本文是有关InnoDB实现原理的读书笔记,主要包含:
- 《MySQL技术内幕(InnoDB存储引擎)第2版》
- 《MySQL内核:INNODB存储引擎 卷一》
在本文中,主要介绍下面内容:
- MySQL/InnoDB的配置和搭建
- MySQL/InnoDB的宏观架构
- MySQL/InnoDB的日志,以及事务中涉及到日志相关的部分
在本文中,不会详细介绍:
- 刷脏页机制
- MVCC机制
- 索引机制和索引页的维护
- MySQL服务器
配置
InnoDB的源码可以在MySQL项目中获取,具体是在storage/innobase下面。
首先需要执行下面两行,以便创建服务
1 | mysqld --initialize --user=mysql --console |
然后net start mysql,如果出现下面的错误,表示mysql没有初始化,例如data文件夹就没有被正式创建,要使用mysqld --initialize-insecure来初始化
1 | MySQL 服务正在启动 . |
MySQL体系结构与存储引擎
MySQL主要架构
MySQL的架构如下图所示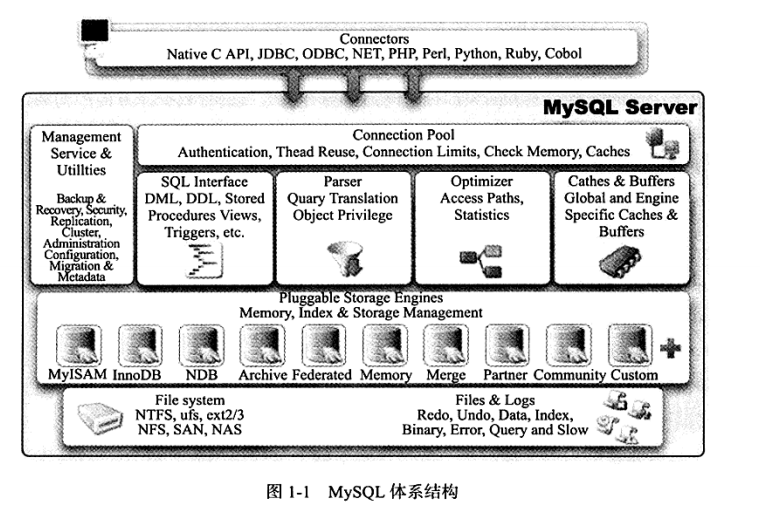
可以通过SHOW ENGINES命令来查看当前MySQL支持的存储引擎。也可以查找information_schema架构下的ENGINE表来实现。
InnoDB的表存储于ibd文件中,通过MVCC实现高并发性,并实现了SQL标准规定的四种隔离级别,默认级别是RR。
MyISAM不支持事务和表锁,但支持全文索引,主要面向OLAP。MyISAM在MYD中存储表数据,在MYI中存储表索引。
InnoDB主要架构
InnoDB的主要架构如下所示。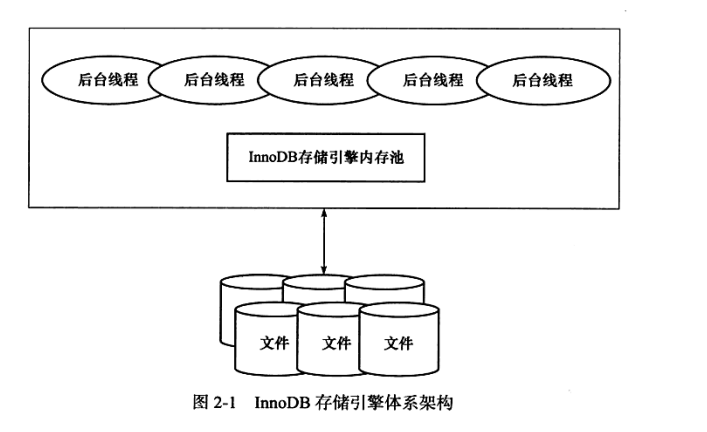
其中主线程中主要根据数据库状态运行主循环(loop)、后台循环(backgroup loop)、刷新循环(flush loop)和暂停循环(suspend loop)四个循环。

若干IO Thread主要分为四类:read、write、insert buffer和log IO,在当前版本下,可以通过innodb_read_io_threads等参数进行设置。
Purge Thread用来回收已经使用并分配的UNDO页,当设置innodb_purge_threads大于0时,该线程会启动,从而减轻主线程负担。
Page Cleaner Thread用来刷新脏页,它也是为了减轻主线程负担。
Log
为了便于理解,先要介绍一些前置知识,这些知识在第3、4章等章节中。
MySQL中有binlog、slowlog、error log、查询日志等日志形式。具体到存储引擎层,InnoDB又有redo log和undo log。
Slow log
通过show variables like 'log_error'\G可以获得error log的存储位置,error log可以定位一些严重的错误,例如MySQL无法启动等问题。slowlog可以定位下面的一些问题:
查询时间超过阈值
1
show variables like 'long_query_time'\G
没有通过索引的查询
1
show variables like 'log_queries_not_using_indexes'\G
用来限制每分钟最大的2的数量
1
show variables like 'log_throttle_queries_not_using_indexes'\G
