本文主要讲述数据库中事务的控制模型、事务隔离等级和事务并发控制。
本文从分布式一致性和分布式共识协议一文中分离。主要以 DDIA 和 A Critique of ANSI SQL Isolation Levels 这篇论文为脉络。
两种事务控制模型
ACID
对于关系型数据库,存在 ACID 事务控制模型维护事务的正确可靠性。
- 原子性(atomicity)
事务中的所有操作要么全部完成,要么全部回滚,不会出现中间状态,也就是所谓的 all-or-nothing。以转账为例,假设 A 向 B 转账200元,那么原子性要求事务不存在 A 的钱扣了,但是 B 的钱没到账。
注意原子性不蕴含并发事务的概念,后者是隔离性。
原子性实现需要 REDO log/UNDO log。例如故障恢复时,如果决定回滚事务,则参照 UNDO 来回滚;如果决定提交事务,则参照 REDO 来提交。 - 一致性(consistency)
在事务开始前和结束后完整性约束(不变量invariants)不被破坏。这里的”一致性“常被称为“内部一致性”,以区别分布式系统中的外部一致性。
这里的不变量,往往是由上层应用程序来实际定义的。 - 隔离性(isolation)
数据库支持多个并发事务同时进行增删改。以转账为例,假设 A 和 B 同时向 C 转账 200 元,那么结束后 C 应当收到 400 元,而不是 200。
在传统的数据库中,隔离性可以被形式化为 Serializability,也就是说每个事务可以看作自己是整个数据库上唯一运行的事务。而事务提交的顺序,犹如它们是逐一运行一样。
隔离性通过并发事务控制手段,如锁等解决。
【Q】如何唯一区分事务呢?例如,对一个有序的 tcp 连接,begin 和 commit之间的是一个事务,但如果涉及到重连的情况呢?所以需要生成一个唯一的事务 ID。 - 持久性(durability)
事务结束后对数据的修改是持久化的。例如系统发生宕机后,已提交的事务不应当消失。丢数据的一个常见例子是主从架构+异步复制,如果主节点没有完成复制,则数据会丢失。还可以考虑以下情况:- 写入磁盘后,机器宕机
- 停电,此时对固态硬盘而言,可能 fsync 无法保证正常工作
- 硬盘上的数据随时间推移变得不可靠,SSD 还会对温度敏感
BASE
BASE 理论,即 Basically Available、Soft State 和 Eventually Consistent,是相对于 ACID 准则的另一种事务控制模型,常被用在一些非 RDBMS 的事务控制的 NoSQL 中。
在分布式系统的上下文下,BASE 可以看做是对 CAP 理论做出的一种权衡,通常被以最终一致性的形式实现。我们将会在分布式一致性和分布式共识协议中进行讨论。
分布式事务
单对象事务和多对象事务
故障恢复
WAL
在关系数据库中常使用预写式日志 Write ahead log(WAL) 算法,WAL 要求在数据实际写入之前先写日志,这样能够保证在故障发生后能通过日志进行恢复。相比于将数据实际插入数据库,WAL 由于是顺序读写,所以相对来说要快很多。
事务只有两种完成方式,提交即全做事务中的操作,和回滚即全不做事务中的操作。在事务的中间过程中可能对数据块的值进行修改,但最终这些修改必须要通过提交和回滚来 commit。
- AI,后像,After Image
指的是每次更新时数据块的新值。对于一个已提交的事务,当故障发生时必须 REDO 它的后像。如果 UNDO 它的前像,会破坏持久性约束。
事务提交前任意的删改必须通过 UNDO 来撤销。 - BI,前像,Before Image
指的是每次更新时数据块的旧值。对于一个未提交的事务或提交进行到一半,当故障发生时应当 UNDO 它的前像。
UNDO 和 REDO 操作具有幂等性,即对前像 UNDO 或对后像 REDO 任意多次,结果都是相同的。
那么 REDO 操作和 UNDO 操作是不是缺一不可的呢?其实不然,需要和下面两个刷盘的策略组合起来看:
- Force
表示事务在 commit 之后是否要立即刷盘。
容易发现,如果不立即刷盘,则有丢失后像的风险,那么就必须要有 REDO。 - Steal
表示事务在 uncommit 时,是否可以刷盘。
如果允许未提交就刷盘,那么磁盘上就可能存在脏数据,那么就必须要有 UNDO。
通过 undo 和 redo的配合,能够提供性能更好的ACID特性。如果事务是 Force 的,那么就必须保证在提交的同时刷脏完成,这样会拖累性能。如果事务是 No Steal 的,那么对于大事务就不能异步刷脏。在有关innodb介绍的这篇文章中会详细介绍。
Shadow paging
事务更新的两条规则
提交规则
后像必须在提交前写入非易失存储器中。当后像只写入日志而没写入数据库中也可以提交事务,此时需要在恢复后 REDO 后像实现恢复。
先记后写规则
数据库中有先记后写原则,如果在事务提交前将后像写入数据库,则必须首先把前像记入日志。这样在事务提交完成前如果宕机,可以通过 WAL 来 UNDO 到前像。此时即使数据库没有被修改,也只是进行一次多余的 UNDO 操作。
事务的隔离等级
ANSI/ISO SQL-92 定义了 4 个隔离级别,这个定义借助于三个禁止的操作子序列,被称作 phenomena,包含脏写、脏读、不可重复读和幻读。
简写符号
在 A Critique of ANSI SQL Isolation Levels 列出了一些简写符号:
- w1[x]
表示事务1对x的写 - r2[y]
表示事务2对y的读 - c1
表示事务1提交 - a1
表示事务1中止
常见并发问题
如下图所示 P0…Pn 列出了面临的一些并发问题。下图中的行为隔离登记,列为可能发生的 phenomena。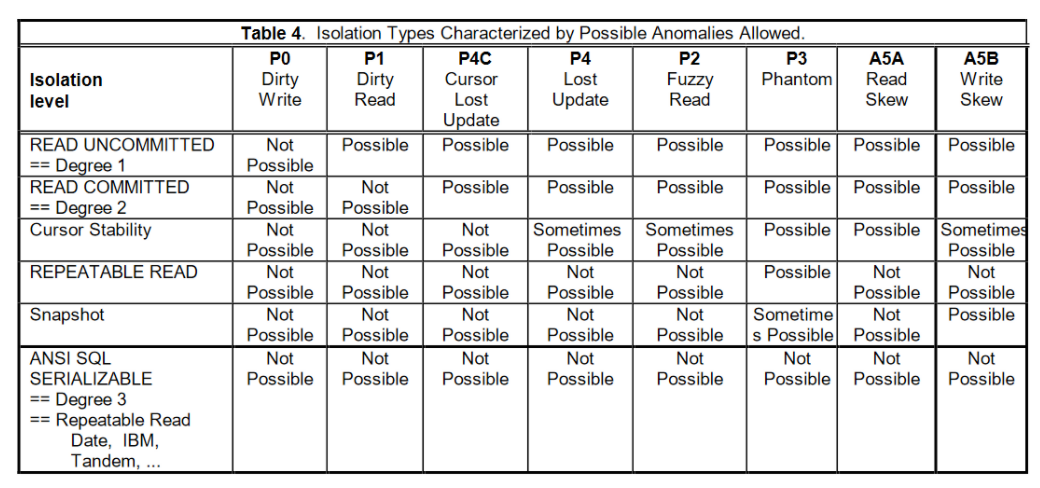
【P1】脏读(Dirty Read)
读到未提交的数据。考虑下面的序列
- A 写入 X 值为 x1
- B 读出 X 值为 x1
- A 回滚
- B 读出的 X=x1 是不合法的,因为它读到了未提交的脏数据
避免脏读意味着避免下面的情况:
w1 [x] ... r2 [x] ... (a1 and c2 in either order)w1[x] ... r2[x] ... ((c1 or a1) and (c2 or a2) in any order)
相比上一个,更为宽松,因为它并不规定事务1一定中止,事务2一定提交了,所以禁止了4种可能的事务结束方式。
【P0】脏写(Dirty Write)
如果两个事务同时写相同的对象,就会发生写写冲突。不加处理,实际在后面写入的数据会覆盖掉实际在前写入的数据。
但如果前写入的是尚未提交事务的一部分,那么后写入的会覆盖一个未提交事务的写,这就是所谓的脏写。
解决脏写的方案就是延迟后面的写操作。
【P4】写丢失/丢失更新(Lost Update)
主要分为两种:
回滚丢失
SQL标准定义的所有隔离级别都不允许这种写丢失。
覆盖丢失/两次更新
指的是一个事务写入的值被并发事务中的后续提交写入覆盖。可以把写丢失认为一种特殊的写偏斜问题。
需要区分脏写和丢失更新(lost update)两个概念。丢失更新强调的是事务提交后的更新丢失,实际上还是一个不一致的状态。例如 DDIA 中图7-5所示,两个事务分别尝试将自增计数器从41增加到42并提交,自增计数器的最终值是42而不是43,违背了一致性,这就是一个更新丢失现象。
解决此类写丢失问题,通常有下面几种方案:
原子写
1
UPDATE counters SET value = value + 1 where key = 'foo'
显式锁定
select for update 会对 select 出来的每一行上加上排他锁(X锁)。1
2
3
4begin transaction;
select * from figures where name = 'robot' for update;
update figures set position = 'c4' where id = 1234;
commit;由事务管理器进行检测,对造成写丢失的事务进行中止
CAS
1
UPDATE counters SET value = new_value where key = 'foo' and value = old_value;
这种方案需要考虑数据库是否支持,例如数据如允许 where 子句从旧快照中读取的话,那么这个语句就未必有效。
【P4C】Cursor Lost Update
【P2】不可重复读(Fuzzy Read)
