随着请求量的增大,为了高可用和容错,常常采用维护多个冗余副本的办法来实现,因此需要维护这些副本之间的一致性。
随着数据量的增大,单个节点难以承载所有数据,分布式系统还会将数据进行分区,如何维护分区间事务是一个问题。
分布式集群搭建在网络上,而网络通信是复杂的,数据包的丢失、重复、乱序需要被妥善处理,此外节点宕机或者网络分区的情况也需要被考虑。CAP 理论认为一致性、可用性和分区容错不可能同时做到。
分布式系统中常出现以下的一些应用场景:分布式锁、负载均衡、发布订阅模型、选举、分布式队列。
本篇文章以 DDIA 以及作者的讲解视频为骨架,辅以业界的相关实现,来综述性探讨上述的一些问题。
分布式系统的相关性能要求
可用性和可靠性
可用性(availability)需要系统在任何给定的时刻都能够正确工作。可靠性(reliability)需要系统可以无故障地持续运行。这两者的区别是可靠性强调的是较少的崩溃次数,而可用性指的是较长的服务时长。例如,系统A可以运行一年,但每隔一个月会崩溃一次,并花费1s恢复;系统B无崩溃工作一年,但需要每年停机维护2小时。那么系统A的可用性会强一点,但系统B的可靠性会强一点。
而根据《InnoDB存储引擎卷1》 P274页的论述,可靠性强调系统本身的能力,而不考虑在遇到不确定的环境因素,例如地震海啸破坏硬盘等情况导致的问题。
高可用性HA与容错FT
根据DDIA,首先应当区分fault和failure,故障Fault通常定义为系统的一部分状态偏离其标准,而失效Failure则是系统作为一个整体停止向用户提供服务。能预料并应对故障的系统特性可称为容错(fault-tolerant)或韧性(resilient)。
单点(Single point of failure, SPOF)表示因为某个fault(比如网络或者节点的)导致的failure。而FT即Fault Tolerant,表示在一定fault规模下,系统还能够持续运行,而不failure。
从定义上来看,Fault tolerant的系统不允许服务中断(service interruption),但其开销较高;High availability的系统追求最小的服务中断。
衡量容错能力通常可以通过MTBF、MTTR、MTTF等指标,分别表示开始工作到第一个故障的时间的平均值,平均修复时间和平均失效时间。
Failure detector
Failure detector检查节点是否失效。
Perfect Failure detector会在当且仅当一个节点失效的时候标记它是失效的。
- 通常实现
发消息等待超时。对crash stop和crash recovery是有效的。
无法区分无响应、丢包和延迟消息。 - Eventuall perfect failure detector
安全性
安全性强调的是在故障的情况下系统能够正确操作而不造成灾难。
可维护性
可维护性描述发生故障的系统被恢复的难易程度。
分布式系统模型
网络行为假设
- Reliable
如果消息被发送,那么就会被收到。
但信息可能是被乱序收到的。
我们将在后面对广播和全序广播中继续讨论。 - Fair loss
消息可能丢失、重复、乱序。但如果不断重试,消息最终会被送达。 - Arbitrary(active adversary)
消息可能会被损坏。
节点行为假设
- Crash(Fail) stop
当节点 crash 后,就会永远停止运行。 - Crash(Fail) recovery
当节点 crash 后,可能在某个时刻恢复。 - Byzantine
同步假设
- 同步
消息延迟不会高于某个上限。 - 部分同步
在某些有限时间段中,系统是异步的。 - 异步
所有信息可以被任意地延迟,各个节点可以任意地停止工作。
分布式系统上的数据存储
分布式存储架构的演变主要源于三点需求:
- 减少延迟(latency)
例如扩大数据在地理上的分布范围。 - 提高可用性
为系统提供容错/高可用性 - 伸缩性(Scalability)
例如将请求负载均衡到各个机器上。或者例如读写分离。
扩展方案有两种思路:
- 水平扩展(horizontal scaling, scale out)
- 垂直扩展(vertical scaling, scale up)。
三种模式:
- 共享内存(shared-memory)
- 共享磁盘(shared-disk)
- 无共享(share-nothing)
复制(replicate)
复制(replicate),指通过网络连接的多台机器上保留相同数据的副本(replica)。复制架构包括 single leader、multi leader、leaderless。
主从复制和复制自动机复制
- Primary-backup system 或者称为主从复制系统
代表是 zab 协议。 - State machine replication 或者称为复制自动机系统
代表是 Raft 协议。
这里引用Vive La Différence: Paxos vs. Viewstamped Replication vs. Zab的观点。State machine replication 也称作 active replication,而 primary-backup system 也称作 passive replication。SMR 上每个节点维护一个确定状态机,彼此一致性协议来返回给 client。Primary-backup system 中,只有 primary 维护确定性状态机,然后通过一致性协议备份到 backup。
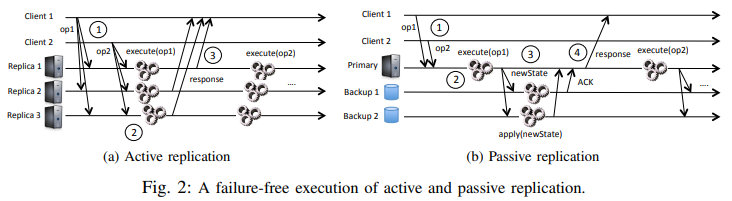
SMR 和 primary-backup 的区别还体现在,SMR 更讲究“过程”:
- 例如
x=1和x=2这两个操作,primary-backup 只需要复制一个最终的x=2即可,但是 SMR 需要两条日志表示过程。 - 因为 SMR 要在所有的机器上 apply 过程,所以不支持诸如随机、时间相关的操作。
复制哪些东西?