slowlog的相关信息可以在mysql数据库的slow_log表下面看到,可以通过mysqldumpslow进行展示。
查询日志
查询日志存储了所有对MySQL的请求信息。
binlog
binlog在MySQL 5.1之后的版本引入,记录了MySQL对数据库进行更改的所有操作。可以通过show master status\G获得binlog的存储位置。binlog可以被用来恢复数据、主从复制以及审计(audit),例如统计是否有对数据库的攻击。当sync_binlog==0时,由底层文件系统控制对binlog缓存的刷新。对于InnoDB而言,它将binlog统一写到一块缓存中,等事务提交之后,直接将缓冲中的binlog写入binlog文件,该缓冲大小由binlog_cache_size决定,默认为32K,并且是基于会话的。可以通过mysqlbinlog查看当前的binlog。
redo/undo log
和binlog不一样,redo/undo log是物理日志,记录了数据页的修改,而binlog是逻辑日志,记录了事务的原始逻辑。redo/undo log在事务执行过程中随时写入,而binlog是在事务commit前写入的。
Redo log简介
InnoDB 通过 force log at commit 机制实现事务的持久性。即当事务提交的时候,要首先将 redo log 写入文件进行持久化。注意 redo log 会先被写到文件系统分配在内存中的缓冲区内,但提交的时候 fsync 刷盘。
- O_DIRECT 写
特别地,如果不希望使用文件系统的缓存,需要设置O_DIRECT启用直接IO/裸IO,从用户空间直接将写到磁盘比如说 DMA 上。 - O_SYNC 写
O_SYNC表示 write 操作在操作系统将所有数据发送给磁盘之后才能返回。但可能此时数据还在 hard disk 自己的 cache 中,但无论如何这个不是操作系统能够控制的了。但回答后面的评论还有补充,Linux 对于支持 FUA 的设备,会设置这个位;否则会在写完之后,强制发一个 Flush write cache 的命令。
当然了,通过设置 innodb_flush_log_at_trx_commit 为0,可以不让 InnoDB 在每次提交事务的时候都 fsync,这样的话就依赖于其他两个定时和剩余空间的条件了。当MySQL宕机后,可能会丢失1秒内的事务。特别地,这个值还可以被设为2,此时数据会被写到内核高速缓存中,但不会立即刷入磁盘,在这种情况下,只要系统不宕机,那么MySQL宕机后的安全性也是能得到保证的。
undo log简介以及和redo log的比较
先前提到过,redo log 实际上可以保证事务的 Duration 特性,一旦一个事务被提交之后,redo log 就包含了足够的信息了。
undo log 记录数据被修改前的值,实际上保证事务的 Isolation 特性。undo log 常用的地方是:
- 事务失败时 rollback
- MVCC功能
在 InnoDB 中每个 SQL 语句执行前都会得到一个 read view,其中主要保存了当前活跃,也就是没有被 commit 的事务的ID号。出于 Isolation 的要求,这些事务对本事务是不可见的。
通过读 undo log 链可以看到该条记录的历史版本,可以实现不同事务版本号都拥有自己独立的快照数据版本。
读写和刷盘