不可重复读(Fuzzy Read)会导致事务 A 中两次同样的查询得到不同的结果,一次是并发事务 B 提交前的数据,一次是事务 B 提交后的数据。可以考虑下面的序列:
- A 读取 X 值为 x1
- B 写入 X 为 x2
- B 提交
- A 读取 X 值为 x2,它不等于上次读到的 x1 了
- A 提交失败
避免不可重复读意味着避免下面的情况(P2):
r1[x] ... w2[x] ... c2 ... r1[x] ... c1r1[x] ... w2[x] ... ((c1 or a1) and (c2 or a2) in any order)
【A5A】读偏差(Read skew)
根据 DDIA,不可重复读也被叫做读偏差。这里的 skew 指的是 timing anomaly。
下面就是一个读偏差问题。Alice 有 1000 块钱,在两个账户上。然后她想从一个账户转 100 块钱到另一个账户上。她可能会见到在某个时刻自己只有 400 + 500 块钱。可以看到下图中两个 select,第一次发生在收到钱前,第二次发生在转出钱后。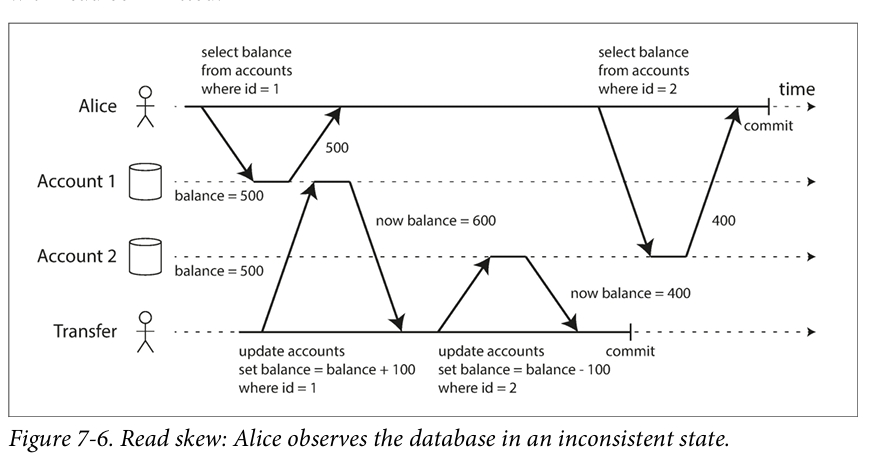
称为不可重复读的原因是如果再次读取收钱账户,那么就能看到有 600 块钱了。
Read skew is considered acceptable under read committed isolation: the account balances that Alice saw were indeed committed at the time when she read them.
尽管 Alice 可以再次查询,但是在某些系统中,Read skew 会产生比较大的问题:
- Backups
备份工作比较耗时,容易导致一部分是新数据,一部分是旧数据。 - Analytic queries and integrity checks
Snapshot isolation is the most common solution to this problem. The idea is that each transaction reads from a consistent snapshot of the database-that is, the transaction sees all the data that was committed in the database at the start of the transac
tion. Even if the data is subsequently changed by another transaction, each transaction sees only the old data from that particular point in time.
MySQL 则是选择借助 MVCC 来解决。我理解这里的核心都是为数据引入时序。DDIA 的解释更加直白,它认为 MVCC 是实现 SI 的方式。
To implement snapshot isolation, databases use a generalization of the mechanism we saw for preventing dirty reads in Figure 7-4. The database must potentially keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time. Because it maintains several versions of an object side by side, this technique is known as multiversion concurrency control (MVCC).
If a database only needed to provide read committed isolation, but not snapshot isolation, it would be sufficient to keep two versions of an object: the committed version and the overwritten-but-not-yet-committed version. However, storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well. 一个经典的做法是 RC 对每个 query 用一个 snapshot,而 SI 会对整个事务用一个 snapshot。
Repeatable read and naming confusion
DDIA 解释了下 Snapshot Isolation 和 Repeatable Read 之间的关系。DDIA 认为 RR 这个说法不够精确。我觉得可能只能认为有幻读问题的是 RR,有 Write skew 问题的是 SI 这种比较基于经典实现方式的命名了。
【A5B】写偏差(Write Skew)
两个并行事务都基于自己读到的数据集去覆盖另一部分数据集。
串行化情况下两个事务无论何种先后顺序,最终将达到一致性状态。而 Snapshot Isolation 隔离级别会有 Write Skew 问题。
考虑事务 P 和 Q。P 试图执行 x=y,Q 试图执行 y=x。从事务隔离性的观点来说,事务 P 和 Q 都期望最终 x 等于 y。但是 SI可能存在下面这种情况:
- P 读 y
因为使用了 SI,此时读到的是 y 的原值,不妨令为2。 - Q 读 x
同理,读到 x 的原值1。 - P 将读取的值 2 写入 x
现在 x 等于 2 了。 - Q 将其读取的值 1 写入 y
现在 y 等于 1 了。
也就是说,x 和 y 的值交换了。这个不仅不符合我们的期望,也破坏了完整性约束,从而导致数据库不满足一致性。另一些写偏差的例子:
- on call 系统
约束:至少有一个医生 on call。
假设 A 和 B 在同时开启申请不 on call 事务,可能发生:- 事务 P 检查今晚有多少个医生可以 on call,发现至少有两个医生 A 和 B。
- 事务 P 通过了 A 的请假。
- 在快照隔离下,事务 Q 通过读取快照同样发现至少有两个医生。
- 事务 Q 也通过了 B 的请假。
- 违背了完整性约束:至少有一个医生 on call。
- 电影卖票
如果使用 SI,则可能一张电影票被卖两次。
写偏差可以看作写丢失(Lose Update)的一般化。如果两个事务读取相同的对象,然后各自更新一些对象,那么就可能发生写偏差。
写偏差涉及不同的对象。但特别地,如果它们更新的对象是相同的,那么可能发生脏写或者写丢失。
现在讨论之前解决写丢失的一些方案是否还能适用于解决写偏差:
- 原子写
这个肯定不适用了,因为原子写只能涉及一个对象。 - 显式锁定
这是可行的,但需要显示锁定事务所有依赖的行。
例如需要锁定 x 和 y。 - 事务管理器
- 配置约束
可以通过触发器或者物化视图来实现。
例如约束至少有一个医生 on call。 - 更新隔离级别为 S。
Phantoms causing write skew
这里 DDIA 实际上统一了幻读和 write skew 的概念,我觉得很值得读一下。它描述了这一类错误发生的 pattern:
- 一个 SELECT 查询会检查一些 requirement 是否满足。
- 根据上一个 SELECT 查询的结果,事务会决定是 abort 还是 continue。
- 如果事务继续,就可能写一些 DML,并提交事务。
这些 DML 会修改 step 2 中所援引的 precondition。换句话说,如果这个时候再 SELECT 一下,就能得到另一个结果了,因为 write 会改变 SELECT 应该返回的结果集。
【P3】幻读
例如如果另一个事务在对其他的数据进行修改,例如在数据表中插入了一个新数据,在 RR 下会产生幻读现象,也就是一个事务的两次查询中数据笔数不一致。考虑下面的情况:
- P 去 insert 一个 id,但尚未提交。
- Q 去 select 这个 id,发现没有。
- Q 去 insert 这个 id,发现主键冲突,但是还是 select 不到,仿佛出现幻觉。
幻读会引发 Write Skew,并且会更加棘手。因为没办法通过显式锁定来解决这个问题:要锁的东西都不存在,该怎么加锁?