复制 SQL 语句
这种模式下,主库直接记录下每个写入请求如INSERT等,并转发给从库。这种方式存在一些弊端,例如SQL语句中可能存在随机函数或者时间函数导致每个库上的执行结果不一致,或者数据库中使用了AUTO INCR等语句时,对每个副本上语句的执行顺序也有要求。
复制 WAL
无论是为存储日志结构的 LSM 树还是覆写单个磁盘块的 B 树,其修改都涉及预写式日志 WAL。在这些情况下日志是包含所有写入的仅追加序列,因此通过相同的日志可以在另一个节点上构建相同的副本。
缺点是 WAL 的信息和数据库的底层存储紧密耦合,这使得更改底层存储格式变得困难。例如通常不可能在 Leader 和 Follower 上运行不同版本的数据库。
复制逻辑日志
Leader based Replication
Leader-based replication,又称为 active/passive 或者主从 master/slave 架构,由一个 Leader/Master/Primary 负责协调多个 Follower/Read replica/Slave/Secondary。
需要分清楚主备和主从的概念。主备的备,并不会去服务。主从的从,会提供读服务。主从架构是一个 HA 解决方案,主要体现在读写分离。
主从数据库可以互为热(hot)/温(warm)备份(standby):
- 冷备
这个备份节点平时不启用 - 温备
只 Follow 来自 Leader 的更新,但是不 Serve 客户端的请求 - 热备
可以 Serve 客户端的读请求,可能还能处理写请求。
Push 和 Pull
Pull 模式,一般发生在 Slave 长时间不和 Master 同步的场景下。例如 Slave 重启了,那么由它发起重新同步是最合适的。
Push 模式,一般发生在 Master 产生数据时。此时只能通过主动 propagate 的方式通知 Slave。
处理集群成员变更
增加新 Follower
- 获取主库的一致性快照
- 将快照复制到从库
- 从库连接主库,并拉取快照之后发生的所有数据库变更
- 从库现在已经 caught up 主库,可以进行正常的主从复制了
处理宕机
在主从架构下的从节点宕机的处理可以采取简单的 catch up recovery。
主节点宕机需要故障切换,即 Failover,包含三个主要步骤:
- 确认主库宕机
应当审慎地选取一个 Timeout 时间,因为 Leader 的超时可能是由于网络负载导致的,此时如果认为 Leader 宕机而开始选举会导致网络负载进一步恶化。 - 选择一个新的从库
需要在剩余的节点中决议出一个拥有旧 Leader 中最新数据副本的 Follower 以期最小化数据损失,一般通过共识协议解决。 - 重新配置系统
需要处理新 Leader 选出后老 Leader 重新连接的情况。一方面这可能导致脑裂(split brain),即新老 Leader 同时接受来自客户端的写请求,从而导致冲突。通常需要重新路由客户端的请求,确保老领导在分区或者重启后 Step down。
错误解决脑裂问题可能导致新老 Leader 都被关闭,从而导致集群无主的现象。
另一方面,在异步复制的环境下,新 Leader 可能没收到老 Leader 宕机前的写入操作,此时这部分的写入可能被丢弃掉,从而影响到持久性。
FailOver 可能出现的问题:
