介绍Percolator论文。
类Percolator系统的环境:
一个KV存储
在 Percolator 中是 BigTable 或者 HBase,在 TiDB 中是 TiKV。
BigTable 可以理解为下面的一个 KV 映射1
(row:string, column:string, timestamp:int64)->string
在 Bigtable 中已经提供了针对单行的跨 column 的事务能力。当然,对于 Percolator 的跨行跨表的事务,这还是不够的。
一个全局授时服务器(TSO)
在 Percolator 中叫 Timestamp Oracle。在 TiDB 中由 PD 提供。
这个授时服务可以给每个事务一个全局的时间戳,从而解决时序的问题。
不过 Spanner 使用的应该是 TrueTime。Client
作为分布式事务的协调者。在 TSO 的支持下,这个协调者实现了 SI 的隔离级别。
所以这个协调者并不是在 BigTable 里面的,而其他数据库的控制节点和数据节点是放到一起的。
Percolator 里面的每个节点都会向 BigTable 进行读写。
Snapshot Isolation
在数据库系统中的事务这篇文章中介绍了快照隔离(Snapshot Isolation, SI)。
在实现 SI 时,需要记录两个时间戳,事务开始 ST 和事务提交 CT。SI 保护了 WW 冲突,其他事务在 [ST,CT] 中的写会和本事务产生冲突。
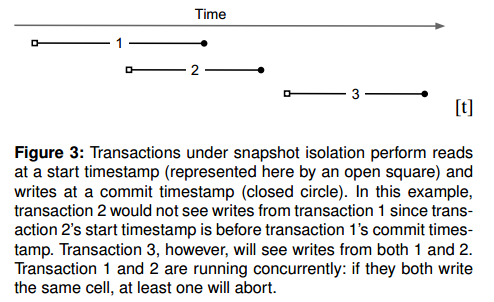
如下图所示,SI 要求在 ST1 开始的事务,能看到所有 CT2 先于自己的 ST1 事务的修改。也就是
1 | ST2 --> CT2 --> ST1 |
2.2 Transactions
因为 Percolator 的协调者是 BigTable 外部的 Client,所以需要自己维护锁。锁具有 replicated、distributed、balanced、persistent 的要求,BigTable 作为存储是支持的,所以这个锁作为 meta 列一同存放在 BigTable 的中。
其实有4个 Meta 列,如下图所示:

- lock
表示一个没提交的事务正在写这个cell。包含了primary lock的位置。 - write
表示是已提交的数据。存放了BigTable的时间戳。
Demo
先来看一个 Demo。一开始 Joe 有2块钱,Bob 有10块钱。现在 Bob 给 Joe 转账7块钱。
- 写
bal:lock加锁 Bob 的账户,这个锁是 primary 的。此外,写bal:data为3,也就是扣了7块钱的 Bob。 - 加锁 Joe 的账户,在
bal:lock里面写一个 secondary 锁,引用对 Bob 账户的 primary 锁。这样在事务挂掉之后,能够知道 primary lock 在哪里,并且把它清理掉。 - 下面进入提交阶段,首先操作 primary lock 所在的 Bob 的账户。需要将
bal:lock清理掉,bal:write写上对应的 ST。通过这个 ST 就能找到实际的数据bal:data。
在这之后,其他的 Reader 就能看到 Bob 账户上只有3块钱了。 - 下面对 Secondary 也进行写记录和删除锁的处理。
【Q】看完Demo,有几个问题:
- 为什么要引入 primary lock?
这个是为了方便进行失败回滚。当事务提交时,会清空 primary lock。因此可以认为如果 primary lock 还在,则事务尚未提交。
例如老事务挂了,留下了一片狼藉的现场。此时,一个新事务可能会访问到老事务残留的 secondary lock,对应有两种情况:- 指向的 primary lock 还在,认为这个事务还没有提交成功。
- 指向的 primary lock 不在了,认为这个事务提交成功。那么必须先继续提交老事务。
- 如果说 secondary lock 被清了一半,怎么办呢?
没问题,后面会讲。实际上有一个优化就是异步清理 secondary lock。 - 写 write 列和清空 lock 是要原子的么?
从 L58 和 L61 可以看到,primary 是原子的,作为一个事务整体提交。但 secondary 不是原子的。 - 在还没有修改 Secondary 时就可以访问新版本数据了,这个不破坏一致性么?
同问题2
实现
下面就分两步来看实现,其实就是对 Demo 的形式化。
整个实现是一个 Transaction 类,包含几个成员:
writes_
这个事务的所有写入。writes_[0]是 primary。
一个 Percolator 事务类似于1
2
3
4
5
6BEGIN
DML/DQL
...