避免幻读,意味着我们要避免下面的情况:
r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1r1[P] ... w2[y in P] ... ((c1 or a1) and (c2 or a2) any order)
根据 DDIA,解决幻读有下面几点:
- 物化冲突
刚才提到了“我们要锁的东西都不存在,该怎么加锁?”这个问题,我们可以把这个不存在的东西物化出来。通过SELECT FOR UPDATE解决RR级别下的幻读问题的手段,就是物化冲突。如果 SELECT 下来,真的有东西,会加行锁;否则会加间隙锁。 - Next key lock
InnoDB 可以通过间隙锁 Next key lock 解决了幻读的问题。这实际上实现了串行化级别的效果,而且保留了比较好的并发性能。
当然,对于当前读我们可以加间隙锁,对于快照读,则可以借助 MVCC。
【Q】间隙锁可以理解为一种物化冲突的手段么? - 谓词锁
- 实现 S 隔离等级
其实通过实现谓词锁,或者 Next key lock 等也能实现 S 隔离等级。当然也有诸如 2PL 直接加锁的办法。
事务隔离性介绍
这里根据一些别的论文,而不是 DDIA 去介绍事务隔离性。但其实说的是一个道理。
Read uncommitted(RU)
RU 保证了不会脏写。
事务 A 在访问数据时,如果另一个事务在并发修改了该数据且未提交,在 Read Uncommitted 隔离级别下可能产生脏读。
Read committed(RC)
相比于 RU,RC 提供了两个保证:
- 不会脏读
从数据库读的时候,不会看到没提交的数据。
换句话说,RC 隔离级别下,一个事务开始到提交之前,做出的修改对其他事务是不可见的。 - 不会脏写
写入数据库的时候,只会覆盖已写入的数据。
这个其实 RU 也提供了。
事务 A 在访问数据时,如果另一个事务在并发修改了该数据且已提交,在 Read committed 隔离级别下可能产生不可重复读,或者称为读偏差(Read Skew)。
如何实现?
- 如何预防脏写?
很容易想到通过行锁。当要修改某个对象的时候,需要获得其所在行的行锁,并持有到事务提交或者中止。 - 如何预防脏读?
偷懒的办法是也用同一个行锁。这样同一个对象只会同时被一个事务访问。可是这个方案性能太不好啦!
这里可以直接杀鸡用牛刀,用 MVCC。例如对于写入的每个对象,数据库会记住旧版本的值,即上一次被提交的值。同时,数据库也会维护当前事务设置的新值。这也就是 DDIA 说的 “the committed version and the overwritten-but-not-yet-committed version”。
Repeatable Read(RR)
Repeatable Read 隔离等级如果是基于锁实现,那么事务 A 在访问数据时会加 S 锁。所以事务开始后其他事务就不能对该数据进行修改了,因此杜绝了不可重复读。
Snapshot Isolation(SI)
A Critique of ANSI SQL Isolation Levels 这篇文章指出了 ANSI SQL-92 给出的四种隔离级别存在的问题,并提出了 Snapshot Isolation。简而言之,它具有下面的特性:
- Each transaction reads reads data from a snapshot of the (committed) data as of the time the transaction started
也就是所谓的 Start-Timestamp。 - The transaction’s writes (updates, inserts, and deletes) will also be reflected in this snapshot
也就是事务自己造成的修改,会反映到这个 Snapshot 中。 - Updates by other transactions active after the transaction Start-Timestamp are invisible to the transaction
也就是在 Start-Timestamp 之后的记录,对这个 Snapshot 不可见 - When the transaction T1 is ready to commit, it gets a Commit-Timestamp, which is larger than any existing Start-Timestamp or Commit-Timestamp
提交时,需要用一个比已知所有的 CT 和 ST 都大的 CT 提交。
这个实现方式就是老几样:全局自增的 TSO、TrueTime、逻辑时钟(Lamport Clock 或者 Vector Clock,不过是否足够?)、全序广播相关的东西。 - The transaction successfully commits only if no other transaction T2 with a Commit-Timestamp in T1’s execution interval [StartTimestamp, Commit-Timestamp] wrote data that T1 also wrote. Otherwise, T1 will abort.
也就是说提交的时候,还是要冲突检测。也就是说如果发现有并发事务在写同一个记录,那么至少要abort一个事务,否则会导致Lose Update。这里 abort 的方式主要有 FWW、LWW、FCW、LCW。

这里补充几点我的理解:
- 如果一个事务在执行过程中,那么它的 CT 会被设置为多少呢?
我想应该是 inf,从 Percolator 的实现也是 inf,代表事务可能在无限远的时候才能提交。当然这未必有意义。
但在实现时,我们更可能的是需要一个保证,也就是这个事务不会在某个 tso 之前提交。 - SI 和“可串行”并不等价,因为它存在 Write skew 的问题。
Write skew 指的是两个并行事务都基于自己读到的数据去覆盖另一部分数据,这个问题违反了可串行化。 - 什么是冲突事务呢?
如果有其他事务在 [ST,CT] 之间也写了我的 WriteSet,那么这就是冲突事务了。如 Percolator 论文中 Figure3 所示。事务 2 看不见事务 1 的写,这是因为事务 2 的 ST 在事务 1 的 CT 之前。对应地,事务 3 能够看到事务 1 和 2 的修改。此时称事务 1 和事务 2 是并发事务。
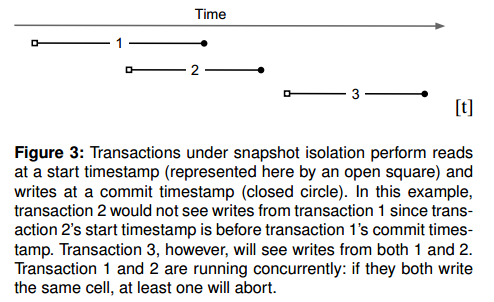
- Snapshot Isolation 的冲突检测
我理解这里是检查 WW 冲突的。但这里不检查 RW 冲突,我理解就可能导致 Write Skew 了。
回想上文讲述的P和Q分别运行x=y和y=x的例子。在这个例子中,Snapshot Isolation 并没有管读和写之间的问题。 - 是否可以前置冲突判断到提交前?
