groupByKey这样的操作,在Read阶段,每个Task需要得到得到自己负责的key对应的所有value,而Shuffle Write产生的是若干很大的文件,里面的key是杂乱无章的。如果我们需要得到一个key对应的所有value,那么我们就需要遍历这个文件,将key和对应的value全部存放在一个结构比如HashMap中,并进行合并。因此,我们必须保证这个HashMap足够大。既然如此,我们很容易想到一个基于外部排序的方案,我们为什么不能对key进行外排呢?确实在Hadoop MapReduce中会做归并排序,因此Reducer侧的数据按照key组织好的了。但Spark在下一个版本才这么做。
在Spark 0.9版本之后,引入了ExternalAppendOnlyMap,通过这个结构,SparkShuffle在combine的时候如果内存不够,就能Spill到磁盘,并在Spill的时候进行排序。当然,内存还是要能承载一个KV的,我们将在稍后的源码分析中深入研究这个问题。
终于在Spark1.1版本之后引入了Sorted Based Shuffle。此时,Shuffle Write阶段会按照Partition ID以及key对记录进行排序。同时将全部结果写到一个数据文件中,同时生成一个索引文件,Shuffle Read的Task可以通过该索引文件获取相关的数据。
在Spark 1.5,Tungsten内存管理机制成为了Spark的默认选项。如果关闭spark.sql.tungsten.enabled,Spark将采用基于Kryo序列化的列式存储格式。
常见对象关系简介
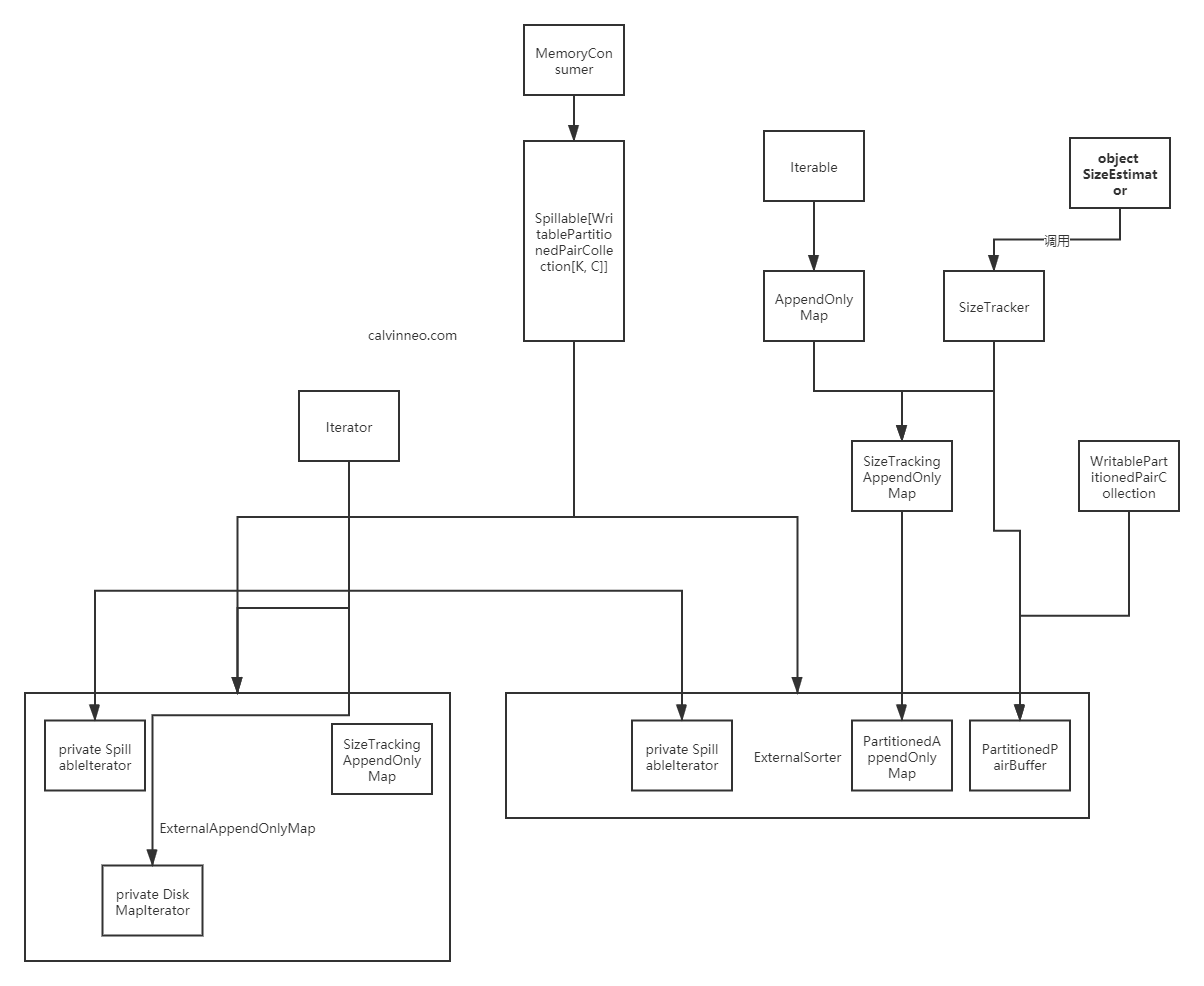
ShuffleManager/SortShuffleManager
ShuffleManager是一个Trait,它的两个实现就是org.apache.spark.shuffle.hash.HashShuffleManager和org.apache.spark.shuffle.sort.SortShuffleManager。
如果partition的数量小于spark.shuffle.sort.bypassMergeThreshold,并且我们不需要做map side combine,那么就使用BypassMergeSortShuffleHandle。输出numPartitions个文件,并且在最后merge起来。这么做可以避免普通流程中对Spill的文件进行序列化和反序列化的过程。不好的是需要同时打开多个文件,并且导致很多内存分配。
如果可以进行序列化,就使用SerializedShuffleHandle。
否则就使用BaseShuffleHandle。
1 | private[spark] class SortShuffleManager(conf: SparkConf) extends ShuffleManager with Logging { |
shouldBypassMergeSort主要判断下面几点:
- 是否有Map Side Combine
- Partition的数量是否小于bypassMergeThreshold
1 | private[spark] object SortShuffleWriter { |
canUseSerializedShuffle主要判断下面几点:
- 是否支持序列化文件
- 是否允许Map-side Combine
1 | private[spark] object SortShuffleManager extends Logging { |
Shuffle完,产生多少个分区呢?这取决于具体的Partitioner,默认是200个。如果指定了Partitioner,通常是有产生Shuffle的时候计算的。例如coalesce会产生一个包装ShuffledRDD的CoalescedRDD。
1 | val SHUFFLE_PARTITIONS = buildConf("spark.sql.shuffle.partitions") |
Shuffle Read端源码分析
Shuffle Read一般位于一个Stage的开始,这时候上一个Stage会给我们留下一个ShuffledRDD。在它的compute方法中会首先取出shuffleManager: ShuffleManager。
1 | override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { |
接着,我们调用shuffleManager.getReader方法返回一个BlockStoreShuffleReader,它用来读取[split.index, split.index + 1)这个区间内的Shuffle数据。接着,它会调用SparkEnv.get.mapOutputTracker的getMapSizesByExecutorId方法。getMapSizesByExecutorId返回一个迭代器Iterator[(BlockManagerId, Seq[(BlockId, Long, Int)])],表示对于某个BlockManagerId,它所存储的Shuffle Write中间结果,包括BlockId、大小和index。
具体实现上,这个方法首先从传入的dep.shuffleHandle中获得当前Shuffle过程的唯一标识shuffleId,然后它会从自己维护的shuffleStatuses中找到shuffleId对应的MapStatus,它应该有endPartition-startPartition这么多个。接着,对这些MapStatus,调用convertMapStatuses获得迭代器。在compute中,实际上就只取当前split这一个Partition的Shuffle元数据。
1 | ... |
ShuffleManager通过调用BlockStoreShuffleReader.read返回一个迭代器Iterator[(K, C)]。在BlockStoreShuffleReader.read方法中,首先得到一个ShuffleBlockFetcherIterator
1 | // BlockStoreShuffleReader.scala |
ShuffleBlockFetcherIterator用fetchUpToMaxBytes()和 fetchLocalBlocks()分别读取remote和local的Block。在拉取远程数据的时候,会统计bytesInFlight、reqsInFlight等信息,并使用maxBytesInFlight和maxReqsInFlight节制。同时,为了允许5个并发同时拉取数据,还会设置targetRemoteRequestSize = math.max(maxBytesInFlight / 5, 1L)去请求每次拉取数据的最大大小。通过ShuffleBlockFetcherIterator.splitLocalRemoteBytes,现在改名叫partitionBlocksByFetchMode函数,可以将blocks分为Local和Remote的。关于两个函数的具体实现,将单独讨论。
1 | val serializerInstance = dep.serializer.newInstance() |
经过一系列转换,我们得到一个interruptibleIter。接下来,根据是否有Map Side Combine对它进行聚合。这里的dep来自于BaseShuffleHandle对象,它是一个ShuffleDependency。在前面Spark的任务调度中已经提到,ShuffleDependency就是宽依赖。
1 | // BlockStoreShuffleReader.scala |
这里的aggregator是Aggregator[K, V, C],这里的K、V和C与熟悉combineByKey的是一样的。需要注意的是,在combine的过程中借助了ExternalAppendOnlyMap,这是之前提到的在Spark 0.9中引入的重要特性。通过调用insertAll方法能够将interruptibleIter内部的数据添加到ExternalAppendOnlyMap中,并在之后更新MemoryBytesSpilled、DiskBytesSpilled、PeakExecutionMemory三个统计维度,这也是我们在Event Log中所看到的统计维度。
1 | // Aggregator.scala |
在获得Aggregate迭代器之后,最后一步,我们要进行排序,这时候就需要用到ExternalSorter这个对象。
1 | // BlockStoreShuffleReader.scala |
Spillable
从常见对象关系简介图中可以发现,其实Spillable是一个核心类,它定义了内存不够时的溢出行为。查看定义,发现它继承了MemoryConsumer。
1 | private[spark] abstract class Spillable[C](taskMemoryManager: TaskMemoryManager) |
另一点有趣的是这个C没有任何诸如上下界的约束,我以为Spark这边会至少给能Spill的容器一点约束啥的。
在这里,我们先来分析一下它的几个主要方法。
maybeSpill是Spillable的主要逻辑,负责调用其他的抽象方法。
我们将在单独的章节论述SizeTracker如何估计集合大小,先看具体的Spill过程,可以梳理出shouldSpill==true的情况:
elementsRead % 32 == 0currentMemory >= myMemoryThreshold,其中后者默认值为spark.shuffle.spill.initialMemoryThreshold = 5 * 1024 * 1024,随着内存的分配会不断增大。前者为当前估计的Collection的内存大小。- 通过