DML/DQL
Prewrite
Commitstart_ts_
整个事务的 ST 时间戳,在事务创建时初始化。Set
往writes_里面加数据。Get
读Commit
提交,首先调用一阶段的 Prewrite,如果全部成功,执行二阶段提交。Prewrite
一阶段,会被 Commit 调用。
Commit 1
Commit 的前几行是封装了一阶段的 Prewrite,省得用户自己去调用了:
- 选择
writes_[0]作为primary,剩余的作为secondaries - 对 primary 做 Prewrite
- 对所有 secondaries 做 Prewrite
1 | 41 bool Commit() { |
先对 primary 进行 Prewrite 是必要的么?此外,在Commit 2阶段也能看到类似的现象。以上两个问题,在 Commit 2这部分讲。
【Q】在第 46 行返回前,可以将已经加了的锁删除掉么?
Prewrite
传入的两个参数,primary 是 writes_[0],primary lock 会在它上面。
需要 lock 所有被写的 cell,在这之前,先对于所有的 cell 检查下面两类冲突:
- 【Line 32】如果发现 cell 的write 列在自己的 ST 之后已经存在一条记录,执行 abort
这实际上是有其他事务已经提交了修改,事务 write-write 冲突了。根据 SI,需要 abort。
【Q】这里有个疑问,SI 不是要到提交的时候再检查冲突么? - 【Line 34】如果发现 cell 的lock 列上有另外的记录,无论 timestamp 是什么,执行 abort
有可能是一个已经提交的事务,并且它的 CT 比我们 ST 还要小,但没来得及清理锁,所以并不是冲突。但 Percolator 认为这个不常见,所以还是 abort。
在文章中还提到可能有失败事务的情况。无论事务是在 Prewrite 阶段还是在 Commit 阶段失败,都可能留下 lock 列上的记录。这个时候,以 primary 上的 lock 为准。如果残留的是 secondary lock,就根据 lock 上的信息找 primary。如果 primary lock 已经无了,就说明事务提交成功,否则说明事务未提交成功。
可以发现,检查冲突实际上就是处理 write 列和 lock 列。这两个检查是优化重点:
- 需要注意,Percolator 是一个事务提交的协议。在提交前,DML 已经执行过了。所以如果事务冲突很多,那么这里会频繁发生回滚。可以进行悲观锁的优化来减少这里的冲突。
- 另一个优化是可以维护一个全局的
min_commit_ts。后面详细说明。
如果没有以上两类冲突,才继续进行:
- 【Line36】更新 data 列,写入 ST,以及真正的值
w.value。 - 【Line37】更新 lock 列,写入 primary 锁的 row 和 col。
1 | 27 bool Prewrite(Write w, Write primary) { |
接下来,进入 Commit 2 阶段。
Commit 2
后面就是提交的第二阶段:
- 【Line48】向 TSO 请求时间戳,作为 CT
- 检查 lock 是否还存在
【Line53】注意,根据“Failure”章节的论述,这里锁可能已经被其他事务清理了。 - 对于primary lock
一旦 primary 对 reader 可见,说明事务提交了。- 【Line55】更新 write 列
write 列中存放了 ST 和 CT。
存放 ST 的原因是可以通过 ST 找到数据,即 data 列。 - 【Line57】移除锁
- 【Line58】提交 BigTable 的行事务,这里就是所谓的 commit point。
- 【Line55】更新 write 列
- 对于所有 secondary lock
- 【Line62】更新 write 列
- 【Line63】移除锁
【Q】为什么在处理 primary 的时候就提交行事务 T.Commit()了?先对 primary 进行 Prewrite 这个行为是必要的么?