感觉这个有点类似于悲观锁? - RR 和 SI 的区别和联系
在 1975 年定义 SQL 的隔离级别的时候,尚未发明 SI 这个级别。
Snapshot Isolation具有下面的特性:
- 每一个数据有多个版本(MVCC)
这相比 RC 是一个变化,因为 RC 只会维护两个版本,即上一次被提交的值,以及这次的性质。
这是因为 MVCC 下,数据库需要维护某个对象的几个不同的提交版本,因此此时数据库中的并发事务可能看到数据库在不同时间点的状态。这也就是所谓的 MVCC 机制。
容易看出,MVCC 能够退化地实现 RC 隔离性。在 MVCC 章节中讨论基于 MVCC 对 RC 和 RR 的实现:即对 RC,每个查询用独立的快照;对 RR,整个事务用一个快照。 - 第一个得到行锁的事务可以进行,后面的写事务要么 abort,要么 block。
- 降低了的隔离级别,带来了更好的读性能。想想S的实现方式,就会发现这是很容易理解的。无论是真的串行(没有任何并行),还是2PL加锁(读和写都要加锁),都会导致读和写的竞争。
- 不会存在 Repeatable Read 中的幻读问题了,显然如果始终读取某个历史版本的状态,那么每次读都是一样的。
- 可能存在写偏斜(write skew)问题,从而不能满足 SERIALIZABLE 级别。
Snapshot Isolation 相对于 SERIALIZABLE 的隔离级别要低一些,诸如 Oracle 宣称提供的 SERIALIZABLE 实际上也是 Snapshot Isolation。
如何解决 Write Skew 问题?
- 可以通过 select for update 这样加锁的方式解决 write skew 问题
为什么有效?可以思考为什么 Repeatable Read 不会有 Write Skew 问题呢?根据这篇文章,RR 会在读取行的时候加读锁。 - 从 DDIA 上来看,Serial Snapshot Isolation(SSI) 可以避免 Write Skew。原因是它通过在提交时检测自己的 Write Set 是否会破坏并发事务的 Read Set,从而检测了 RW 冲突。
基本思想是冲突检测发生在事务运行阶段,而不是事务提交阶段。但是 Serial Snapshot Isolation 还是没能解决全序问题。 - write snapshot isolation
保证一个事务读的数据(也就是最近一个版本)的提交时间要早于事务的开始时间。即下面的两个事务不能同时提交成功:- 读写在空间上的重叠
事务 A 的写和事务 B 读属于同一行 - 读写在时间上的重叠
例如下面的顺序1
start(A) < commit(j) < commit(i)
- 读写在空间上的重叠
MVCC和SI的区别和联系
MVCC 和锁都是 SI 的实现手段,当然,也可以有一些方案完全无锁地实现 SI。
- MVCC
这篇文章中说,事务 T1 的快照记录是在生成快照时的活跃事务集合。这个集合的时间区间是 [min, max],其中所有比 min 小的事务都被提交了,所有比 max 大的事务都没有启动。如果落在这个区间内,还需要去真正比较是否在这个集合中。详见对 MVCC 的介绍。 - Percolator
保证能够读到R.start_ts > W.commit_ts。也就是说,当且仅当任意的事务 W 的 commit_ts 小于 R 的 start_ts,它能被事务 R 读到。
【Q】这个是不是和 SI 不太一样?SI 貌似是 CT2 和 [ST1,CT1] 比较的。这里注意,和 [ST1,CT1] 比较的目的是检测冲突。 - 锁
也就是直接禁止掉冲突事务。
Serializable(S)
等同于在每个读的数据行上加S锁,从而解决了幻读的问题。但这种方法具有很差的并发性,会导致大量超时和锁竞争。
【Q】就我理解而言,RU/RC/RR这三个事务等级都是对于一个记录R而言的,但是S隔离等级涉及多个记录R。我们可以类比记录到变量?
S的实现通常有下面几种方案:
- literally 去串行执行
也就是在单线程上一次只执行一个事务,理由是:- RAM 便宜了,现在可以完整存储活跃事务集
- OLTP 事物通常较短,并且只涉及少量读写
例如 VoltDB/Redis 等数据库中实现了这种方案。
- 2PL
这是一个非常 common 的选择。在专门的章节进行讨论。 - 一些乐观并发技术,例如上面提到的 SSI
MySQL 可以通过 SET TRANSACTION ISOLATION LEVEL 设置隔离级别。
Demo
考虑下面的代码Case1
1 | Ta Tb |
对于:
- RU、RC
读到的是20 - RR、S
读到的是10
再考虑下面的代码 Case2
1 | Ta Tb |
对于:
- RU
读到的是20 - RC、RR、S
读到的是10
并发事务控制
为了保证并发执行的事务在某一隔离级别上的隔离性,引入并发事务控制。
并发控制的主要思想可以根据乐观程度进行分类:
- 基于锁
这个方法是最悲观的,也就是在访问资源之前,需要加锁。如果获取不到锁,就阻塞事务。 - 基于时间戳
在每个事务开始时,获得时间戳,并期望事务按照时间戳的顺序执行。如果发现冲突,可以选择阻塞或者回滚。 - 基于有效性确认
在事务提交时,再进行验证。如果发生冲突,只能回滚。
当然,这种可能产生活锁,比如两个事务交替回滚。一个解决方案是在反复几次后,尝试加锁。
容易发现,越乐观的策略下,对冲突的检查就越迟。从最悲观的访问资源之前加锁,到最乐观的 Commit 前验证,并发的能力是加强的,但是失败回滚的可能性也就越来越大。虽然加锁的方案看似浪费资源,但因为回滚的开销比加锁大,所以当冲突较多时,基于锁的方案反而能有更好的效率(即每个事务被推迟的时间更少)。此外,在回滚不可避免时,基于时间戳的方法能更早检查到。
需要注意的是,三种策略都有单版本和多版本的实现。对于 MVCC,因为一次对数据库的修改都会生成一个新的版本,所成功把问题转化到了如何选取版本和管理版本上,在处理隔离性上会更加的灵活。
记号
r1(A) 表示事务 1 读取元素 A。w2(B) 表示事务 2 写元素 B。
其中事务 1 可以被写为 T1,事务 2 可以被写为 T2。
调度
串行调度
如果一个调度的动作组成首先是事务 A 的所有动作,然后是事务 B 的所有动作,那个这个调度就是个串行调度。
容易发现,执行事务 A -> 事务 B,和执行事务 B -> 事务 A 的结果是不同的。