通过redo log可以在宕机恢复后恢复已提交的事务,如果没有redo log,就需要在事务commit时完成所有的刷脏页操作。但这个对性能是一个损伤,有了redo log,就可以把日志记到磁盘上,然后异步刷脏页了。通过undo log可以在宕机恢复后回滚未提交的事务,如果有了undo log,在事务提交前也可以刷脏页了。
redo log基本上顺序写的,但是undo log需要随机读写。
redo log存储于形如ib_logfile*的文件里面。此外,redo log是在4GB的空间中循环写的,所以没有归档的功能。如果需要归档,就要借助于类似ib_arch_log_形式的归档重做日志,该日志始终是对ib_logfile1这个文件进行归档。InnoDB一般先会把redo log写到位于内存中的缓冲区内,然后在下面三种情况下进行刷新
- 每隔一秒
- 每个事务提交时
- redo log 缓冲池剩余空间小于1/2
binlog和redo/undo log的协同工作
两阶段提交2PC
需要特别注意,2PC不是2PL。其实我们在专门的文章中已经介绍过原始版本的2PC和3PC算法了,我们将研究这个算法在MySQL中的应用。
在同时出现有binlog和redo log日志时,如何提交事务呢?是先写哪个log?在故障恢复时,以哪个log为准?此外,还要考虑到binlog还被用来进行MySQL的主从复制,这使得Master库的数据实际依赖于redo log,而Slave库的数据实际依赖于binlog,问题更加复杂。例如Master写了binlog,然后还没有写redo log就宕机了,但是这个binlog已经被传给Slave执行了,那主从不一致就会发生。
因此,我们需要设计一套合适的提交流程,两阶段提交innodb_support_xa被用来解决这个问题。此时MySQL会把这个普通事务作为XA事务来处理,但是这个XA事务并不是分布式事务,而是作为内部XA事务。内部XA事务用于同一实例下跨多引擎事务,由Binlog作为协调者,比如在一个存储引擎提交时,需要将提交信息写入二进制日志,这就是一个分布式内部XA事务,只不过二进制日志的参与者是MySQL本身。而对外部XA而言,应用程序是协调者。
MySQL的两阶段提交的实现ha_commit_trans是:
- 写redo log,并标记该事务处于prepare状态
实际上,是调用下层引擎提供的prepare方法。并且会获取prepare_commit_mutex锁。
【Q】此时需要落盘么,还是到第3步落盘?应该是这一步就要落盘了。
【Q】事务的状态会被写到redo log里面么?
此时Duration得到了保障,但是该状态下的事务对其他事务是不可见的。 - 写binlog,binlog和redo/undo log共用一个XID标记唯一事务。
注意binlog也需要落盘。 - 标记事务处于commit状态
【Q】这里应该也会写redo log的吧? - 返回客户端
因此,我们可以回答上面的问题:
- 先写哪个log?顺序是先redolog再binlog。
- 以哪个log为准?以binlog为准,如果binlog上没有记录,说明事务没有提交。
为了保障Crash Safe,需要保证“双1”,也就是之前提到的innodb_flush_log_at_trx_commit和sync_binlog都要设置为1。
【存疑】在崩溃恢复时,从InnoDB的角度来说,需要检查redo log:
- 如果标记了commit,则commit。那么要不要检查binlog了呢?我认为不需要,因为binlog必然是有的,不然为啥redo log能变成commit呢?