acquireMemory请求的内存不足以扩展到2 * currentMemory的大小,关于这一步骤已经在内存管理部分详细说明了,在这就不详细说了
1 | // Spillable.scala |
下面就是真正Spill的过程了,其实就是调用可能被重载的spill函数。注意_memoryBytesSpilled就是我们在Event Log里面看到的Memory Spill的统计量,他表示在Spill之后我们能够释放多少内存
1 | // Spillable.scala |
protected def spill(collection: C): Unit 是由子类自己实现的逻辑。
override def spill(size: Long, trigger: MemoryConsumer): Long 是来自MemoryConsumer的接口,会调用forceSpill。
protected def forceSpill(): Boolean
这个完全由子类来实现。
一个容易想到的问题是,spill和forceSpill有啥区别呢?前者嘛,肯定是被maybeSpill调用的,而后者,根据注释,是会被TaskMemoryManager调用的。当这个任务没有足够多的内存的时候,会调用override def spill(size: Long, trigger: MemoryConsumer): Long这个方法,而这个方法会调用forceSpill。
logSpillage函数。其实按道理,只要用到继承了Spillalbe的类,那么就会在Spark.log里面看到相应的log字符串,但我观察了一下,并没有看到在Shuffle密集任务里面看到有过多的Spill。只有观察到UnsafeExternalSorter里面有Thread 102 spilling sort data of 1664.0 MB to disk(0 time so far)。
1 | private def logSpillage(size: Long) { |
当然,Spillable也不是一上来就Spill的,也会有个先申请内存的过程。这体现了在maybeSpill中,会先尝试调用自己MemoryConsumer基类的acquireMemory方法尝试获得足够数量的内存。
1 | // Initial threshold for the size of a collection before we start tracking its memory usage |
SizeTracker
上面讲解了Spillable的特点,在这一章节中,继续介绍Spillable过程中用到的SizeTracker的实现。我们知道非序列化对象在内存存储上是不连续的,我们需要通过遍历迭代器才能知道对象的具体大小,而这个开销是比较大的。因此通过SizeTracker我们可以得到一个内存空间占用的估计值,从来用来判定是否需要Spill。
首先在每次集合更新之后,会调用afterUpdate,当到达采样的阈值nextSampleNum之后,会takeSample。
1 | // SizeTracker.scala |
需要注意,这里不是每一次都要takeSample一次,原因是这个计算开销还是蛮大的(主要是下面要讲的estimate方法)。我们查看定义
1 | /** |
在开头,提到一个exponential back-off。这里的exponential back-off实际上就是每次更新后,随着numUpdates的增大,会更新nextSampleNum,导致调用的次数也会越来越不频繁。而这个nextSampleNum的值是numUpdates*SAMPLE_GROWTH_RATE,默认值是1.1。takeSample函数中第一句话就涉及多个对象,一个一个来看。
1 | // SizeTracker.scala |
SizeEstimator.estimate的实现类似去做一个state队列上的BFS。
1 | private def estimate(obj: AnyRef, visited: IdentityHashMap[AnyRef, AnyRef]): Long = { |
visitSingleObject来具体做这个BFS,会特殊处理Array类型。我们不处理反射,因为反射包里面会引用到很多全局反射对象,这个对象又会应用到很多全局的大对象。同理,我们不处理ClassLoader,因为它里面会应用到整个REPL。反正ClassLoaders和Classes是所有对象共享的
1 | private def visitSingleObject(obj: AnyRef, state: SearchState): Unit = { |
然后我们创建一个Sample,并且放到队列samples中
1 | private object SizeTracker { |
下面的主要工作就是计算一个bytesPerUpdate
1 | ... |
我们统计到上次估算之后经历的update数量,并乘以bytesPerUpdate,即可得到总大小
1 | // SizeTracker.scala |
AppendOnlyMap
赋值
下面的代码是AppendOnlyMap.changeValue的实现,它接受一个updateFunc用来更新一个指定K的值。updateFunc接受第一个布尔值,用来表示是不是首次出现这个key。我们需要注意,AppendOnlyMap里面null是一个合法的键,但同时null又作为它里面的哈希表的默认填充,因此它里面有个对null特殊处理的过程。也就是说,如果key是null,会提前将它替换为一个nullValue的值,这个key不会存放到哈希表data里面。这里介绍一下null.asInstanceOf[V]的花里胡哨的语法,
1 | // AppendOnlyMap.scala |
下面,我们看看incrementSize的实现,这是一个很经典的以2为底的递增的内存分配。当目前元素数量达到(LOAD_FACTOR * capacity)后,就考虑扩容。
1 | /** Increase table size by 1, rehashing if necessary */ |
迭代器
先来看看destructiveSortedIterator的实现,相比它提供的另一个iterator方法,这个方法同样返回一个Iterator,但是经过排序的。这里destructive的意思是inplace的,会改变原来的容器的状态,因此它不需要使用额外的内存。
1 | // AppendOnlyMap.scala |
ExternalAppendOnlyMap
我们查看ExternalAppendOnlyMap的实现。ExternalAppendOnlyMap拥有一个currentMap管理在内存中存储的键值对们。和一个DiskMapIterator的数组spilledMaps,表示Spill到磁盘上的键值对们。
1 | private[collection] var currentMap = new SizeTrackingAppendOnlyMap[K, C] |
插入
下面,我们来看insertAll这个方法,这个方法也就是将一些KV对,加入ExternalAppendOnlyMap中。
这里的currentMap是一个SizeTrackingAppendOnlyMap。这个东西实际上就是一个AppendOnlyMap,不过给它加上了统计数据大小的功能,主要是借助于SizeTracker中afterUpdate和resetSamples两个方法。
1 | // ExternalAppendOnlyMap.scala |
可以看出,在insertAll中主要做了两件事情:
- 遍历
curEntry <- entries,并通过传入的update函数进行Combine
在内部存储上,AppendOnlyMap,包括后面将看到的一些其他KV容器,都倾向于将(K, V)对放到哈希表的相邻两个位置,这样的好处应该是避免访问时再进行一次跳转。有关changeValue的实现,我们已经在AppendOnlyMap上进行了讨论。 - 估计
currentMap的当前大小,并调用currentMap.maybeSpill向磁盘Spill。Spill相关的过程,我们已经在Spillable相关章节进行了说明
读出
下面查看ExternalAppendOnlyMap.iterator这个方法,可以发现如果spilledMaps都是空的,也就是没有Spill的话,就返回内存里面currentMap的iterator,否则就返回一个ExternalIterator。
对于第一种情况,会用SpillableIterator包裹一下。这个类在很多地方有定义,包括ExternalAppendOnlyMap.scala,ExternalSorter.scala里面。在当前使用的实现中,它实际上就是封装了一下Iterator,使得能够spill,转换成CompletionIterator等。我们稍后来看一下这个迭代器的实现。
对于第二种情况,ExternalIterator比较有趣,将在稍后进行讨论。
1 | // ExternalAppendOnlyMap.scala |
而currentMap.iterator实际上就是一个朴素无华的迭代器的实现。
1 | // AppendOnlyMap.scala |
Spill细节和SpillableIterator的实现
而Spill实际上是走的spillMemoryIteratorToDisk函数
ExternalIterator
下面我们来看ExternalAppendOnlyMap中ExternalIterator的实现。它是一个典型的外部排序的实现,有一个PQ用来merge。不过这次的迭代器换成了destructiveSortedIterator,sorted的意思就是我们都是排序的了。这个道理也是显而易见的,不sort一下,我们怎么和硬盘上的数据做聚合呢?