可串行性
可串行性要求事务并发执行的效果和事务单独执行的效果是一样的。比如对于非串行事务 S,如果存在一个串行事务 S',使得对于每个数据库初态,调度 S 和调度 S' 相同,那么 S 就是可串行化的。
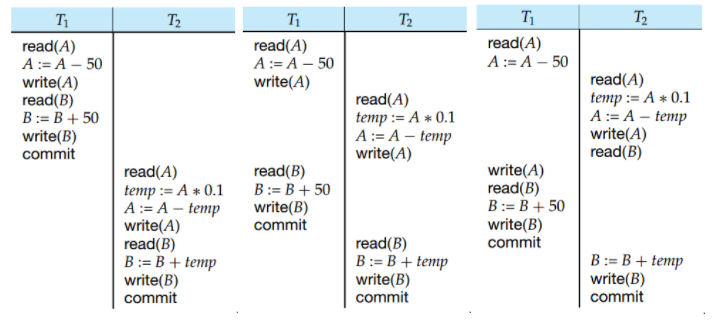
关于这一点,我们可以类比到CPU并行编程里面的内存模型。如下图所示:
- 左边的是串行调度,由定义可知
- 右边的是不是串行调度,也不是可串行调度
因为右边的结果和先 T1 再 T2 (左图)不一样,也和先 T2 再 T1 不一样 - 中间的图不是串行调度,但是可串行调度
虽然 T1 和 T2 是彼此交织的,但是它的结果和左边的图是一样的,所以是可串行调度。
冲突操作
在事务序列中的两个连续操作,如果交换他们的顺序,则涉及事务中至少有一个的行为会改变,那么这两个操作是冲突的。
可以进行如下讨论:
r1(X)和r2(Y)是不冲突的,即使X=Y
很容易理解,读读事务不会冲突r1(X)和w2(Y)是不冲突的,其中 X 不等于 Y
也很容易,读和写不是作用在一个对象上。
同理w1(X)和r2(Y)也不冲突;w1(X)和w2(Y)也不冲突。- 【读写冲突】
r1(X)和w2(Y),其中X=Y
特别的,即使是同一事务,r1(X)和w1(Y)也冲突。 - 【写写冲突】
w1(X)和w2(Y),其中X=Y
总结,两个操作的冲突发生在:
- 操作同一元素
- 其中一个是写
冲突可串行性(Conflict Serializability)
一个调度 S 在保证冲突操作的次序不变的前提下,通过交换非冲突操作的次序得到另一个调度 S’。此时,如果 S’ 是可串行的,就说 S 是一个冲突可串行化的调度。
考虑这一组图。图1就是一个冲突可串行化的调度。交换 T1 的 read(B) 和 T2 的 write(A) 可以得到如图2所示的调度。进一步,如果交换 T1 的 read(B)->write(B) 和 T2 的 read(A)->write(A),就可以得到如图3的调度。
但是图4就不是一个可串行化调度,因为read(Q)和两个write(Q)都是冲突操作。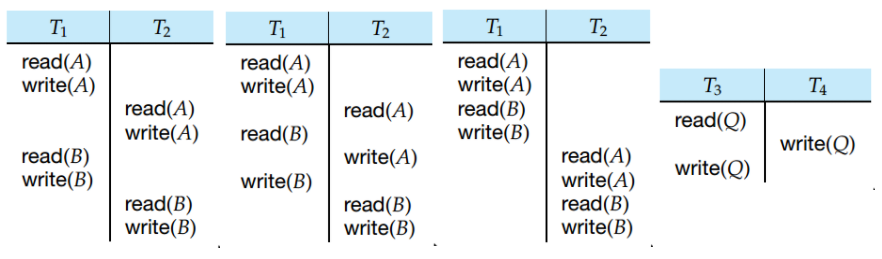
下图展示了通过交换相邻操作(下换线)将冲突可串行化调度转为串行调度的过程。![]()
冲突可串行化是一个更强的条件
冲突可串行化是一个比较强的条件。一个可串行化调度未必是冲突可串行化的,原因是可串行化调度可能交换冲突操作。例如事务 w1(A) 作用是 A+2,事务 w2(A) 的作用是 A+3。那么两个事务还是可串行化的。
考虑下面的例子,S1 是串行的,S2 通过交换 w2(Y) w2(X) 和 w1(X) 可以得到 S1。明显,冲突操作之间发生了交换,这不是冲突可串行化的。但 S1 却是 S2 的串行调度。这是因为两种调度最终都使得 X 的值为 w3(X) 而 Y 的值为 w2(Y)。
1 | S1: w1(Y) w1(X) w2(Y) w2(X) w3(X) |
优先图
可以通过构造优先图,并判断其中是否有环来判断事务是否是冲突可串行化的。构造方式,对于 T1 中的 A1,和 T2 中的 A2,如果满足:
- 在 S 中 A1 在 A2 前;
- A1 和 A2 涉及同一数据库元素
- A1 和 A2 至少有一个是写操作
那么就添加一条从1到2的有向弧,称为 A1 优先于 A2。
优先图的原理是,如果 A1 在 A2 前,而我们要将 T1 和 T2 串行化,根据定义,那么 T1 肯定要整体在 T2 前。
基于锁的并发控制
记:
l1(X)表示事务1请求给 X 上锁u1(X)表示事务1释放 X 的锁
需要保证:
- 事务一致性
只要有事务r1(X)和w1(X),则前面有l1(X),后面有u1(X)。实际保证访问对象就会上锁。 - 事务合法性
只要调度动作中有l1(X)和l2(X),则中间必然有u1(X)。实际上保证不会重复加锁。
下面的调度是合法的
2PL
2PL 用户实现 InnoDB 和 SQL Server 中的 S 级别,以及 DB2 中的 RR 级别。其思路是通过为每个对象加锁来解决冲突。这些锁可以是共享的,也可以是排他的,具体来说:
- 如果需要读取,那么可以使用共享锁
- 如果需要写入,必须使用排它锁
- 如果先读后写,需要将共享锁升级为排它锁,升级过程如同重新获得排它锁
- 获得锁之后,必须持有锁到事务提交或者中止
这应该是 S2PL 和 SS2PL 的规定。
其中做最重要的过程是,2PL 将加解锁过程分为两个阶段,在第一阶段只能加锁或者操作数据,不能解锁;在第二阶段只能解锁或者操作数据,不能加锁。
我们认为在解开第一个锁时,事务成功。【Q】这是在《数据库系统实现》里面的措辞,但在解锁之后,还是可以操作数据的啊。这些数据还没操作,为什么这个事务就算成功了?其实这个涉及级联回滚的细节,我们还真有 S2PL 和 SS2PL 来要求在 Commit 之后再释放锁。
数据库实现了死锁检测和死锁超时机制。以 InnoDB 为例,如果启动死锁检测(innodb_lock_wait_timeout),那么会在死锁发生时会选择将持有最少行级 X 锁的事务进行回滚。当然也可以选择等待(innodb_lock_wait_timeout)超时。
2PL可串行性的证明
假设在 2PL 条件下,Ti 在 S 中有第一个解锁动作 ui(x),则可以断言我们能将 Ti 的动作不经过任何有冲突的读和写移动到开始。
我们不妨假设 Ti 的某个动作 wi(Y) 前有 Tj 的动作 wj(Y)。那么根据事务一致性原则,在调度 S 中,uj(Y) 和 li(Y) 必然出现在下面的序列中。
1 | wj(Y) uj(Y) li(Y) wi(Y) |
下面,我们将“第一个解锁动作 ui(x) ”加入到序列S中,它至少处于如下位置(可能还会更靠左)。仔细查看下面式子,这违反了 2PL 的条件,因为 T 在上锁 Y 之前解锁了 X。
1 | wj(Y) ui(X) uj(Y) li(Y) wi(Y) |
死锁
2PL不能避免死锁
2PL不能避免死锁,如下所示。两个事务按照 2PL 加锁,假定第一个事务1请求到了4,第二个事务请求到了3,那么1和2就会陷入死锁。那就必须干掉其中一个事务。
1 | START TRANSACTION; |
2PL 不能避免死锁。既然如此,为什么还需要引入 2PL 呢?