- 如果标记了prepare,则检查binlog,如果该日志存在并且完整,则commit,
否则rollback。对于这一步,有说是恢复到prepare的。 - 如果还没有prepare,则回滚。
从MySQL执行的角度来说:
- 扫描最后一个binlog,提取XID
这是因为事务不会跨binlog,并且binlog rotate的时候会刷盘。 - 扫描redo log中所有处于prepare状态的XID,和binlog中最后一个XID比较。如果存在即提交,否则回滚。
Group Commit Bug
上面的过程中,“双1”的要求导致性能是下降的。然而,叫做Group Commit Bug的问题会加重这一点。
首先介绍Group Commit呢。因为fsync的代价很大,所以InnoDB实现了Group Commit技术,也就是将多次事务提交通过一次fsync刷回磁盘。也就是将所有要fsync的事务加入一个队列,由队头的线程负责将队列中所有的事务都一次fsync掉。在这个过程完成之后,队伍中的所有线程都被唤醒,完成自己的事务提交工作。可以看出,通过Group Commit,可以实现“并发”提交多个事务。
然后我们可以得到一个观察,在Group Commit时binlog和redo log日志的顺序未必是相同的。就如下面这张著名的图一样,事务的执行顺序是1/2/3,binlog也是按照这个顺序提交的。但是因为2PC并没有约束不同事务的提交顺序,所以InnoDB可以按照2/3/1的顺序提交。在“On-line Backup Taken”后,Slave的备份中会没有T1的提交记录。
可以看出,二阶段提交能够保证同一个事务的redo log和binlog的顺序一致性问题,但是无法解决多个事务提交顺序一致性的问题。为此,在5.5之前版本的MySQL的做法是在prepare时就获取prepare_commit_mutex锁,并且在事务commit之后再释放。这就导致了prepare、写log、commit这个过程全部是串行的,Group Commit名存实亡。这也就是这个bug的核心内容。
Binary Log Group Commit(BLGC)技术
5.6方案
将原来2PC中的commit拆分为三个阶段:
- flush
多线程按照进入顺序将binlog从缓存写到文件,但不刷盘。 - sync
将文件中的binlog一次性刷盘。 - commit
各个线程按顺序,作commit(这是一个InnoDB过程)。
这三个阶段各自维护一个队列,第一个进入队列的线程成为Leader,和原先的Group Commit一样,代理队列中的所有线程完成该阶段的任务,然后把这个队列全部移动到下个队列中。如果下个队列是非空的,那么Leader需要把自己变成下个队列的Follower。
5.7方案
在5.6的逻辑中,每个事务独立做prepare,并且write/sync redo log,这一部分可能成为性能瓶颈。在5.7版本中,将redo log刷盘的实际推迟到了flush阶段,放到写binlog文件操作前。这样redo log也能实现按Group批量写了。
这种方案的流程:
- flush
刷盘redo log。
写binlog,不刷盘。
如果在这个阶段发生宕机,因为binlog未必刷盘,是易失的,所以可能会导致该组事务rollback。 - sync
binlog刷盘。
通过binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count在时间和数量上控制刷盘。
在这个阶段后,因为binlog已经刷盘,所以在宕机后要提交事务。 - commit
依次Commit该组事务。
由于binlog已经刷盘,所以这个过程并不需要刷盘。
得到如下图所示的2PC过程简图。
LSN
LSN(log sequence number)是InnoDB中的一个长度为8字节的数,表示每个redo log的编号,具体来说,表示事务写入到redo log的字节总量,有点类似于TCP里面的Sequence Number。
下面show status语句中的这些数字,就是LSN。
1 | > show engine innodb status\G |
下面written和flushed的差别,就是写了多少和刷新多少的区别,由于至少保证了每秒都fsync,所以两者差距应该不大。
1 | Log written up to 19739600 |
下面的这些项目,描述了刷脏页和建立检查点的进度。