1 | // ExternalAppendOnlyMap.scala |
destructiveSortedIterator的实现已经在AppendOnlyMap中进行了介绍。
下面我们来看看实现的ExternalAppendOnlyMap.next()接口函数,它是外部排序中的一个典型的归并过程。我们需要注意的是minBuffer是一个StreamBuffer,维护一个hash(K), V的ArrayBuffer,类似H1 V1 H1 V2 H2 V3这样的序列,而不是我们想的(K, V)流。因此其中是可能有哈希碰撞的。我们从mergeHeap中dequeue出来的StreamBuffer是当前hash(K)最小的所有K的集合。
1 | // ExternalAppendOnlyMap.scala |
ExternalSorter
ExternalSorter的作用是对输入的(K, V)进行排序,以产生新的(K, C)对,排序过程中可选择进行combine,否则输出的C == V。需要注意的是ExternalSorter不仅被用在Shuffle Read端,也被用在了Shuffle Write端,所以在后面会提到Map-side combine的概念。ExternalSorter具有如下的参数,在给定ordering之后,ExternalSorter就会按照它来排序。在Spark源码中建议如果希望进行Map-side combining的话,就指定ordering,否则就可以设置ordering为null
1 | private[spark] class ExternalSorter[K, V, C]( |
由于ExternalSorter支持有combine和没有combine的两种模式,因此对应设置了两个对象。map = new PartitionedAppendOnlyMap[K, C],以及buffer = new PartitionedPairBuffer[K, C]。其中,PartitionedAppendOnlyMap就是一个SizeTrackingAppendOnlyMap,支持按key进行combine。PartitionedPairBuffer则继承了WritablePartitionedPairCollection,由于不需要按照key进行combine,所以它的实现接近于一个Array。
相比之前的aggregator,ExternalSorter不仅能aggregate,还能sort。ExternalSorter在Shuffle Read和Write都有使用,而ExternalAppendOnlyMap只有在Shuffle Read中使用。所以为啥不直接搞一个ExternalSorter而是还要在前面垫一个ExternalAppendOnlyMap呢?为此,我们总结比较一下这两者:
首先,在insertAll时,ExternalAppendOnlyMap是一定要做combine的,而ExternalSorter可以选择是否做combine,为此还有PartitionedAppendOnlyMap和PartitionedPairBuffer两种数据结构。
其次,在做排序时,ExternalAppendOnlyMap默认对内存中的对象不进行排序,只有当要Spill的时候才会返回AppendOnlyMap.destructiveSortedIterator的方式将内存里面的东西有序写入磁盘。在返回迭代器时,如果没有发生Spill,那么ExternalAppendOnlyMap返回没有经过排序的currentMap,否则才通过ExternalIterator进行排序。而对ExternalSorter而言排序与否在于有没有指定ordering。如果进行排序的话,那么它会首先考虑Partition,再考虑Key。
插入
ExternalSorter.insertAll方法和之前看到的ExternalAppendOnlyMap方法是大差不差的,他也会对可以聚合的特征进行聚合,并且TODO上还说如果聚合之后的reduction factor不够明显,就停止聚合。根据是否定义了aggregator,会分别采用之前提到的map和buffer来承载加入的数据。
1 | // ExternalSorter.scala |
容易看出,这里面用到maybeSpillCollection来尝试管理内存,这个应该是和spill相关的,我们检查一下其实现,发现其实就是一个代理,对于是否使用map的情况,进行了分类讨论。而maybeSpill就是Spillable里面的定义了。
1 | private def maybeSpillCollection(usingMap: Boolean): Unit = { |
Shuffle Write端源码分析
Shuffle Write端的实现主要依赖ShuffleManager中的ShuffleWriter对象,目前使用的ShuffleManager是SortShuffleManager,因此只讨论它。它是一个抽象类,主要有SortShuffleWriter、UnsafeShuffleWriter、BypassMergeSortShuffleWriter等实现。
SortShuffleWriter
1 | private[spark] abstract class ShuffleWriter[K, V] { |
SortShuffleWriter的实现可以说很简单了,就是将records放到一个ExternalSorter里面,然后创建一个ShuffleMapOutputWriter。shuffleExecutorComponents实际上是一个LocalDiskShuffleExecutorComponents。ShuffleMapOutputWriter是一个Java接口,实际上被创建的是LocalDiskShuffleMapOutputWriter
1 | // SortShuffleWriter |
紧接着,调用ExternalSorter.writePartitionedMapOutput将自己维护的map或者buffer(根据是否有Map Side Aggregation)写到mapOutputWriter提供的partitionWriter里面。其过程用到了一个叫destructiveSortedWritablePartitionedIterator的迭代器,相比destructiveSortedIterator,它是多了Writable和Partitioned两个词。前者的意思是我可以写到文件,后者的意思是我先按照partitionId排序,然后在按照给定的Comparator排序。
接着就是commitAllPartitions,这个函数调用writeIndexFileAndCommit。
1 | // |
MapStatus被用来保存Shuffle Write操作的metadata。
1 | ... |
writeIndexFileAndCommit负责为传入的文件dataTmp创建一个索引文件,并原子地提交。注意到,到当前版本,每一个执行单元只会生成一份数据文件和一份索引。
1 | // IndexShuffleBlockResolver.java |
根据writeIndexFileAndCommit的注释,getBlockData会来读它写的块,这个getBlockData同样位于我们先前介绍过的IndexShuffleBlockResolver类中。
BypassMergeSortShuffleWriter
下面我们来看看BypassMergeSortShuffleWriter的实现。它到底Bypass了什么东西呢?其实是sort和aggregate。
UnsafeShuffleWriter
SortShuffleManager还有一个子类是UnsafeShuffleWriter。UnsafeShuffleWriter使用ShuffleExternalSorter进行排序,而SortShuffleWriter使用ExternalSorter对象。UnsafeShuffleWriter使用TaskMemoryManager作内存分配,而SortShuffleWriter没有明确指定。
fetchLocalBlocks和fetchUpToMaxBytes的实现
简单说明一下fetchLocalBlocks和fetchUpToMaxBytes的实现
1 | // ShuffleBlockFetcherIterator.scala |
Spark分布式部署方式
Spark自有部署方式
最常用的其实是单机模式也就是spark-submit --master local,这里local是默认选项。在程序执行过程中,只会生成一个SparkSubmit进程,不会产生Master和Worker节点,也不依赖Hadoop。当然,Windows里面可能需要winutils这个工具的,但也是直接下载,而不需要装Hadoop。
在集群化上,Spark可以部署在On Yarn和On Mesos、K8S和Standalone上面,而又分别对应了Cluster和Client两种deploy mode。
首先是Spark自带Cluster Manager的Standalone Client模式,也是我们最常用的集群测试模式,需要启动Master和Slave节点,但仍然不依赖Hadoop。
1 | ./bin/spark-submit --master spark://localhost:7077 --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.11-2.4.4.jar 100 |
下面一种是Spark自带Cluster Manager的Standalone Cluster模式,一字之差,还是有不同的,用下面的方式启动
1 | ./bin/spark-submit --master spark://wl1:6066 --deploy-mode cluster # 默认cluster |