- 在异步复制情况下,新主可能没有老主宕机前最后的写入数据。特别地,当老主重新加入集群后,新主可能会收到冲突的写入,如果此时丢弃老主未复制的写入,就可能破坏持久性
- 如果数据库需要和其他外部存储协调,丢弃写入内容会很危险
- 脑裂,即有两个节点都认为自己是主
- 如何确定一个合理的超时时间
考虑到临时负载的峰值可能导致节点响应超时,或者网络拥塞可能导致数据报延迟,但这些都不是主节点宕机的情况。如果此时发生 FailOver,可能会加剧系统的压力。
同步复制和异步复制
日志复制需要确认么?在强一致场景下,是需要确认的。
事实上,有三种方式:
- 异步复制
Master 在执行完事务之后立即返回。容易发现,如果此时 Master 宕掉了,已提交的事务并不会传到 Slave 上,此时如果 promote 这个 Slave,则会丢失修改。
这是 MySQL 的默认复制方式。 - 全同步复制
所有的 Slave 都完成复制,才会返回给客户端。 - 半同步复制
保留至少一个节点使用同步复制的方式。
对 MySQL 而言,要求至少一个 Slave 收到,并且 Flush binlog 到 Relay log。开销至少是一个额外的 rtt。
异步复制在性能上是美好的,具有高吞吐量和低延迟,但是在一致性和持久性上会打折扣,每个节点上的数据可能是不一样的,并且主库已经向客户端确认的写入可能会丢失。异步复制的一个典型是 Redis 的哨兵机制。同步复制的情况下一旦一个从库失去响应,就会阻塞所有写入操作。在下图中,Follower1 是同步的,Follower2 是异步的。通常情况下的同步复制指的是半同步(semi-synchronous),即设置一个 Follower 为同步的,其余的为异步的。
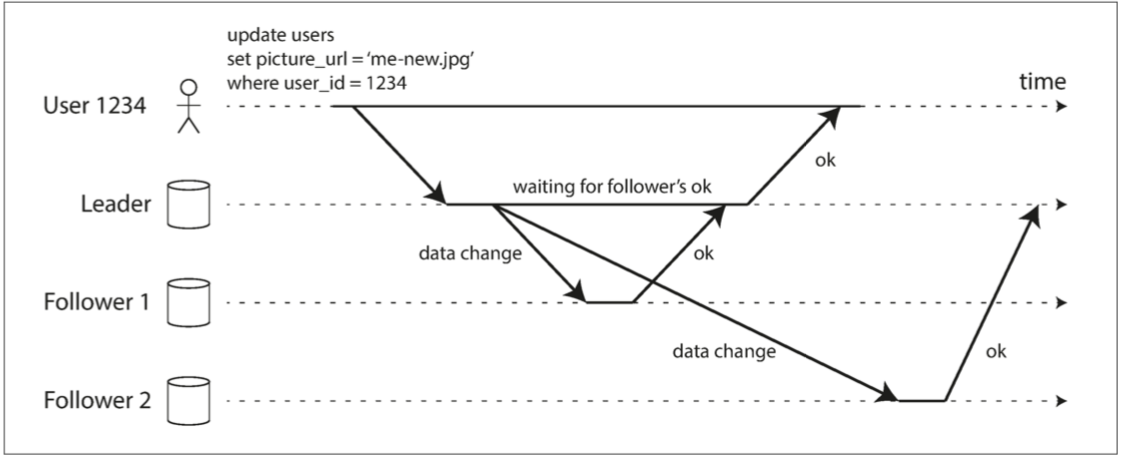
主从复制和最终一致性
日志复制的不同实现方式可能产生一致性问题。例如在读写分离的架构下,同步复制对可用性的损害是很大的,但如果采用异步复制的方式,在从库落后的情况下,同时对主库和从库的查询可能产生不同的结果,从而产生一致性问题。
主从复制的架构下,如果做简单的异步复制,是最终一致的(eventually consistency),也就是在副本之间实现同步间存在不一致窗口,称为复制延迟(replication lag)。复制延迟的持续时间是不确定的。
从 CAP 的观点来看,主从复制实际上是在最大可用(Max Availability)和最大保护(Max Protect)之间的一个 trade-off,其核心原因是网络分区和宕机是不可避免的:
- 如果允许主从节点在某个 Slave 宕机到恢复的时间段内继续服务,就必然要为不一致窗口付出代价。
- 如果不容许一致性受到损害,就必然要等到这个 Slave 在 FailOver 之后才能返回给客户端。
哪怕只有一个机器宕机,这段时间内的可用性也无法保证。
但这个是不符合常识的,比如说我想知道数学老师复制了什么作业,我首先找课代表问。如果课代表找不到了,或者给我一个错误的答案,难道就不能真正知道作业时什么了么?事实上我只要问足够多的人就行。例如如果每个人都是言行一致的话,那么过半数人就足够石锤了。这就对应到 Lamport 提出的基于复制自动机的分布式集群,它使用共识算法来维护一致性,能够承受不多于半数的节点失效。
关于一致性问题的详细论述,参考专题文章。
