Scala和Kotlin、Clojure等一样是一种jvm语言,传说其复杂度可与C++一较高下。用下来感觉并不舒服,例如其中的implicit特性,能够减少很多代码的冗余,但另一方面,又会导致代码对新手而言的可读性变差。
这篇文章拆分自我从前的文章《使用Scala进行Spark-GraphX编程》。
括号
通常,小括号()表示表达式和函数调用,大括号{}表示代码块。例如在.map({})中的大括号即表示一个代码块。特别地,代码块也是一个表达式,所以下面的代码也是成立的
1 | ( { var x = 0; while (x < 10) { x += 1}; x } % 5) + 1 |
同时,括号也是可以省略的。根据Scala Style Guide,在Scala中,一个无参方法在调用时可以省略小括号。这里注意,如果函数带一个是隐式参数或者默认参数,那么就不能带空括号。
那么如何区分obj.attribute是字段还是方法呢?对此,Scala有统一访问原则(Uniform Access Principle, UAP),也就是指代码不因为属性是通过字段实现还是方法实现而受影响。因此实际上Scala只有两个命名空间,类型和值。
容器
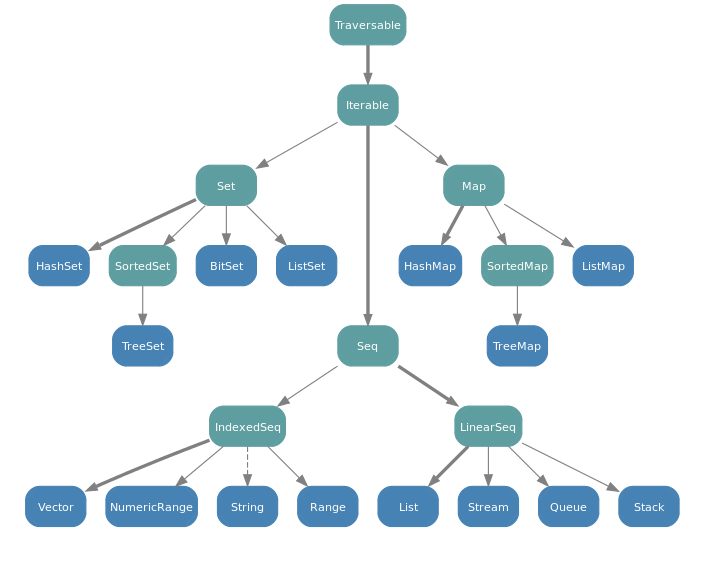
Array/Seq/List
这三个都可以表示线性表,那么他们的区别是什么呢?
首先,Array实际上明确对应了Java里面的数组。例如下面的代码的返回值就是int[]。
1 | Array(1,2).getClass.getSimpleName |
在Java中,我们显然不会把原生数组和容器类型搞混,那么为什么在Scala中,我们就会有这样的困惑呢?原因是
Implicit
在Scala中,可以通过implicit关键字修饰方法/变量、参数、类,对应实现隐式视图和隐式参数。其中隐式视图和隐式参数可以对应到泛型约束中的视图界定和上下文界定。
隐式视图
隐式视图可以实现隐式Casting。如下面的代码所示,错误的原因是没有办法将Double转为Complex,所以和其他例如C++等语言类似,这里需要一个隐式转换。
1 | case class Complex(r: Double, i: Int) { |
如下所示,implicitConvert负责Double到Complex的隐式转换
1 | implicit def implicitConvert(x: Double) = Complex(1.0, 0) |
此外,隐式视图还可以使用目标类的方法来扩展原类的方法。
隐式参数
首先,Scala提供默认函数值,如
1 | def addInt(a: Int, b: Int = 1) : Int = { |
但另一种机制implicit parameter会更为灵活。implicit parameter的用法如下面所示,我们可以为类型People提供一个默认值,这样当我们在调用getName时,就可以给出参数p。
1 | case class People(name: String){ |
可以看到,在一定程度上,默认函数可以起到和隐式参数一样的效果,那么为什么还会存在这个特性呢?我们来查看下面这些问题
- implicit value使用的场合
爆栈网上的这篇文章指出,implicit value是针对类型而言的,所以不应该对一个常见的类型是提供一个implicit值,例如给String提供一个implicit值。此外,定义implicit值的时候,最好定义在伴生对象里面,而我们对String的伴生对象显然是没有控制权的。 - 为什么prefer implicit value呢?