上面两种的配置一般修改Spark的spark-defaults.conf和spark-env.sh也就可以了,不涉及hadoop。
此外,还有Connection Reset的情况,这个需要打开Connection Reset。
Yarn
Spark跑在yarn上面,这个还依赖hadoop集群,但Spark不需要自己提供Master和Worker了。Yarn同样提供了Cluster和Client两种模式,如下所示
1 | ./bin/spark-submit --master yarn-cluster |
Yarn Cluster就是通常使用的部署方式,此时Spark Driver是运行在Yarn的ApplicationMaster上的,而Client方式的Driver是在任务提交机上面运行,ApplicationMaster只负责向ResourceManager申请Executor需要的资源。
我们在Spark的WebUI中常常看到诸如Container、ApplicationMaster、ResourceMaster、NodeManager这些东西,其实他们都是Yarn里面的常见概念。具体的联系可以结合下面的图来看,ResourceMaster是YARN集群的Master,负责管理整个集群的资源,而NodeManager就是YARN集群的Slave,每个Node上面都会跑一个NodeManager。而每个Node上面又可以有很多个Container。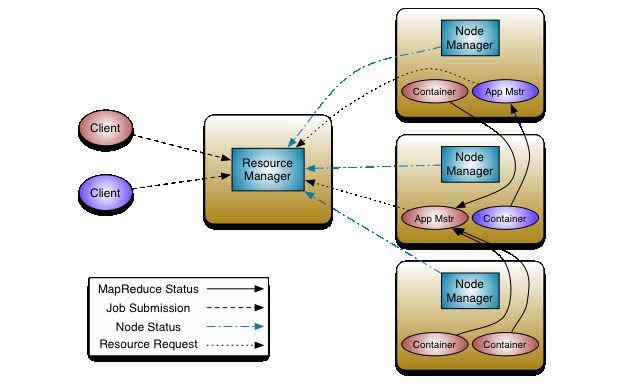
对应到Spark中,一般来说一个Driver或一个Executor跑在Yarn的一个Container里面,而ApplicationMaster是一个特殊的Container,一般为后缀_00001的container。每个SparkContext对应一个ApplicationMaster,每个Executor对应一个Container。
YARN视角的架构:
- ResourceMaster
- NodeManager
- Container
ApplicationMaster:类似于Spark Driver,对应一个SparkContext - Container
普通的Spark Executor - Container
普通的Spark Executor
- Container
- NodeManager
- Container
- Container
- NodeManager
SparkSQL
SparkSQL由4个项目组成,分别为Spark Core、Spark Catalyst、Spark Hive和Spark Hive ThriftServer。我们主要和前两者打交道,Core中就是SparkSQL的核心,包括Dataset等类的实现。Catalyst是Spark的水晶优化器。
DataFrame和Dataset
我们可以将RDD看为一个分布式的容器M[T],我们对T是未知的。而事实上我们处理数据集往往就是个来自HBase或者其他数据仓库大宽表。如果使用RDD会导致很多的拆箱和装箱的操作。并且由于T是一个黑盒,Spark也很难对RDD的计算进行优化。为此,Spark推出了SparkSQL来解决这个问题。而SparkSQL的一个核心机制就是DataFrame和Dataset。
在Spark1.0中,DataFrame可以看做RDD[Row],但在Spark2.0对Dataset和DataFrame进行了统一,DataFrame可以看做一个Dataset[Row],所以,我们主要以Dataset来研究对象。
创建DataFrame
借助于Scala提供的implicit机制,我们可以从Seq创建DataFrame
1 | import org.apache.spark.sql.types.{DoubleType, LongType, IntegerType, StringType, StructField, StructType} |
但是,我们不能从一个DataFrame通过map到一个Row的方式得到另一个DataFrame
1 | val df2 = df.map(row => Row(row.getAs[String]("name"))) |
我们还可以通过createDataFrame从RDD创建一个DataFrame,因为RDD没有schema,所以我们要显式提供一个schema。
1 | val schemaString="name,age,money" |
而这个schema可以通过下面的方法得到
1 | var schema = new StructType() |
这里的StructType和StringType等都是SparkSQL所提供的ADT,它们都继承AbstractDataType,例如LongType的继承链是LongType->IntegralType->NumericType->AtomicType->DataType->AbstractDataType。StructField是add方法的参数,用来描述一个类型。包含四个成员,如下所示
1 | case class StructField(String name, |
当然,还有一些从外部数据源构造DataFrame的工具,如下所示,这里的路径是Driver本地路径
1 | spark.read.json(...) |
此外,Spark还可以从Hive、MySQL、HBase、Avro, Parquet, Kafka等数据源中读取数据。
从RDD到DF/DS
RDD可以通过下面代码中的一个隐式转换 得到一个DatasetHolder,接着借助于DatasetHolder中提供的toDS和toDF来实现到DataFrame和Dataset的转换。
1 | implicit def rddToDatasetHolder[T : Encoder](rdd: RDD[T]): DatasetHolder[T] = { |
其实在上面文件里面还定义了一系列隐式转换所需要的Encoder,例如对于大多数的case class都需要调用newProductArrayEncoder。有关这部分的进一步说明,可以查看文章
同样,从Dataset/DataFrame到RDD可以通过调用.rdd方法来轻松得到。不过这个操作是Action么?在爆栈网上有相关讨论1,认为不是Action但有开销;和相关讨论2,认为是无开销的。我们查看具体代码
1 | lazy val rdd: RDD[T] = { |
从DF到DS
从DF到DS的转换需要指定一个Encoder
1 | val ds = df.as[Person] |
从DS到DF
1 | .annotation.varargs |
Row
Row是SparkSQL的基石。它实际上是一个trait,我们经常使用是它的子类GenericRow和GenericRowWithSchema,而Row的内部实现则是InternalRow。GenericRow是Row从apply创建时的默认构造。它没有schema。在GenericRowWithSchema中重新实现了filedIndex这个函数,允许我们使用row.getAs[String]("colName")这样的方法。在上面的讨论中已经提到,我们不能从一个DataFrame通过map到一个Row的方式得到另一个DataFrame;反而可以从一个Seq得到。其原因就是因为DataFrame有schema而Row没有。我们通过下面的实验来检查从一个Seq到DataFrame的转换
1 | val df = Seq(("Calvin", 18, 1000)).toDF("name", "age", "money") |
GenericRow是Row从apply创建时的默认构造。它没有schema。在GenericRowWithSchema中重新实现了filedIndex这个函数,允许我们使用row.getAs[String]("colName")这样的方法。如果经常使用SparkSQL的API会发现我们不能从一个DataFrame通过map到一个Row的方式得到另一个DataFrame;反而可以从一个Seq得到,我们甚至可以通过Seq(...).toDF(columns)方法来得到一个其原因就是因为DataFrame有schema而Row没有。我们通过下面的实验来检查从一个Seq到DataFrame的转换
1 | val ds = Seq(Person("Calvin", 22, 1)).toDS |
有关Row和GenericRowWithSchema之间的转换,我们可以进行下面的实验
1 | // 复用之前的头部 |
DataFrame里面的Row不是单纯的Row,而是GenericRowWithSchema,相比之前的Row,要多了Schema。
1 | // 查看type,发现是GenericRowWithSchema而不是Row |
只有GenericRowWithSchema有,因此我们可以创建一个GenericRowWithSchema,其实现在org.apache.spark.sql.catalyst.expressions.{GenericRow, GenericRowWithSchema}。
为什么不能在map函数中返回Row
熟悉map函数的人往往比较熟悉下面的函数签名
1 | fmap :: Functor f => (a -> b) -> f a -> f b |
因此容易写出下面的代码
1 | df.map{ |
乍一看,很有道理啊,f就是Dataset,a和b都是Row,是一个很准确的代码了,但一编译发现少什么Encoder,这是怎么回事呢?这篇文章给了答案。
Column
从上文中可以看到,DataFrame中的数据依旧是按照行组织的,通过外挂了一个schema,我们能够有效地识别列。在这种情况下对行的改动是容易的,但是如何对列进行改动呢?一般有两种办法
借助于withColumn
1 | val df = Seq(Person("Calvin", 22, 100), Person("Neo", 33, 300)).toDF |