原因是 primary 的 lock 列和 write 列是判断整个事务状态的金标准。在 primary 写完 write、清完 lock 之后,就认为事务已经提交,所以就 T.Commit() 了。后面往 secondary 写,只是起到通知作用。
假如往 secondary 写失败了,也不会影响到整个事务的提交。因为 secondary 还是会 redirect 到 primary 上,然后就能发现 primary 的已提交状态。
【Q】写 write 删 lock 是原子操作么?如果不是原子操作,它们的顺序是必然的么?是的,因为这是一个 bigtable 事务。
1 | 41 bool Commit() { |
【Q】ST 和 CT 的关系是什么,会出现事务 2 更晚被启动,但是更早被提交,并且之前的事务 1 反而在它提交之后还能成功提交的情况么?也就是
1 | st1 --> st2 --> ct2 --> ct1 |
我认为不会,考虑:
如果 st2 被提交,说明 st2 设置的 lock,没有被事务 1 清掉。从而事务 2 需要能成功设置 lock。从而事务 2 在 prewrite 时,没有 ts 大于 st2 的 write,在 [0, ∞] 没有 lock。因为 st1 < st2,所以不会有更大的 write,因此只要考虑 lock 就行。那么分为两种情况:
- st1 此时已经提交了,那么 ct1 肯定小于 ct2,假设不成立
- st1 此时还没提交
- 如果此时 st1 已经持有 lock,则 st2 不能上锁成功,假设不成立。
- 如果此时 st1 未持有 lock
如果未持有 lock 的原因是 lock 被事务 2 清理了,那么 st1 就不能提交成功,ct1 无从谈起。
当然 Percolator 中没有提到 Prewrite 清锁。那只能说明此时 Client 的 st1 卡在【line 35】。但这个情况成立么?其实不会,注意到 Line 39 的T.Commit(),可以看出从 31 到 38 行的代码都是作为 bigtable 事务被整体提交的。
Get
首先检查[0, ST]区间内有没有锁。
如果有,说明另一个事务在写,这个读取事务就要等锁被释放(也就是事务完成)后才能继续执行。注意,不能在这里返回旧数据,否则可能导致幻读。这里文章中没解释,我这边的理解是加这个 lock 的事务可能卡着,或者稍后返回超时啥的。如果我现在就根据 write 返回了,那么实际上就不一致了。所以这里我们只能等超时,或者其他事务清理锁。
【Line19】 如果没有锁,就读取最后一次写的数据 latest_write,并且返回对应的 data【Line22】。如果没有读到数据,就返回 no data。
1 | 8 bool Get(Row row, Column c, string* value) { |
Failure
BigTable 能处理自身的问题,但还需要处理 Client 的 Failure。
如果在提交事务时 Client 挂了,Percolator 需要能够清除遗留的锁,否则可能导致后续的事务被 hang 住。这个清除的过程是 Lazy 的,如果事务 A 在执行时遇到了事务 B 的冲突锁,那么 A 会判定事务 B 是否宕掉,并清除锁。
A 在清除锁时,如果事务 B 实际并没有宕掉,而且正准备利用这个锁提交事务,会产生 race。primary lock 就是来解决这个问题的。因为清理或者提交事务都需要通过这个 primary lock,所以事务 A 的清除锁和事务 B 的利用锁提交事务只有一个可能成功:
- 如果提交成功了
- 如果清理成功了,那么事务 B 提交时会发现锁不存在 LockNotExist。这个时候需要用一个新的 ST 重试。因此,当事务中存在依赖查询结果来更新的语句时,重试将无法保证事务原本可重复读的隔离级别,最终可能导致结果与预期出现不一致。
特别注意,在事务 B 提交前,需要检查 lock 是否还在【Line53】,然后才能写 write。同理,在事务 A 清理前,也需要检查 primary lock 是否存在,如果存在,则可以安全清理掉这个 primary lock。看起来挺奇怪的,如果一个锁存在,就清理掉这个锁。
还有一种情况,当事务已经写完至少一个 write 列后发生崩溃,此时可能 lock 还没有全清理完,write 可能没有全写完。此时需要 roll forward 这个事务。
总之,整个判断的原则就是 lock 有没有被 write 取代。
Lazy clean 和 Liveness
因为 eager clean 会导致事务回滚,带来性能开销。所以只有在该事务的锁被认为是属于某个 dead worker 时,才会被清理。
gc 和清理 secondary lock
在前面提到,如果发现一个 secondary lock,则需要查询 primary lock,根据 primary lock 是否存在而决定是否清理 secondary lock。
但考虑一个特殊的情况,在数据库实现中都会加入 gc 机制,用来清理过时的数据。如果允许 primary lock 被作为过时数据清理掉了,那么实际就无法分清 primary lock 不存在是因为被 gc 清理掉了,还是因为被提交而清理掉了,进而无法判断是否要清理 secondary lock。