这篇文章讲解了为啥默认参数(DPV)是一个bad practice,包含下面几点:- DPV会让调用者觉得函数的语义不明显
- DPV会让柯里化和Partial Application的行为变得奇怪
- DPV会降低便利度
- DPV会加大refactor难度
另外,implicit参数还可以和ClassTag一同使用,来实现保障类型擦除后类型安全的功能
函数与方法
函数与方法
Scala中的函数和方法的区分让人费解。笼统地来说,函数由val定义,是一个继承了Trait的类的对象。方法由def定义,是组成类的一部分。
因为方法是不可以被赋值的,所以需要通过下划线将函数转为方法,然后进行复制。这个类似于一个eta变换。
1 | def func(a:Long, b:Long) = { |
另外,有时候不通过下划线也能对方法进行赋值。
1 | class Cls () { |
柯里化
Scala函数都是柯里函数,因此支持链式地调用,也支持偏/部分应用。注意偏/部分应用(Partial Applied Function)和偏/部分函数(Partial Function)是两个概念。Scala中的Partia Function是一个Trait,类型为PartialFunction[A,B],它接收一个类型为A的参数,返回一个类型为B的结果。而我们现在论述的是偏应用
1 | val p_func = func(_, 2) |
高阶函数
使用compose可以实现复合函数
1 | scala> (((x: Int) => x + 1) compose ((y: Int) => y * 2)).apply( 11 ) |
模式匹配
Scala使用case来实现类似guard的机制。
解构绑定
Scala可以利用样本类case class来实现对象的解构绑定。case class实际上可以看做对class的语法糖,根据Scala的说明,case class的使用场景就是用来做Structured binding的。
apply和unapply
apply可以把对象当函数用unapply用于unbind一个case class到诸如Seq的结构上
继承和泛型
目前,继承和泛型在一起讲,因为这两个特性经常一起使用。
with和extend
Scala支持通过with去混入(mixin)某个trait。也就是如下的代码,看起来很像带实现的Java的interface,又像分主次的C++的多继承。
1 | abstract class A { |
通过mixin,还可以表示类型,例如Transformer with HasFeaturesCol with HasPredictionCol with MLWritable
逆变与协变
逆变(contravariant)和协变(covariant)是在泛型类语境下的。假设B extends A,也就是B是A的子类。根据里氏替代原则,在不声明逆变协变的情况下,默认是不变的,也就是C[A]和C[B]是雷锋和雷峰塔的关系。
那么协变C[+T]场景下C[B]是C[A]的子类。一个常见的例子是Cat是Animal的子类,那么我们也自然希望List[Cat]是List[Animal]的子类,这样我们的List[Animal]可以接受诸如List[Dog]、List[Cat]之类的参数。
然而在逆变C[-T]场景下,C[A]是C[B]的子类了。看起来反直觉,但实际上是有作用的。例如我们定义了函数Action[Animal]和Action[Cat],顾名思义,我们认为Action[Animal]能够正确处理Animal[Cat],因此我们的Action[Cat]能够接受Action[Animal]作为参数是合理的。
案例解析
1 | object Predef extends scala.LowPriorityImplicits with scala.DeprecatedPredef { |
逆变和协变类型不能被设置为var
之前写Flow啥的时候,发现下面的代码是不能编译的。
1 | class C [+T] { |
根据爆栈网,这种做法其实就是不被允许的。最后我们的方案是直接把Flow的类型参数去掉了,这也导致了我们想取东西的时候需要asInstanceOf[T]一下
类型擦除
在C++中,下面的代码似乎是没有问题的。我们调用getData(),如果此时data是null,那么返回一个新的T()。但Scala里面是会报错的,原因是此时不知道T的类型信息。可是,我明明在new ObjectProxy[CalvinClass]里面传了啊,为啥我还不知道呢?
1 | class ObjectProxy[+T](val data:T) extends Serializable{ |
按照往常我提了个问题,原因显然和Scala的类型擦除机制有关。首先在C++里面,对于模板,是会生成独一份的代码的,但是Java会么?其实在代码中定义的List<object>和List<String>等类型,在编译后JVM看到的只是List,而泛型附加的类型信息对JVM来说是不可见的。既然不可见类型信息,我们又没有办法从传入的参数null中推导得到类型信息,那就只能报错了。
改正方法很简单,把new替换成下面的就行,并且让ObjectProxy继承ClassTag[T]。这里的ClassTag[T]用来保存被擦除的类型信息。
1 | implicitly[ClassTag[T]].runtimeClass.newInstance().asInstanceOf[T] |
下界与上界
类型下界形如U >: T,表示U是T的父类,反之,类型上界S <: T,表示S是T的子类。这个符号的箭头方向永远指向孩子,可以理解为孩子永远是小的,所以小于号指向他。
通常来说,协变常常被用在容器类、返回值上。逆变通常被用在函数和参数上。根据Luca Cardelli规则,就是对输入类型是逆变的,对输出类型是协变的。直观地说,也就是我们可以返回一个更精确的类型(例如返回Object的子类String),接受一个更宽泛的类型。那么这里那里有“泛型”呢?其实我们可以假定一个父类P中有个返回Object的方法,而子类C有个返回String的方法,可以看到P :> C且Object :> String,于是协变的关系从这里得到了。
虽然参数设为逆变导致我们可以接受更为宽泛的泛型类。所以我们通过类型下界来限定我们接受的参数U必须是T的父类。
1 | class Consumer[+T](t: T) { |
反射
常见类型获取函数
1 | import scala.reflect.runtime.universe._ |
下面的情况比较奇特,展示了List[Int]和List[String]具有相同的Class,但Array[Int]和Array[String]的,其本质原因是Array对应了Java中的原生数组,而List是Scala下面的对trait Seq的一个实现。事实上,List下的Class相同但Type不同,而Array下的Class和Type都不同。
1 | import scala.reflect.runtime.universe._ |
Scala的坑
迭代器
Scala的迭代器求size之后会自动到尾部的。
1 | // OK |
split
这个应该是诸如php之类的所有从String去split的函数都会涉及的问题,也就是说到底多个splitter连续出现是什么行为。
1 | "1,2,,,,,".split(",").length // 2: Int |
但是这样还是有问题,因为"".split("").length会等于1。
1 | def getStringArray(k :String, splitter:String):Array[String] = { |
Reference
- https://docs.scala-lang.org/zh-cn/tour/tour-of-scala.html
- https://www.zhihu.com/question/35339328
- https://scastie.scala-lang.org/
- https://stackoverflow.com/questions/27414991/contravariance-vs-covariance-in-scala
- https://twitter.github.io/scala_school/zh_cn/advanced-types.html
- https://colobu.com/2015/05/19/Variance-lower-bounds-upper-bounds-in-Scala/
- https://www.zybuluo.com/zhanjindong/note/34147