当然,在$表达式之外,我们还可以使用udf,甚至带条件地进行withColumn
1 | // 除了$表达式,还可以使用udf |
特别需要注意的是withColumn是存在性能开销的。如果我们在代码里频繁(例如使用一个for循环)withColumn,那么就可能出现一个Job结束,而下一个Job迟迟不开始的情况。如果我们将日志等级设置为TRACE,可以看到代码中也存在了很多Batch Resolution的情况。这是因为较深层次的依赖会导致SparkSQL不能分清到底需要缓存哪些数据以用来恢复,因此只能全部缓存。另外文章中还表示会造成大量的Analyzes开销。
1 | // Analyzer.scala |
此外,伴随着withColumn的是UDF或者UDAF的使用,在Spark the definitive一书中指出,这类的算子容易导致OOM等问题。该书中还指出UDF会强迫将数据转换成JVM里面的对象,并且在一次查询中可能重复转换多次,这会产生很大的性能开销。
KeyValueGroupedDataset和RelationalGroupedDataset
不同于RDD的相关方法,DataFrame系列的groupBy和groupByKey会返回两个不同的类型,RelationalGroupedDataset和KeyValueGroupedDataset。一般来说,虽然groupByKey更为灵活,能够生成自定义的key用来group,但KeyValueGroupedDataset只提供相对较少的操作,所以最好还是使用groupby。另外,在group操作之后就没有诸如union的操作,我们需要再显式map回DataFrame。
SparkSQL语法和用法
SparkSQL和DataFrame的交互
一个简单的问题是,在SQL中引用一个DataFrame呢?一个简单的做法是创建一个视图,即通过createOrReplaceTempView。
SparkSQL的上下文
SparkSQL的上下文通过SQLContext维护,它由一个SparkSession持有,并指向其所有者,以及所有者维护的SparkContext。在Spark 2.0之后,大部分SparkSQL的逻辑工作被迁移到了SparkSession中,所以这个类可以被看做是一个兼容性的封装。
1 | class SQLContext private[sql](val sparkSession: SparkSession) |
SharedState
SharedState保存不同session的共享状态,包括下面几个对象
-
warehousePath -
conf,hadoopConf cacheManager
这是SQLContext 的支持类,会自动保存query的查询结果。这样子查询在执行过程中,就可以使用这些查询结果。-
statusStore -
externalCatalog globalTempViewManager
一个线程安全的类,用来管理global temp view,并提供create、update、remove等原子操作来管理这些view。
SessionState
SessionState则包含了这个Session中相关的组件
1 | private[sql] class SessionState( |
构建SparkSession时,Spark内部会构造SessionState,SessionState会构造Parser,Analyzer,Catalog,Optimizer,Planner还有逻辑计划转化为执行计划的方法。SessionState的具体构建如下所示
1 | /** |
这里的SparkSession.sessionStateClassName(sparkContext.conf)具体有两个取值,在使用Hive的时候,是org.apache.spark.sql.hive.HiveSessionStateBuilder,否则是org.apache.spark.sql.internal.SessionStateBuilder,作为in-memory。instantiateSessionState会具体构建sessionState
1 | private def instantiateSessionState( |
而最终是通过一个BaseSessionStateBuilder的子类来构建的,我们以HiveSessionStateBuilder为例介绍。
1 | // HiveSessionStateBuilder.scala and BaseSessionStateBuilder.scala |
SparkSQL的架构总览
总而言之,SparkSQL的解析与运行流程类似于一般SQL的解析与运行流程,包含:
- 将SQL解析得到一个逻辑计划,它是一颗AST。SparkSQL的执行目标就是树根的值,在计算过程中,父节点的计算依赖于子节点的计算结果。通过Analyzer去Resolve,通过Optimizer去优化
- 将逻辑计划转换为物理计划。首先需要为逻辑计划中的节点选择一个最优的物理计划(同样的逻辑计划可能对应多个物理计划),然后需要生成一个可执行的执行计划。
- 调用执行计划生成的RDD的action方法提交一个Job
LogicPlan类
逻辑计划的对应实现是Logical Plan继承了QueryPlan[LogicalPlan]。自己又拥有三个子类BinaryNode/UnaryNode和LeafNode,然后有产生了OrderPreservingUnaryNode等子类。这些Node被另一些子类所继承,这些basicLogicalOperators描述了包括Project/Filter/Sample/Union/Join/Limit等操作。
SparkPlan类
物理计划的对应实现是SparkPlan,和LogicalPlan一样,他同样继承了QueryPlan[SparkPlan]。例如逻辑计划Project就可能产生一个ProjectExec的物理计划。
处理流程
首先祭出一张图。
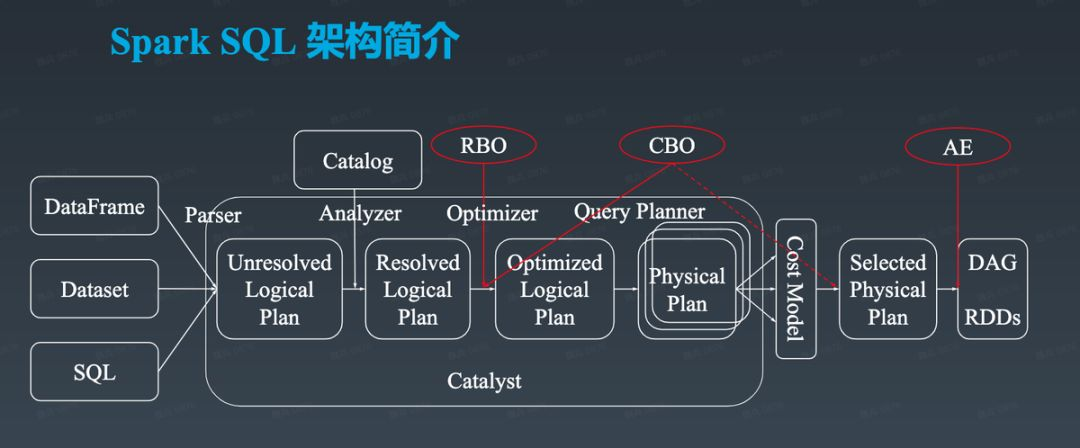
从图中可以看到,SparkSQL首先会对SQL进行Parse,得到一个Unresolved LogicalPlan。这里Unresolved的意思是诸如变量名和表名这些东西是不确定的。Catalog就是描述了SQLContext里面的诸如表之类的对象。在生产环境中,一般由 Hive Metastore提供Catalog 服务。
在Analyzer的阶段借助于Catalog来决议得到LogicalPlan,将Unresolved LogicalPlan决议为Logical Plan。
通过Optimizer,对Logical Plan进行优化。Catalyst主要做的是RBO,但诸如华为等公司和机构也有提出过CBO的方案。
逻辑计划不能被直接执行,它需要通过QueryPlanner.plan得到一系列物理计划,并选择其中一个。QueryPlanner是一个抽象类,它有可以有许多子类实现,这些子类负责将一系列strategies应用到输入的Logical Plan上,订得到一系列candidates: Seq[PhysicalPlan]
1 | // QueryPlanner.scala |
在得到物理计划后,会调用prepareForExecution得到一个可执行的executedPlan。
1 | // QueryExecution.scala |
在Spark2.0前,SparkSQL的主要是采用的Volcano查询引擎模型。Volcano是一种经典的基于行的流式迭代模型(Row-Based Streaming Iterator Model),它在例如Oracle、SQL Server、MySQL等方面都有使用。在Volcano模型中,查询计划树由这些算子组成。这些算子可以看做迭代器,每一次的next()调用,会返回一行(Row)。这next()调用实际上作用在下层算子上,它们把这个下层的输出看做一个表。Volcano具有一些性能方面的缺点,例如next()调用深度可能很深,而每次调用都是虚的,所以有很大的查阅虚表的开销,这给编译器做inline,或者CPU做分支预测都带来了困难。此外,Volcano有很好的pipeline性能,能节约内存,但每获得一次数据,都需要最顶层驱动一次,这雪上加霜。因此在Spark2.0之后加入了WholeStageCodegen机制和ExpressionCodegen机制。
SparkSQL的解析流程
SparkSQL API的执行流程
和RDD一样,Dataset同样只在Action操作才会计算。假设现在已经生成了物理计划,我们选取最典型的count()来研究,以查看物理计划是如何执行的。可以看到,count操作实际上会执行plan.executeCollect(),而这里的plan是一个SparkPlan,qe是一个QueryExecution。
1 | // Dataset.scala |
QueryExecution用来描述整个SQL执行的上下文,从如下示例中可以看出,它维护了从Unsolved Logical Plan到Physical Plan的整个转换流程。
1 | scala> val ds = Seq(Person("Calvin", 22, 1)).toDS |
那么,count()做的就是对qe做一些手脚,然后调用qe.executedPlan.executeCollect().head.getLong(0)。于是我们查看executeCollect()这个方法,他实际上就是execute和collect两部分。execute部分实际上是对getByteArrayRdd的一个调用,得到一个RDD。而collect部分就是调用byteArrayRdd.collect(),这个操作会触发RDD的Action操作,从而提交一个Job。整个函数最终返回一个ArrayBuffer[InternalRow]。
1 | // SparkPlan.scala |