1 | Added dirty pages up to 19739600 |
LSN存在于redo log、数据页和checkpoint中。在数据页中的LSN,即FIL_PAGE_LSN,表示该页最后刷新时的LSN。同理,checkpoint中也会存放目前已经刷新到的LSN。因为在数据库宕机后,会从checkpoint往后开始刷脏页,所以如果检查点LSN和redo log文件的LSN是相同的,表示所有的刷脏页工作都完成了,就不需要再刷脏页恢复了。
页
InnoDB将数据按层次划分为表空间、segment、extent、page。其中页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为16KB,但可以通过innodb_page_size进行设置。当16KB的页放不下时,就可能发生行溢出,此时数据放在未压缩BLOB页中。
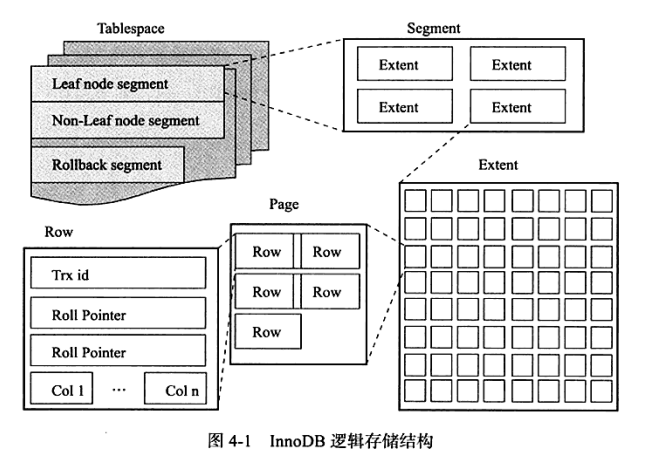
在InnoDB中,页包括
- 索引页(B-tree Node)
因为MySQL使用聚簇索引,所以实际上索引页就是数据页。 - undo页
- 系统页
- 事务数据页
- 插入缓冲位图页
- 未压缩BLOB页
- 压缩BLOB页
数据页的构成如下图所示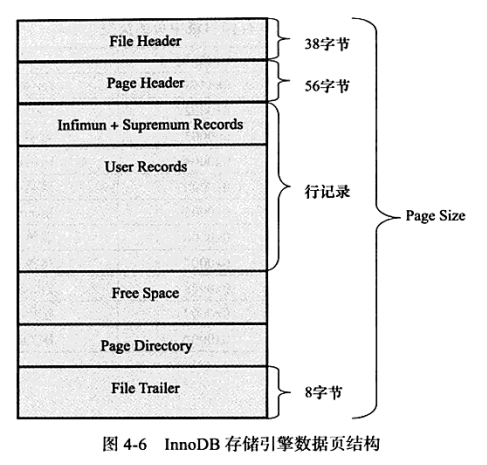
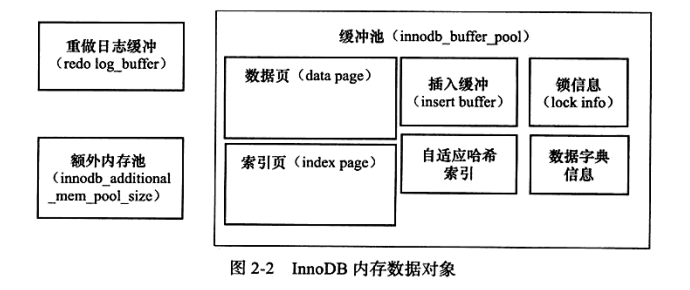
缓冲池
InnoDB设有缓冲池,用来存放从磁盘中读到的页,在缓冲池中的页一般称为逻辑页(page),在硬盘上的页一般称为物理页(block)。在读取页时,首先会尝试从缓冲池中查找,否则读磁盘上的页。
通常,缓冲池中的缓存页类型有索引页、数据页、undo页、insert buffer、adaptive hash index、锁信息lock info、数据字典信息。InnoDB将innodb_buffer_pool_instances设置为大于1,此时可以得到多个缓冲池实例。
缓冲池中的Database pages通过LRU算法进行管理(但adaptive hash index、lock信息、insert buffer等信息并没有放在缓冲池中),将最近使用的页放在最前面。InnoDB为LRU加入了midpoint位置,新读到的页会先放到midpoint,而不是LRU首部,在midpoint之前的称为new列表,之后的称为old列表。当数据库启动时,LRU是空的,这时候首先需要从Free列表中查找可用的空闲页,放到LRU中,否则使用LRU算法淘汰列表末尾的页。可以通过SHOW ENGINE INNODB STATUS观察LRU列表和Free列表的情况。例如,可以通过Buffer pool hit rate(实际没找到在哪里)缓冲池命中率,如果命中率较低的话,需要观察是不是因为全表扫描引起的LRU列表被污染的问题。还可以通过information_schema.INNODB_BUFFER_POOL_STATS观察缓冲池的运行状态。
插入缓冲(Insert Buffer)
我们知道,聚簇索引下,表中相邻行存储的物理顺序和逻辑顺序是一致的,因此一张表只能有一个聚簇索引,InnoDB的聚集索引按照主键进行聚集。
但是,辅助索引是非聚簇索引,对于它们的插入或更新操作,就可能会导致随机读写,从而产生性能问题。
因此,InnoDB引入了插入缓冲,此时不是将数据直接插入到索引页中,而是先判断要插入的索引页是否在缓冲池中,若在,则直接插入;若不在,则先放入到一个insert buffer对象中,这样就可以先返回了。在后台线程中将insert buffer更新(merge)到辅助索引上。
插入缓冲的好处是能将同索引页多个插入合并到一个操作中完成,类似这种多次写合并成一次写的操作,在InnoDB的实现中是非常常见的优化,例如Group Commit等功能实际上也是基于同样的优化思路。
插入缓冲需要满足以下的条件:
- 执行插入或者更新的是非聚簇索引
- 索引不是unique的
反过来想,如果可以是unique的,那么在插入的时候就需要保证此时这个键还没有,而这就要去查索引了。本来插入缓冲引进就是为了避免查索引的,这下每次都要查了,就是南辕北辙,所以插入缓冲是不能对unique适用的。
Change Buffer
Checkpoint刷脏