2PL 这里的顺序并不是锁的顺序,而是所有的加锁工作必须在解锁工作完成前完成,显然这不能避免死锁
为了解决死锁问题,一个方案就是原子地获得所有的锁,这实际上破坏了占有且申请的条件。但这种办法对数据库来说很困难,因为它很难知道用户具体要那些资源,并且这样一次性锁协议牺牲了并发性。
【Q】我们知道指定加锁顺序,例如先获取第一个锁,然后才能获取第二个锁,可以避免死锁;或者遍历链表的时候,始终沿着同一个方向遍历等。我们能设计出这样的加锁协议,从而避免死锁?2PL 的目的是为了保证可串行性,进而是为了保证隔离性。
如果不满足 2PL,那么可能破坏隔离性。考虑下面的 Case1
2
3
4
5
6
7
8
9
10Ta Tb
xl(A)
w(A)
u(A)
xl(A)
w(A)
u(A)
sl(A)
r(A)
u(A)容易看出,Ta 先加写锁进行了写入,然后释放锁。Tb 再加写锁进行了另一次写入。后面 Ta 重新加读锁进行了读取,此时 Ta 读到的不是自己刚写入的。事务的隔离性会被破坏。
通过等待图检测死锁
通过时间戳预防死锁
引入一个新的时间戳来解决死锁问题。这个时间戳不同于“基于时间戳的并发控制”中介绍的时间戳,例如当事务回滚后,并发控制的时间戳会重置为一个更晚的,但死锁检测的时间戳不会重置。
当事务 T 发现自己需要等待事务 U 的锁时,将会比较时间戳,并选择 Wait-Die 和 Wound-Wait 两种方案之一来执行
- Wait-Die
如果 T 比 U 老(时间戳小),则 T 等待 U。也就是老等新。
否则,T 回滚。也就是新自杀。 - Wound-Wait
如果 T 比 U 老,它将主动“伤害” U,使 U 回滚,并放弃所有 T 需要的锁。也就是新自杀。
否则,T 等待 U。也就是新等老。
共同点:
- 总是牺牲较新的事务,这里牺牲的意思就是回滚
这是因为老事务往往会持有较多的锁,并且作了不少对数据库的修改,回滚老事务的成本比较大。 - 这个策略是公平的
当事务重新开始的时候,应当保留自己的时间戳。
最终,被牺牲的事务会变得足够老。 - 这两个方案有一定的“误杀率”,也就是会 abort 掉一些实际上不会造成死锁的事务
不同点:
- Wait-Die策略在新事务请求被老事务持有的 lock 时将新事务杀死
可以发现,Wait-Die 是非抢占的。较老的事务需要新事务。 - Wound-Wait策略在老事务请求被新事务持有的 lock 时把新事务杀死
比较一下两者的性能:
- Wait-Die会导致较多的回滚,但是这些回滚的事务只会进行很少的修改
这是因为新事务在自杀之后被重启,如果此时老事务仍然持有锁,则新事务依然需要回滚。 - Wound-Wait会回滚较少的事务,但这些回滚事务可能已经进行了比较多的修改了
这是因为新事务在被老事务杀死之后,重新起来会进入“新等老”。
级联回滚
需要注意的是,即使遵守2PL,还可能会出现问题。考虑下面的Case
1 | Ta Tb |
如果在获得B的锁后,Ta回滚,那么Tb也要回滚,否则Tb就RU了。这称为级联回滚。
如果一个调度中的每个事务在它读取的所有事务提交之后再提交,那么这个调度是一个可恢复调度,也就是我们可以通过undo/redo日志来恢复事务。并且事务日志到达磁盘的顺序和它们被写入的顺序是一致的。例如下面的调度S1,如果对应日志在磁盘上的实际写入顺序是S1’,并且在c2之后磁盘立即断电,那么c2处于提交状态,而c1不是。
1 | S1: w1(A); w1(B; w2(A); r2(B); c1; c2 |
可恢复调度还是可能导致级联回滚,例如上面的调度中,T2读取了T1的写入,因此T2需要在T1之后提交。可以发现,级联回滚的原因是事务执行过程中脏读。所以我们不仅要T2的Commit在T1的Commit之后,还要T2的所有Read都在T1的Commit之后。因此我们有定义:如果调度中的事务只读取已提交事务写入的数据,则称这个事务为避免级联回滚调度(ACR)事务。易知每个ACR事务都是可恢复事务。
基于锁避免级联回滚
可以通过S2PL和SS2PL解决类似问题,它们分别要求写锁和读写锁在事务Commit后再释放。例如著名的Percolator,它就是S2PL,因为在Commit时才会清除lock列并设置write列。
基于时间戳不会产生级联回滚
在基于时间戳的方法中引入了提交位C(X),从而禁止使用了脏数据的事务提交,因此这种模式下不会产生级联回滚。
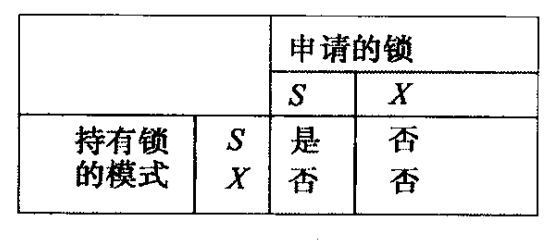
其他的锁模式和相容矩阵
- 共享锁S
- 排它锁X
- 更新锁U
更新锁uli(X)能申请X的读锁,但是在稍后,能够升级自己为写锁。 - 增量锁I
有些写操作是可以交换的,例如INC 3和INC 2。但这些操作和读和其他的写是冲突的。
相容矩阵表示在事务持有某些类型锁时,其他事务是否可以获得某些类型的锁。
意向锁
数据库里面至少有表和行两个层级,考虑对某张表里面的一万行加锁,我们有锁表和分别锁一万行两个选择:
- 表锁
会降低并发度。 - 行锁
对内存的消耗比较大,同时大量时间会消耗在检查锁。
考虑一个数据表中有一些行正在被锁定,而现在试图加一个表级锁,这显然是要被阻塞的。但需要在遍历数据表的每一行才知道表中有行被锁定这个事实。
意向锁的产生就是为了解决这个问题。意向锁要求在锁定行时对数据表也维护一个状态,表示当前数据表中有些行时被锁定的。如果对一个下层节点加锁,那么要先对上层节点加意向锁。比如你意向是获得表锁,那么请原地阻塞,别往下找了,现在是不可能的。这样在试图加表锁的时候,就不要逐一遍历检查是不是有行被锁住了。
下图展示了意向锁的相容矩阵。可以看出,IS和IX锁彼此是相容的:如果我想读取某表下面的元素,我也没理由直接不让其他事务写这个表下面的元素。就算它们真的冲突,那也是到具体行的时候再判断。
意向锁的组模式
可以发现,有一些锁是强于另一些锁的,例如X强于U、U强于S。但我们发现,IX和S相互不优于对方。事实上,同一个事务可以先后以S和IX锁住一个对象,比如它想要读表,然后写表中的某些行。既然S和IX是“平行”的,我们就有必要把上下层节点组合起来看了。这样能组合成四种锁的类型即SIS、SIX、XIS、XIX。介绍如下:
- 意向共享锁IS
如果我们想对一行加S锁,则先要对表加IS锁,表示我们对表中的某一行有加共享锁的意向。 - 意向排它锁IX
同理。如果我们发现一张表加了IX锁,说明里面有一或者若干行被X锁保护。 - 共享意向排他锁SIX
表明内部至少一个对象被X-Lock保护,并且自身被S-Lock保护。例如某个操作要全表扫描,并更改表中几行,可以给表加SIX。
除了SIX之外,其他的一些锁的形式并不常见,原因是其他的锁并没有提高强度,实际上可以退化为一个表级锁或者行级锁。
以SIS为例,我们要读取整个表,对表加S锁,然后要读取其中一行,对表加IS锁,实际上可以简化为一个对表加S锁的操作。
幻读与意向锁
TODO
基于时间戳的并发控制
基于时间戳的并发事务控制,需要在事务开始时分配一个时间戳TS来决定事务的执行顺序,其中TS较小的事务优先执行。这里的TS可以是物理时钟,也可以是逻辑时钟,只要保证开始较晚的事务总是有一个更大的时间戳。