getByteArrayRdd的作用是将一系列UnsafeRow打包成一个Array[Byte]以方便序列化,这个Array[Byte]的结构是[size] [bytes of UnsafeRow] [size] [bytes of UnsafeRow] ... [-1]。
1 | private def getByteArrayRdd(n: Int = -1): RDD[(Long, Array[Byte])] = { |
可以看到getByteArrayRdd中调用了execute方法,execute继而调用doExecute,得到一个RDD[InternalRow]。
1 | final def execute(): RDD[InternalRow] = executeQuery { |
由于SparkPlan是一个抽象类,所以这里的doExecute()没有看到实现,具体的实现根据其操作对象的不同分布在objects.scala上。
那么execute()调用链的终点是什么呢?显然它一定是一个LeafNode的子类。而通过上面的解析可以看到,我们最终得到的一个物理计划是一个LocalTableScanExec,它继承于LeafNodeExec。
map操作分析
在Dataset中,同样提供了诸如map之类的算子,不过它们的实现是从Dataset和DataFrame之间的变换了。
1 | def map[U : Encoder](func: T => U): Dataset[U] = withTypedPlan { |
Spark性能调优
一般来说,Spark可能出现瓶颈的地方有内存、网络和CPU,对于上面的这些问题,宜分为Driver和Executor两块进行考虑
内存方面的向硬盘的溢写、从gc.log中看到的GC的猛增、节点的未响应和OOM。
网络问题的主要场景是诸如Shuffle类的操作涉及在多个节点上传输,节点之间Connection reset by peer。
Spark常见性能问题和选项
总体列表
| 诊断 | 现象 | 解决方案 |
|---|---|---|
| Executor内存不足 | Driver端ExecutorLostFailure,Executor端gc.log显示大量GC和FullGC | 需要考虑Shuffle Read数据过大,或者数据倾斜。对于前者,可以考虑增加分区数或者换个Partitioner,增加Executor内存,增加Executor数量,减少Executor上的Task并行度,提前Filter,使用序列化。 |
| Executor内存不足 | Local Bytes Read+Remote Bytes Read很大 | 考虑是Shuffle Read的问题,同上。需要注意的是当使用groupBy系列算子时,可能一个KV对就很大的,所以增加Executor内存会更保险 |
| Driver内存不足 | Driver端gc.log显示大量GC和FullGC,spark.log中DAGScheduler相关log显示collect算子耗时过长 | 考虑增大Driver内存,避免collect大量数据 |
| Driver内存不足 | Driver端gc.log显示大量GC和FullGC | 减少UDF的使用,减少诸如withColumn的使用 |
| Driver内存不足 | Driver端gc.log显示大量GC和FullGC,Driver的spark.log中出现大量BlockManagerInfo: Added broadcast,并且剩余内存较少,Executor的spark.log中出现TorrentBroadcast: Reading broadcast事件且耗时过长 |
减少broadcast的数据量 |
| 数据倾斜 | 部分Task Retry比较多 | repartition |
| 数据倾斜 | 少数Task耗时显著高于平均值 | 考虑换个Partitioner,扩大spark.shuffle.file.buffer、spark.reducer.maxSizeInFlight、spark.shuffle.memoryFraction,打开spark.shuffle.consolidateFiles |
| 分区过多 | Task执行的时间都很短,但整个Stage耗时较长 | 使用coalesce减少分区数 |
| 分区过少 | Task执行的时间都很长 | 使用repartition增加分区数 |
| Shuffle Spill | 大部分Task执行时间长,但计算量不大 | 增加partition数量,增大Executor内存 |
| Shuffle Write过大 | 部分节点出现FetchFailedException错误 |
|
| RDD重复计算 | 通过Eventlog,追踪Cached的RDD。在同Stage中一个RDD被Cache,那么它的子RDD也会被Cache | 持久化该RDD或使用SparkSQL改写 |
| HDFS IO过大 | 当并行Task过多时,会导致HDFS读取瓶颈 | |
| RM界面显示Tracking URL: UNASSIGNED | 目前App还没启动运行 | |
| RM界面显示State: ACCEPTED | ||
| 计算开销较大 | 减少UDF和UDAF的使用;减少不必要的排序 | |
| 集群缺少资源 | 状态是ACCEPTED而不是RUNNING。Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources | 修改资源 |
替代性算子
为了避免由于Shuffle操作导致的性能问题,常用的解决方案是使用map-side-combine的算子。这个思路就是先将聚合操作下推到每个节点本地,再将每个节点上的聚合结果拉到同一节点上进行聚合,这样能够显著减少通信量。这种方法的常见实践就是采用如下所示的一些替代性算子:
| 原算子 | 替代算子 | 备注 |
|---|---|---|
| groupByKey | reduceByKey/aggregateByKey | |
| reduceByKey | aggregateByKey | 当reduceByKey的输入和输出不一致时,创建临时对象(例如从T变为List[T])有额外开销 |
| aggregate | treeAggregate | 根据实验,treeAggregate具有更好的效率 |
| foreach | foreachPartitions | |
| filter | filter+coalesce | |
| repartition+sort | repartitionAndSortWithinPartitions | |
| repartition | coalesce | 如果目标分区数量小于当前分区数量 |
| flatMap-join-groupBy | cogroup | 避免pack和unpack group操作 |
需要注意的是,减少Shuffle未必就是好的,例如对于coalesce而言,如果产生文件过少,很可能导致Executor空转,并且某些Executor OOM的问题,这就类似于说不患寡而患不均。
使用DataFrame API
使用DataFrame API在下面的几个方面有性能优势。
- Spark Catalyst优化器能够进行优化
- Tungsten优化器的引入带来了三点性能提升(见上文)
有关Persist的优化方案
根据RDD Programming Guide,即使是RDD(DF的话有优化器另说)Spark也可能会自动做persist,具体是发生在Shuffle过程中,这样可以避免在某个Node失败之后还要重新计算全部。但是对于肯定需要复用的数据,显式persist并没有坏处。这里需要注意的是我们要尽量提高RDD的复用程度。
一般来说,如果内存中能够全部放下对象,选择默认的MEMORY_ONLY级别能够最大程度利用CPU,否则就需要考虑使用序列化的MEMORY_ONLY_SER存储。当内存再不够时,就需要考虑将其持久化到磁盘上,但这会带来较高的时间代价。虽然在Spark的较新版本中,通过Unsafe Shuffle可以直接对序列化之后的对象进行sort shuffle,但这不是通用的。
一些Case
Task Retry
我们可以看到,在优化前Job4耗时1.6h,并且Fail了不少。
点进去看一下,发现这个Job里面7重试了两次,花了1h了。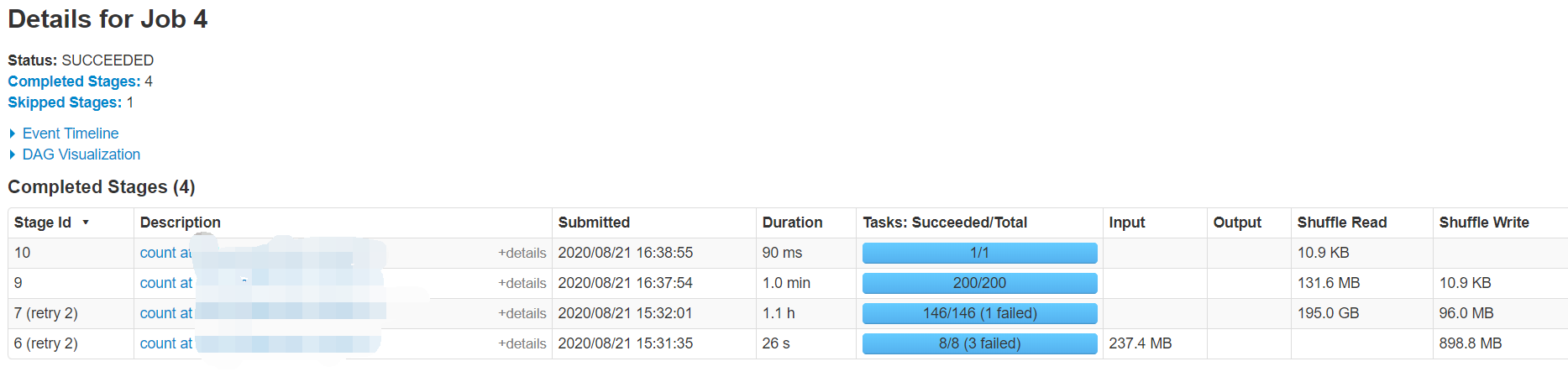
点进去这个Stage看看,他实际上就是一个rdd.join函数的调用。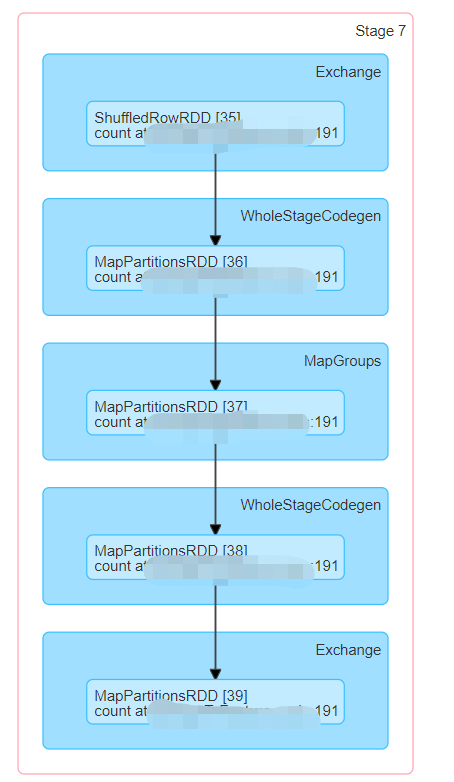
我们可以看到,某个任务的时间达到了1.0h,而其他任务的耗时都在2min左右,因此可以认为这里分区有问题。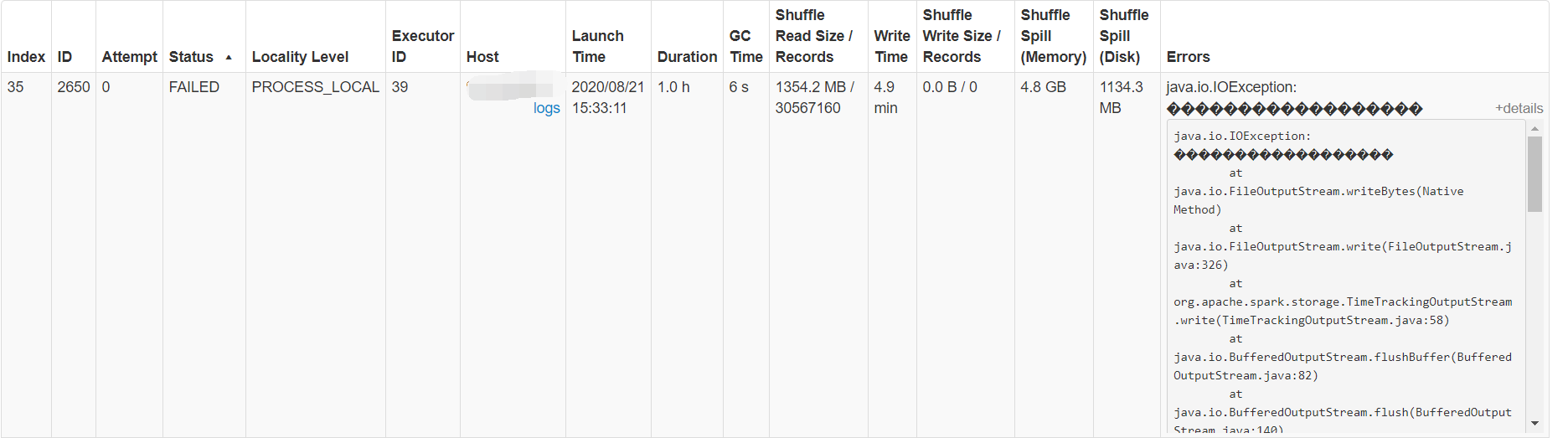
因此,我们在这里重新repartition了一下,现在运行时间缩小到了44min。
Spark日志
Spark会记录Event log,并在History Server或者Spark UI中供访问调试使用。
HistoryServer
Spark提供了History Server以保存Event Log,以便追踪历史任务的性能。History Server部署在18080,可以使用WebUI,也可以使用18080的/api/vi/application的api来请求json版本。
这种方式需要在运行前手动export SPARK_MASTER_HOST=localhost(会被诸如start-master.sh等文件访问修改)或者sh ./sbin/start-master.sh -h localhost && ./sbin/start-slave.sh spark://localhost:7077 可以通过-h指定localhost。不然可能Slave会连不上localhost,因为他会访问你的电脑名字,例如CALVINNEO-MB0:7077而不是localhost。
在spark-defaults.conf中,有关Event Log的配置项有两种,一个是在HDFS上,一个是在硬盘上。