所以,gc 逻辑不能直接清理 secondary lock。
Timestamps
TSO(Timestamp Oracle)服务会阶段性地分配一段区间,并将这段区间的最大值持久化,剩下的时候就可以直接从内存提供服务。当 TSO 服务重启时,timestamp 就会来到持久化了的最大值上。
为了减少 TSO 的压力,每个 Percolator worker 会 batch 自己的请求为一个 RPC 发送给 TSO 服务。当 TSO 的负载变大时,Percolator的batch大小也会变大。
Percolator的事务性要求 Get() 操作会返回它的 ST 前所有已经被提交的写。考虑一个事务 R 在 TR 读,另一个事务 W 在 TW 提交了写,且 TW < TR,则 R 能看到 W 的写。因为 TW < TR,那么 TW 一定在 TR 的 batch,或者 TR 之前的 batch 中。因此可以得到下面的顺序
1 | W lock -> W request TW -> R get TR -> R read |
实际上,在 R 读取前,W 至少已经写完所有的 lock 了。所以 R 要么读到锁,要么读到已经被写完的数据。
从这里,也可以看出加锁的意义之一。考虑下面的执行顺序,如果不加锁,R 就不能知道 W 在写。因为 Commit(row1) 的 CT 是小于 Get(row) 的 ST 的,根据 SI,TR 需要能读到 Commit(row1) 的结果。如果 R 不管不顾直接读了,而 Commit(row1) 又是在读取之后发生的,那么 R 实际上就读到了 Commit(row1) 之前的结果。
1 | Transaction W Transaction TR |
分析
ACID 性质
相比于 RR,SI 不会出现幻读问题,但会出现 write skew 问题。通过 select for update 可以解决 write skew 问题。
Percolator 和普通 2PC
Percolator 改进了普通 2PC 协调者的单点问题。
TiKV 的实现
注意,需要区分事务 commit 和 percolator 的 prewrite 和 commit 阶段。在事务执行 commit 前,其内容在内存中。在执行 commit 后,才会执行两阶段提交。
优化锁冲突
乐观事务和悲观事务
乐观事务就是标准的 Percolator 的 2PC 实现。
悲观事务需要区分快照读和当前读:
- SELECT 是快照读,读的是事务开始前的版本。
- DELETE、UPDATE、SELECT FOR UPDATE、INSERT 是当前读,读的是当前的版本。
如果使用当前读,则需要加悲观锁。
但是 TiKV 不支持间隙锁,所以 range 内的 DML 不会被 SELECT FOR UPDATE 阻塞。
关于悲观锁的实现细节在随后章节中介绍。
min_commit_ts
当一个事务被提交时,将更新 min_commit_ts。因此在判断读写冲突的时候,可以先比较自己的 start_ts 和 min_commit_ts,以减少冲突检查的开销。
悲观锁的实现
TiKV 的悲观锁实际上就是将原本要在事务提交阶段加的锁提前到 DML 阶段了。如下图所示。
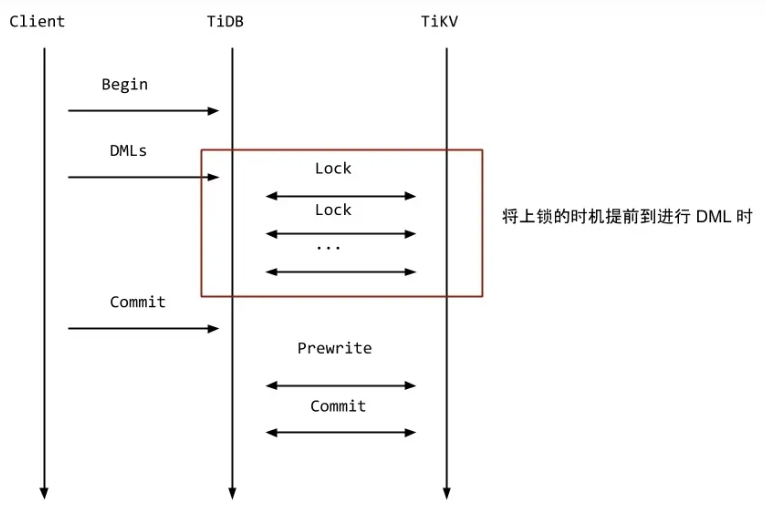
对图上几点进行说明:
- TiKV 的悲观锁和其他数据库的悲观锁仍有不一致。TiKV 需要在执行 DML 之后才会加锁。其他数据库一般在读的时候就上锁,然后才执行 DML 进行修改
- 悲观事务需要从 pd 取一个 for_update_ts,而不是用一开始的 start_ts 去读
否则只能读到 start_ts 之前的数据,不能读到后面的修改了。如果不能读到后面的修改,那么就无法判断后面产生的冲突了。
自然而然地,如果使用 for_update_ts 读到一个冲突,那么就可以更新 for_update_ts,然后用它继续尝试加锁。而不需要整个回滚 start_ts。
但是这里不能使用 max_ts。这是为了避免在执⾏ DML 后加锁之前数据被其他事务修改,从而破坏 SI。 - 即使一个 key 不存在,TiKV 也会上锁。
- TiKV 也不会对 DML 中每个要修改的 key 都上锁
对 Insert,只上锁 unique index 和 row key。
对 Delete,只上锁 row key。
对 Update,会上锁 old row key。如果 new row key 不等于 old row key,则上锁 new row key。如果新的 row 中有新的 unique index,则上锁 unique index。
Resolve Lock
https://zhuanlan.zhihu.com/p/447978561
SI 处理锁
SI 相比 RC,要多一个 load_and_check_lock 的过程。
check_lock 检查锁:
- 如果锁的 ts 比读事务的 start_ts 要大,忽略这个锁。
因为根据 Percolator,只检查 [0,ST] 的锁。