对于每一个元素X,记录:
- RT(X),为最新的读时间戳
- WT(X),为最新的写时间戳
- C(X),表示最新的写事务是否已经提交
这个虽然很奇怪,但是必要的。假定事务T读取了事务U的写入,但U中止了,我们需要通过C来避免脏读。
基本情况讨论
我们的判断是以当前事务的开启时间TS,和X的RT、WT、C比较。
虽然时间戳表明了事务的先后关系,但因为事务执行是一个过程,具体到事务中的单个读写动作就未必恰巧等于TS,这可能会导致下面两种情况:
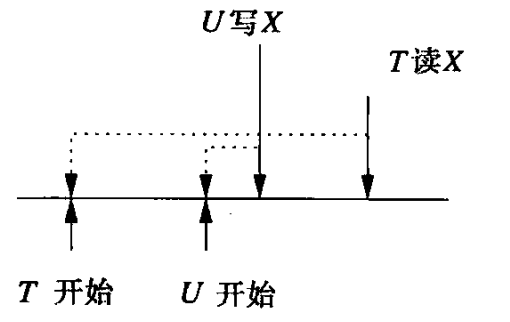
- late read
考虑读事务TS(T)正在读取数据库元素X,如果TS(T) < WT(X),说明目前X的值是在事务T之后(被某个更新的事务)写入的,事务T不应该读到该值。
如下图所示,U在T后开始,理论上T应该读不到U的写入。但现在T的读取被后延了,因此T别无选择,只能看到U写入之后的这个值。对于这种情况,如果没有MVCC做快照读,则只能中止T。
- late write
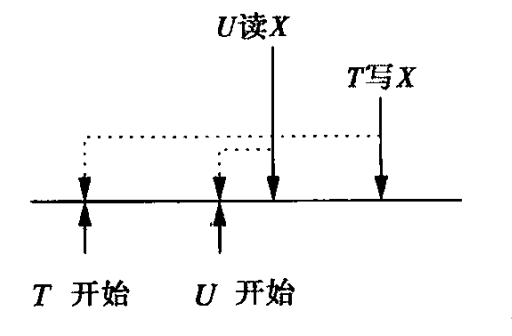
考虑写事务TS(T)正在写入数据库元素X,如果WT(X) < TS(T) < RT(X),其中WT(X)表示TS(T)之前的一个写入,RT(X)表示TS(T)之后的一个读取。那么RT(X)不应该读到WT(X)写入的值。
如下图所示,U在T之后开始,理论上U应该读到T的写入。但现在T的写入被后延了。因为在T准备写入时发现TS(T) < RT(X),说明自己的写入会被后面的事务U读取;并且WT(X) < TS(T),说明自己的写入是最新的。为了能让U读取到WT(X)的值,T同样需要被中止。
特别地,如果我们不中止事务,则可能会破坏RR约束。因为TS(T) < RT(X),说明U会读取,并且可能已经读取了一次X的值了,如果T修改了,然后U再次读取,就会读到一个不一样的值,从而破坏RR。
下面还有两种脏读的情况:
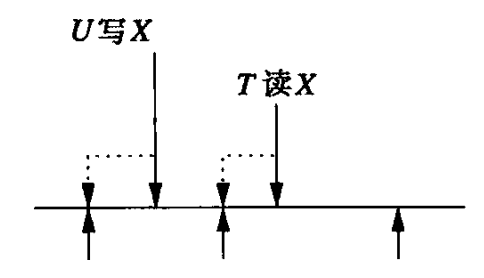
- 读到最终被中止事务写入的值
如下图所示,如果U最终没被中止,T应该读到U的写入,这是因为TS(T) > WT(X)。
- Thomas写法则(即忽略过时的写入)的例外情况
如下图所示,事务U在事务T之后开启,但是U却在T之前写了X。我感觉这其实也是一个late write的情况,因为TS(T) < WT(X),但却没有在之前讨论到。根据Thomas法则,此时T应该什么也不做。
显然不会有一个事务V想要读T的值,却读到了U的。因为如果V想要读T,就会满足TS(V) < WT(U),而这就是个late read,所以这样的V会被终止。
Thomas法则的一个问题是如果后续U被中止了,那么它的写入X应该被回滚,恢复到之前的值,也就是T的写入。但这是不可能的,因为T跳过写入就提交了。
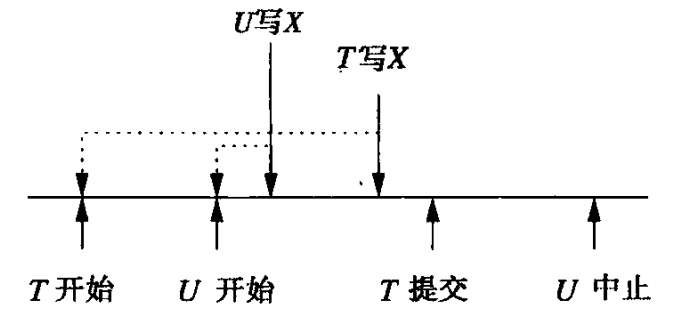
为了解决该问题,有一个思路是让T的写变成尝试性的,也就是设置C(X)位为false,并缓存一份之前的X和WT(X),方便在T中止时撤销。【Q】其实我不太懂这个方案为什么解决了问题,也许这里的T应该改为U,还是看下面的具体方案吧。
Timing Order(T/O)
下面基于Basic T/O构建一个基于时间戳的管理机制。令当前事务开启的时间戳是TS(T)。
考虑读:
- TS(T) < WT(X)
即late read情况,需要abort掉。稍后可以以一个更大的时间戳来重启这个事务。 - TS(T) >= WT(X)
记录X对事务TS是可见的,但还需要考虑C(X):- 如果C(X)为true,同意请求并更新RT(X) = max(TS(T), RT(X))。
- 如果C(X)为false,则需要等到C(X)变成true,或者写X的事务中止(【Q】好奇这个如何判断)。
考虑写:
- TS(T) < RT(X)
即late write的情况之一,需要abort掉。稍后可以以一个更大的时间戳来重启这个事务。 - 如果TS(T) >= RT(X),但TS(T) < WT(X)
即late write的情况之一,也可以abort掉。但考虑Thomas写法则,其实原则上是可以写的,此时需要检查C(X):- 为true,说明之前的事务(比如例子中的U)已经提交了,我们可以放心地跳过写。
- 为false,我们必须等待其变成true,或者事务中止。
- 否则(即TS(T) >= RT(X)且TS(T) >= WT(X))
可写,写入新值,更新WT(X) = TS(T),更新C(X)为false。
考虑事务提交:
- 将 C(X) 改为 true
- 让所有pending的事务继续执行
MVTO
其实 MVTO 的思路反而更显然:
- 当一个合法的写 wT(X) 发生时,创建一个新的版本的 X,令 Xt,其中 t 为 TS(T)
注意,这里就不维护真实的写入时间了,而是认为写入原子地发生在事务开始的那一刻。 - 当读发生时 rT(X) 发生时,找到满足 t <= TS(T) 的最大 t 对应的 Xt 对应的值
- 判断不合法的写
考虑t=80的事务正在读取X,并且选择了t=50的版本。如果此时有个t=60的事务打算写入,则这个事务会被中止。因为如果它可以执行,那么它的写入应当被t=80读到,但并没有。 - 删除旧版本Xt
如果t小于所有活跃事务的TS,则可以删除这个版本。
基于有效性确认的并发控制
对于事务T,需要维护其写集合WS(T)和读集合RS(T)。分为三个阶段:
- 读
这个阶段会读入RS(T)中所有的元素,并将WS(T)写入到临时存储中。 - 有效性确认
- 写
我们在全局维护三个事务的集合:
- START
记录每个事务T的开始时间START(T)。 - VAL
记录每个事务T的开始时间START(T)和验证时间VAL(T)。
注意,每个成功的事务是在有效性确认的那一刻执行的。所以VAL(T)可以认为是执行时间。 - FIN
记录所有已经完成的事务。
如果对于任意的活跃事务U,START(U) > FIN(T),则事务T就可以从FIN中被GC掉。
和基于时间戳的并发控制一样,也需要检查一些问题:
- T读U的写,U已经经过VAL,但还没完成FIN阶段
如下图所示,因为U在T前面进行了VAL,所以理论上应该U先写X,T后读X。但可能在实际上T先读X,U后写X。所以,其实我们不能判断T究竟读到了什么。因此,我们需要在这种情况下回滚T。
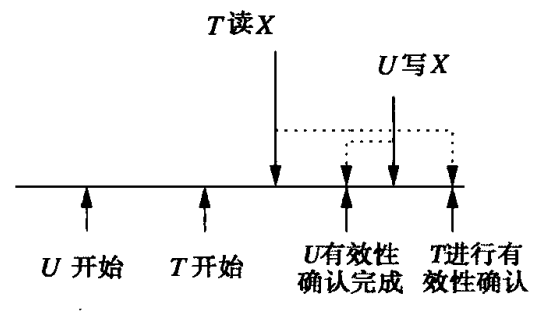
如果U在T的START之前完成VAL->FIN,那么就不会有冲突。所以,在对T进行有效性验证时,需要检查FIN(U) > START(T)且RS(T) ∩ WS(U) != ∅的所有的U。如果存在,则有效性验证不通过,需要回滚T。 - T和U同时写一个对象,U已经经过VAL,但在V经过VAL之前还没完成FIN阶段。
如下图所示,从VAL的时刻来看,应该U在T之前写,但实际上T在U之前写。
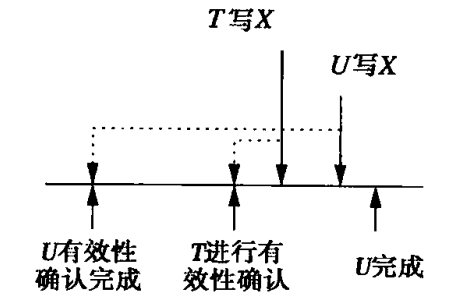