InnoDB使用Checkpoint的机制将buffer pool中的脏页刷新回磁盘,这样可以抑制redo log和缓冲池的不断增长,同时避免在宕机后通过redo log重头开始恢复造成很大的恢复开销。
Checkpoint分为Sharp和Fuzzy。Sharp会刷buffer pool里面所有的脏页,并且记录下最新的已提交事务的LSN。Sharp产生数据库在某一时刻的一致性数据,如果在运行时发生,会严重降低可用性,因此一般在数据库关闭时用。
Fuzzy只会刷新一部分脏页。Fuzzy主要分为以下情况
- 主线程以一定时间间隔刷新脏页
FLUSH_LRU_LIST
当LRU列表中的空闲也不够时,需要移除掉尾端的页,如果这些页是脏页的话,需要做checkpoint。从MySQL 5.6版本后,这个过程由Page cleaner线程执行。- Async/Sync
- Dirty Page too much
这个很直接,当缓冲池里面的脏页太多的时候,就会触发Checkpoint。
doublewrite
刷盘的过程存在partial write的问题。因为InnoDB的页大小(16KB)通常大于操作系统的页大小(4KB),因此刷盘的过程往往不是原子的。例如当写完第一个4K块之后系统因为停电而宕机,这一块的page数据就会被破坏。
那么redo log能够解决问题么?并不能,因为page已经损坏了,我们怎么知道用什么redo log来恢复这个page呢?【Q】也许可以从某一个checkpoint读取redo log来恢复了?
为了解决这个问题,InnoDB引入双写(doublewrite)策略。也就是在刷盘时,先将脏页写到内存中的2MB大小的doublewrite buffer上。接着doublewrite buffer会分两次,每次写1MB到共享表空间,并且立刻刷盘。在doublewrite刷盘结束之后,在将doublewrite buffer的数据写入真正的数据文件上。
文章指出,在启用主从复制的时候,从库上可以关闭doublewrite功能。
Reference
- https://blog.csdn.net/b1303110335/article/details/51174540
- https://www.cnblogs.com/softidea/p/5977860.html
- https://zhuanlan.zhihu.com/p/349420901
- https://zhuanlan.zhihu.com/p/101571164
- MYSQL内核:INNODB存储引擎 卷一
- MySQL技术内幕(InnoDB存储引擎)第2版
- https://dev.mysql.com/doc/refman/5.7/en/index-condition-pushdown-optimization.html
- https://www.cnblogs.com/xibuhaohao/p/10899586.html
- http://zhongmingmao.me/2019/01/15/mysql-redolog-binlog/
- https://blog.csdn.net/m0_45406092/article/details/112949294
- http://keithlan.github.io/2018/07/24/mysql_group_commit/
- https://www.zhihu.com/question/413276827/
- https://sq.163yun.com/blog/article/188020255134334976
- https://www.cnblogs.com/zhoujinyi/p/3435982.html
- https://cseweb.ucsd.edu/classes/sp16/cse291-e/applications/ln/lecture8.html
- https://www.cnblogs.com/zhoujinyi/p/5257558.html
- https://zhuanlan.zhihu.com/p/343449447
- https://opensource.actionsky.com/20190404-mgr/
- http://jockchou.github.io/blog/2015/07/23/innodb-architecture.html
- http://jockchou.github.io/blog/2015/07/23/innodb-doublewrite-buffer.html