为什么会出现更 recent 的锁呢?这是因为读事务开始后,可能有新的写入,或者我们在 stale read。 - 如果我们的 ts 是 MAX,并且这是一个 primary lock,说明意图就是找最近提交的,也忽略这个锁。
- 否则,这里就是被锁的。返回一个
Err(Error::KeyIsLocked())。
1 | pub fn check_lock(key: &Key, ts: u64, lock: Lock) -> Result<()> { |
顺序读
考虑在 [lb, rb] 区间中扫 scan_ts,它大概就是从 lb 往后面扫,对于所有要查询的 user key,跳过 commit_ts > scan_ts 的版本,然后选择第一个 commit_ts <= scan_ts 的版本。但是要考虑有锁的情况。
介绍几个不变量:
current_user_key是min(user_key(write_cursor), lock_cursor),它表示正在处理的 user key,这个 key 可能没有 write,也可能没有 lock。has_write表示current_user_key是否至少有一个 write。如果有的话,就是self.cursors.write正在指向的位置。这个位置一定是最新的,也就是 commit_ts 最大的位置。has_lock表示current_user_key是否有一个 lock。如果有的话,就是self.cursors.lock正在指向的位置。
讨论四种情况:
- 无 write 无 lock
简单的查不到值。 - 无 write 有 lock
对于 RC,就是查不到。
对于 SI,需要检查锁冲突。 - 有 write 无 lock
需要进一步找到要的 version。 - 有 write 有 lock
因为此时 write 和 lock 上指向的 user key 未必一样,比如有个 user key 就没有 write 之类的,所以先比较 user key。
如果 write 的更小,说明对应的 user key 上没有锁,忽略这个 lock。
如果 write 的更大,说明对应的 user key 上有锁,但是没 write,但我们需要检查 lock 是否带来锁冲突。
如果相等,说明 write 指向的 user key 上有一个对应的 lock。
如果有 lock,则调用 self.scan_policy.handle_lock -> scan_latest_handle_lock。这个函数中只对 SI 进行额外处理,如果认为有锁冲突,就返回 HandleRes::Skip(current_user_key),否则就调用 move_write_cursor_to_next_user_key 更新到下一个 user key。handle_lock 的返回不会产生 HandleRes::Return。move_write_cursor_to_next_user_key 这个函数会尝试 next 最多 SEEK_BOUND 即 8 次,如果再找不到下一个 user key,就直接 seek 了。
如果有 write,即使前面已经处理过 lock,同样还是要处理的:
- 如果有锁冲突,此时在处理下一个 user key
- 否则在处理当前的 user key
调用 move_write_cursor_to_ts 将 cursor 移动到 self.cfg.ts 位置,可能能找到,可能找不到,分别返回 Ok(true/false)。
此时已经到达了第一个大于等于 ${user_key}_${scan_ts} 的位置了。然后是两个 Policy,LatestKvPolicy 表示可以直接读了。读完之后,需要前进到下一个 user key 处。
LatestEntryPolicy 还需要往后扫一下,有没有 WriteType::Lock 或者 WriteType::Rollback。这里不是很懂了。
Refernce
- Large-scale Incremental Processing Using Distributed Transactions and Notifications
Percolator论文 - http://mysql.taobao.org/monthly/2018/11/02/
阿里数据库月报,对Percolator有较为详细的介绍 - https://www.jianshu.com/p/05194f4b29dd
一个简单翻译和个人理解 - https://github.com/tikv/tikv/blob/v3.1.0/src/storage/mvcc/reader/util.rs
SI 的 check_lock - https://cn.pingcap.com/blog/tikv-source-code-reading-13
介绍顺序读 - https://juejin.cn/post/6850418105563217934
- https://docs.pingcap.com/zh/tidb/dev/dev-guide-transaction-restraints
- https://tidb.net/blog/7730ed79
悲观锁