1 | # 硬盘 |
这个在磁盘上,供给History Server用,但是实际上和HDFS的内容是一样的。需要注意的是,一旦spark.eventLog.enabled被设置为True,就需要保证9000是可以访问的,不然可能会报错。
spark log
在每个节点的spark.log记载了这个节点的Spark日志,其中日志从低到高有TRACE、DEBUG、INFO、WARN、ERROR、FATAL等级别。INFO是默认级别。
gc log
在每个节点的gc.log上记载有这个节点JVM的GC情况
常用调试方法
查看RDD的分区数
1
rdd.partitions.size
查看RDD的logical plan
1
rdd.toDebugString
查看queryExecution
1
d.queryExecution
查看schema
1
d.printSchema
查看查询计划
1
df.explain
Spark on YARN的配置参数
在Spark1.2之后,Spark on YARN就已经支持动态资源分配了,当然这个机制在后面的版本中进行了迭代,我们以2.x版本为主进行介绍。主要参考了文章。
Executor数量
有下面的一些字段需要考虑:
spark.dynamicAllocation.maxExecutors/minExecutorsnum-executorsspark.dynamicAllocation.initialExecutors
首先可以通过spark.dynamicAllocation.maxExecutors和spark.dynamicAllocation.minExecutors来限定最大和最小的Executor数量。
一开始Spark会启动num-executors数量个节点,我们可以设置一个较多的Executor节点执行一个小型任务,并跟踪INFO yarn.YarnAllocator,可以发现,最终会减少Executor需要的数量。此外,还有个spark.dynamicAllocation.initialExecutors,根据我的实践,如果同时设定num-executors和spark.dynamicAllocation.initialExecutors,那么后者的优先级通常会更高。我的实践是采用了下面的配置
1 | --conf spark.dynamicAllocation.minExecutors=2 --conf spark.dynamicAllocation.maxExecutors=20 --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.initialExecutors=3 --conf spark.dynamicAllocation.maxExecutors=10 --num-executors 0 --driver-memory 1g --executor-memory 1g --executor-cores 2 |
结果发现,一开始启动了3个Executor,最后变成了2个。

我猜想这是因为如果打开了dynamicAllocation,那么spark.dynamicAllocation相关配置就会更高优先级,而num-executors实际上是一个较为陈旧的配置。我在爆栈网上提了个问题,希望有人能证实我的思想。
与此同时,当设置了spark.dynamicAllocation.minExecutors后,就不能设置spark.dynamicAllocation.initialExecutors或者spark.executor.instances/num-executors。【Q】如果它的值小于spark.dynamicAllocation.minExecutors,对于这种情况会尝试请求spark.dynamicAllocation.minExecutors这么多个Executor。
1 | 20/07/09 15:53:29 WARN Utils: spark.dynamicAllocation.initialExecutors less than spark.dynamicAllocation.minExecutors is invalid, ignoring its setting, please update your configs. |
initialExecutors的设置数量,我司设置是最大数量maxExecutors(然而对外叫num-executors)的平方根。
文章指出,一旦num-executors或者spark.dynamicAllocation.minExecutors配置了,并且实际被分配了,那么就永远不会少于这个数量了,但在上面的实践中感觉并不是这样。根据知乎,应该spark.dynamicAllocation.minExecutors是下限。
当Executor空闲超过spark.dynamicAllocation.executorIdleTimeout,那么就会被移出,可以设置spark.dynamicAllocation.cachedExecutorIdleTimeout来避免移除缓存了数据的Executor。当有Task等待时间超过spark.dynamicAllocation.schedulerBacklogTimeout后,会加入新的Executor。一般来说,如果一个Executor空闲60s后将被移出,而如果有Task在backlog中等待1s将会新增Executor。
需要注意的是,并不是Spark集群得不到spark.dynamicAllocation.minExecutors个节点他就不能运行了。事实上Spark任务在Accepted到Running的阶段,Yarn只会先分配给driver这一个container,然后再由Driver来申请它需要的Executor,这个过程也能从上面的log中看出。
Executor内存和CPU
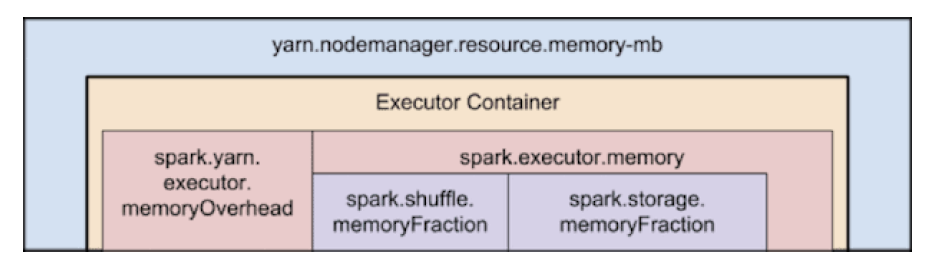
对于yarn来说,每个Node有NodeManager负责管理。NodeManager主要有两个配置:
yarn.nodemanager.resource.memory-mb表示每个node上,每个Container能够最多跑的内存。
需要注意的是--executor-memory/spark.executor.memory不能和YARN中的yarn.nodemanager.resource.memory-mb直接对应,原因是Spark可以请求一些堆外内存,因此实际上要请求(1+spark.yarn.executor.memoryOverhead) * spark.executor.memory这么多的内存,这个Overhead的比例大概在7%左右。然后YARN实际分配的内存也会多一点,具体有yarn.scheduler.minimum-allocation-mb和yarn.scheduler.increment-allocation-mb控制。yarn.nodemanager.resource.cpu-vcores表示每个node上,每个Container能够最多跑的核。这里的vcore应该是YARN的调度概念,申请5个executor-cores,等于要YARN调度5个vcore。
这里需要注意的是,每个NodeManager自己最好也要保留一个核,比如说我们给每个Executor分配3个核,那么在一台16核的机器上,我们正好可以分配5台机器,剩下来的一个核心给NodeManager。
Driver内存
主要考虑collect的大小
Spark常见问题的解决方案
不得不说,Spark的相关问题很多还是比较难调试的,这是因为Spark它的错误日志在打印堆栈时往往喜欢打印它的内部状态,我们很难根据它的内部状态去trace到底是我们的什么操作导致它产生这个问题。并且Spark上处理的数据量规模一般都很大,并且都跑在诸如YARN托管的集群上,这个给Spark调试带了了更大的麻烦。
变量在节点之间共享
当我们需要在节点间共享变量,例如将某个字符串从Driver发送到Executor上时,需要这个变量能够被序列化。特别地,有一个经典的Bug就是Map#mapValues不能被序列化,这个解决方案是在mapValues之后再map(identity)一下。
特别需要注意的是因为RDD是分布式存储的,所以不能够直接当做变量处理,例如下面的代码是不能够使用的。对于这种情况,要么是将其中一个小RDD广播,要不就是将两个RDD去做个JOIN。在SparkSQL中,JOIN操作会被视情况优化为广播。
1 | rdd1.map{ |
scala.collection.mutable.WrappedArray$ofRef cannot be cast to Integer
根据SoF,这个错误就是把Array改成Seq就好了。
Extracting Seq[(String,String,String)] from spark DataFrame
这个错误发生在我们想往一个Row里面放一个类型为Seq的字段的时候。根据SoF,我们可以通过以下的方式来复现这个问题。我们创建了一个以Record为元素的Row,里面有一个content_processed,它的类型是Seq[Feature]),现在我们希望将Record里面的id字段搞掉,我们可以写出这样的代码
1 | import org.apache.spark.sql.Row |
当我们对得到的seems_right执行Action触发计算时,就会得到错误
1 | java.lang.ClassCastException: org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema cannot be cast to $line67.$read$$iw$$iw$Feature |