如果U在T的VAL之前完成VAL->FIN,那么就不会有冲突。所以,在对T进行有效性验证时,需要检查FIN(U) > VAL(T)且WS(T) ∩ WS(U) != ∅的所有的U。如果存在,则有效性验证不通过,需要回滚T。
OCC
乐观并发控制是一种用来解决写-写冲突的无锁并发控制,它类似 CAS。
MVCC
快照读与当前读
在 MySQL 中,不加锁的读是快照读,只会读取到事务开始前的数据和事务过程中插入的数据
1 | SELECT * FROM t WHERE id=1 |
加锁的读是当前读,表示读的是事务运行过程中的最新数据
1 | SELECT * FROM t WHERE id=1 LOCK IN SHARE MODE; |
MVCC实现(InnoDB)
主要讨论 RC 和 RR 下的 MVCC。至少对于 InnoDB 而言,RU 和 S 并不依赖 MVCC。这是因为:
- RU 始终读取最新的记录,并不需要考虑版本
- S 默认要加锁,并不需要考虑并发
记录结构
在使用 MVCC 时,InnoDB 需要对每一条记录多存储一些字段:
trx_id
标记最近一次修改这个记录的事务的 ID。db_roll_ptr
回滚指针,指向 Undo。
因此,一次UPDATE事务的流程可以如下所示:
- 事务 begin
- 对记录申请X锁
- 写 REDO
- 写 UNDO
- 实际修改 Record
除了修改值之外,还需要修改trx_id指向当前事务,修改db_roll_ptr指向 UNDO。
观察一致性快照的可见性规则
当事务在读取时,通过它的事务ID,决定哪些对象对它来说是可见的,哪些对象是不可见的。
基本原则是:
- 【原则1】在事务开始时的所有活跃事务的提交要被忽略。
活跃事务指的是尚未commit或者abort的事务。 - 【原则2】所有被abort的事务的写入要被忽略。
- 【原则3】所有在当前事务创建之后创建的事务的写入都需要被忽略。
- 【原则4】所有其他写入可见。
RC下的MVCC
相比于记录ST和CT,这里记录的是ST以及是否提交。
在RC下,每一个SELECT都会生成一个ReadView。在ReadView中维护一个列表m_ids,里面存放了所有当前活跃事务的ID,可以和每条记录里面的trx_id对应,其中trx_id能够代表事务开启的先后顺序,可以简单理解为时间戳。令其中最小值是low,最大值是up。
假设我们现在需要访问某一条记录,我们根据活跃事务集的范围[low,up]进行一次初筛,对于可能落在活跃事务集中的,再进行一次细筛。如下所示
- 被访问的
trx_id小于low
说明生成该版本的事务在ReadView创建前就提交了,所以可以被访问。 - 被访问的
trx_id大于up
对应了【原则3】
说明该事务在ReadView创建后才生成,所以不能被当前事务访问。需要通过Undo Log找到上一个版本,再判断一次可见性。
【Q】这个规则有点奇怪,例如对于上面的Case1而言,这里应该是返回新值的,这个规则是否导致新值不能被使用呢?答案是不会,因为每个SELECT都会生成一个ReadView。 - 如果
trx_id落在[low,up]之间
【细筛】
需要判断trx_id是不是在m_ids中。
如果在,说明在ReadView创建时,生成这个版本对应的事务还是活跃的。因此不能访问,需要回溯Undo Log。
否则,说明在创建时,这个事务已经提交了。【Q】那为啥trx_id还会落在low和up之间呢?我想可能是因为这个事务非常短,例如同时有123事务开启,然后2就结束了,但是1和3一直延续到ReadView创建时。
RR下的MVCC
在RR下,在第一次读的时候创建一个ReadView,在创建ReadView之后,即使有其他事务提交,也不会对ReadView的内容造成影响。
例如,事务Ta的ID是200,在没有提交时,事务Tb开始查询。假如事务Tb的ID是300,此时生成ReadView的m_ids为[200,300]。那么一直到这个事务结束前,m_ids都不变化了。假设现在Ta提交了,但由于它的ID在m_ids中,所以事务Tb还是只能回溯访问版本链中的记录,对应的值是10。
S下的MVCC
不需要MVCC,因为一定要加锁了。
Reference
- https://houbb.github.io/2018/09/01/sql-2pl
- https://draveness.me/database-concurrency-control/
讲解了并发事务控制 - http://www.mathcs.emory.edu/~cheung/Courses/554/Syllabus/8-recv+serial/deadlock-compare.html
讲解了wait-die和wound-wait - https://www.huaweicloud.com/articles/15e862d136110a0b026c911ace78caa7.html
MVCC等 - https://zhuanlan.zhihu.com/p/91208953
事务隔离级别,以及MVCC的实现和比较 - https://zhuanlan.zhihu.com/p/130242140
介绍了TO和OCC - https://csruiliu.github.io/blog/20180215-db-serialization/
介绍可串行性 - http://blog.kongfy.com/2019/03/serializable/
介绍另一种隔离级别的认知
介绍了各个主要数据库的隔离性 - http://www.nosqlnotes.com/technotes/mvcc-snapshot-isolation/
介绍Snapshot Isolation - https://pingcap.com/blog-cn/take-you-through-the-isolation-level-of-tidb-1/
tidb对事务隔离等级的论述 - DDIA
DDIA对事务隔离的论述,在事务章节中 - https://developer.aliyun.com/article/77965
对A Critique of ANSI SQL Isolation Levels这篇论文的翻译 - https://cloud.tencent.com/developer/news/330343
介绍了各个isolation 问题 - On Optimistic Methods for Concurrency Control
OCC的提出,基于时间戳的方法 - https://caroly.fun/archives/%E5%88%86%E5%B8%83%E5%BC%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E4%BA%94
分布式数据库 - 数据库系统实现(第二版)
- https://zhuanlan.zhihu.com/p/79034576
TiDB 事务 - http://www.nosqlnotes.com/technotes/mvcc-snapshot-isolation/