这个原因还是上面提到的Row的缺陷。其解决方案是借助于Dataset将Row转换为其他的数据结构,例如本命的Record,或者一个能够pattern match这个Record类的数据结构,例如(Long, Seq[(String, String, String)])
1 | df.as[Record].map(_.content_processed).first |
考虑集群机器的问题
集群中有些机器是Power PC(PPC),这些机器可能会去报错
1 | (Possible cause: can't load Power PC 64 LE-bit .so on a AARCH64-bit platform) |
这时候需要设置spark.blacklist.enabled=true把它们blacklist掉。
Spark SQL编写技巧
详见Spark相关机制详解中JOIN相关的章节。
Spark的其他组件的简介
GraphX
GraphX是基于Spark实现的一个图计算框架,能够对图进行建模。GraphX内置了一些实用的方法,如PageRank、SCC等,同时也提供了Pregel算法的API,我们可以利用Pregel来实现自己的一些图算法。目前GraphX似乎还没有实用的Python API,比较方便的是借助Scala。
ML和MLLib
ML和MLLib是Spark机器学习库的两个不同实现。其中MLLib是较老的基于RDD的实现,而ML是较新的基于Dataset的实现
Streaming
Spark相关机制详解
JOIN相关
Spark有三种Join方式,ShuffledHashJoin、BroadcastHashJoin、SortMergeJoin等。这三种方式都会涉及到数据的传输,所以JOIN的代价是比较大的。
前两种属于HashJoin的范畴,HashJoin一般就是将小表做为BuildTable,将大表作为ProbeTable。BuildTable采用Hash进行索引,在JOIN时,对大表进行遍历,并在BuildTable中进行查找JOIN。
后一种SortMergeJoin一般是对于两个大表而言的,将两个表都进行排序,然后采用类似归并排序的办法进行JOIN。问题是,这个过程是怎么并行的呢?一个简单的想法是如果我们Sort时候保证两个表的相同的Key都出现在一个Partition里面,那么对这个Partition做merge,就可以得到完整的结果。Spark是这样做的么?是的,Spark会先做一次Shuffle,把可能被JOIN的Key先划分到一个分区里面。
Repartition相关
我们知道,rdd.repartition只是rdd.coalesce的别名,所以我们讨论后者。按照惯例,先上代码
1 | // RDD.scala |
首先,对于有Shuffle的情况,是CoalescedRDD里面套了一个ShuffledRDD。
首先来看这个ShuffledRDD,是用的HashPartitioner,这个是用key.hashCode,去模numPartitions来进行分区的,很简单。ShuffledRDD的主要逻辑在mapPartitionsWithIndexInternal函数,它会去mapPartitions,然后加上一个表示分区索引的index。这个index是怎么指定的呢?实际上是distributePartition来做的,这个函数接受一个Int,和一个Iterator[T],表示一个分区里面所有的元素。这个函数是随机的,也就是对每个原有分区里面的项目,将它们随机分到某个分区里面,因此它并不保证原来相邻的条目最后还是会落到相邻的机器上。这里Internal的意思就是不会去调用sc.clean(f)。
下面看看distributePartition的具体实现,首先scala.util.hashing.byteswap32是一个积性Hash函数,积性函数是满足f(ab)=f(a)f(b)的函数。不过我算了一下,也没看出来哪里是积性函数了。
1 | scala.util.hashing.byteswap32(100) * scala.util.hashing.byteswap32(2) |
后来看了下wikipedia才知道,这里说的应该是乘法哈希,只是一种哈希算法,类似的还有除法哈希(就是mod)和Fibonacci哈希。这个产生[0..M-1]区间内的哈希值公式是
1 | hash(key) = floor((k A mod W)/(W/M) ) |
其中:通常设置M为 2 的幂次方,W为计算机字长大小(也为2的幂次方),a为一个非常接近于W的数。它的关键思想是提取关键字k中间的几位数字。
不过无论如何,这里只是做一个随机数种子,.nextInt(numPartitions)返回一个0到n之间的随机数。
下面来看这个CoalescedRDD,它有和ShuffledRDD同样的numPartitions。这个partitionCoalescer实际上是Empty,最后用的是DefaultPartitionCoalescer。主要用在CoalescedRDD.getPartitions里面。
1 | /** |
其中withScope的实现是
1 | /** |
它的作用是在给定代码块中创建的RDD具有相同的RDDOperationScope。withScope就像是一个 AOP(面向切面编程),嵌入到所有RDD 的转换和操作的函数中,RDDOperationScope会把调用栈记录下来,用于绘制Spark UI的 DAG(有向无环图,可以理解为 Spark 的执行计划)。
实际上withScope就类似一个代理,为什么要做代理,是因为RDDOpertionScope需要输出一些调试信息。这有点类似于Haskell的Debug.trace一样。
Persist相关
unpersist流程
可以看到,同样是向BlockManagerMaster要求removeRdd。
1 | // SparkContext.scala |
下面就是从BlockManagerMaster里面去掉所有属于这个RDD的块。可以看到,它往所有的BlockManagerSlave发送RemoveRdd消息。
1 | // BlockManagerMaster.scala |
有一次,我们遇到了这样的错误
1 | 20/08/01 13:00:17 ERROR YarnClusterScheduler: Lost executor 144 on xxx: Executor heartbeat timed out after 305856 ms |
Demo
可以通过df.explain看物理查询计划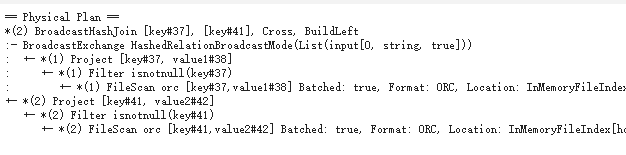
Reference
- https://zhuanlan.zhihu.com/p/67068559
- http://www.jasongj.com/spark/rbo/
- https://www.kancloud.cn/kancloud/spark-internals/45243
- https://www.jianshu.com/p/4c5c2e535da5
- http://jerryshao.me/2014/01/04/spark-shuffle-detail-investigation/
- https://github.com/hustnn/TungstenSecret
- https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-shuffle-UnsafeShuffleWriter.html
- https://blog.k2datascience.com/batch-processing-apache-spark-a67016008167
- https://stackoverflow.com/questions/45553492/spark-task-memory-allocation/45570944
- https://0x0fff.com/spark-architecture-shuffle/
- https://0x0fff.com/spark-memory-management/
- https://www.slideshare.net/databricks/memory-management-in-apache-spark
- https://www.linuxprobe.com/wp-content/uploads/2017/04/unified-memory-management-spark-10000.pdf
- https://www.xiaoheidiannao.com/215670.html
- https://zhuanlan.zhihu.com/p/101797149
- https://mp.weixin.qq.com/s/M29AdSNy90ZoWFO6yP967Q?st=4E4EC5032168C875055B8539D8DF21E00C9505E1A359D84092C936E0CCA66518CF3DD79D1F951211AD4E74EE77C357659C0CF2B38EB5D901EEFFBBB7D1D22FF17B8290AF97D9EA29EF49B69C161D5B249ADA7B55585031E1A95FD955BBDF5FD4FFC52F892F43219C7C42DE53661D9EE72F5049491A75C067E71791364C162E767ECF5B3EE162E7D58566458BB0B55F100D4463EFD264C0E118CF40622573B62E87F319989CFEF3656FB8325659A3E1C2&vid=1688850523686960&cst=A4500263DF343A71C6A77F0747F6E08A9AAD04329A7D1B94AC827AA2C31F1654BE4E436938CB546B8839565025E35997&deviceid=24b21599-d5ef-4ce4-9465-be2e176a6aaf&version=3.1.7.3005&platform=win