链式复制
链式复制的概念主要来自于Chain Replication for Supporting High Throughput and Availability这一篇论文。
链式复制总是从头写,从尾读。当尾节点写成功了,头节点才会返回 Committed。
但实际上,可以从任何节点开始读。此时可以引入 MVCC 这个解决读写冲突的神器了。当读取某个节点,发现存在多个版本的数据时,需要先去尾节点查询当前数据的最新版本。
每个节点收到下一个结点的 ACK 时,就可以删除旧版本的数据了。
相对于主从:
- 减少了 Master 的 replication 的负担
因为 Master 只要往后面一个节点复制了 - 可能不需要借助于分布式共识了
- 相对于主从要慢,因为 replication 不能是并行的
对此可以采用 pipeline 或者 Multicast 之类的配置。
Multi Leader Replication
单主复制存在缺点,比如所有的写入只能通过一个主库,如果主库挂了,就会丢失可用性。
多主复制,即 multi-leader configuration、master-master replication 或 active/active replication 中,每个主库同时是其他主库的从库。
多主复制的一个常见场景是多数据中心复制。因为数据中心通常跨地域分布,如果使用单主复制,必然所有的写入都会被路由到这个数据中心。跨数据中心会带来更高的网络延迟和更高的网络成本。并且也违背了多数据中心的初心,无论是为了容灾还是为了在地理上更接近用户。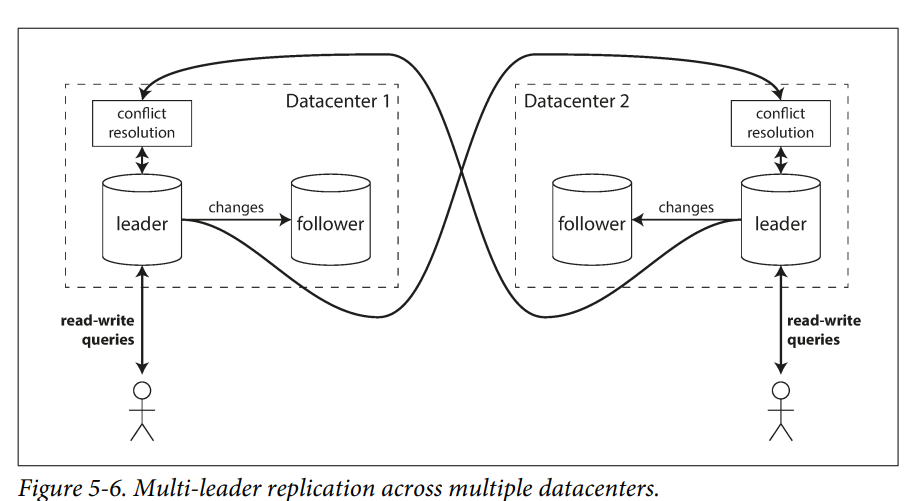
解决冲突
多主复制的一个问题是当两个主库同时对同一个记录进行更新时如何处理写入冲突。一个典型的冲突如 DDIA 的 5-7 所示,原值为 A,但两个用户 1 和 2 分别想把它改成 B 或者 C。因为各个数据中心之间是异步复制的,所以这两个请求都可以被提交到各自数据中心的主库中。但当这些主库之间进行异步复制时就会产生冲突。

如果试图将冲突检测提前到记录更新时,会导致各个主节点之间的同步开销,多主复制的优势不复存在,不如直接用单主方案。在多主复制中,用下面的方式解决冲突。
避免冲突
避免冲突的思路是:如果应用程序能保证特定记录的所有写入都通过同一个 Leader,那么冲突就不会发生。
但从一个数据中心将数据迁移到另一个数据中心的需求是存在的,而这会导致避免冲突是不可能的:
- 如果数据中心中发生故障,需要将其中的数据迁移到另一个数据中心中
- 因为用户的地理位置改变,所以想使用另一个数据中心
冲突合并
对于单主数据库而言,可以采用 LWW 策略,即如果同一个字段有多个更新,则最后一个写操作将确定该字段的最终值。
但对多主配置中,写入顺序没有定义,所以最终值应该是什么并不清楚。在图5-7中,在主库1中标题首先更新为 B 而后更新为 C。在主库2中,首先更新为 C,然后更新为 B。两个顺序都不是“更正确”的。
如果每个副本只是按照它看到写入的顺序写入,那么数据库最终将处于不一致的状态:最终值将是在主库1的 C 和主库2的 B。这是不可接受的,每个复制方案都必须确保数据在所有副本中最终都是相同的。因此,数据库必须以一种收敛(convergent)的方式解决冲突,这意味着所有副本必须在所有变更复制完成时收敛至一个相同的最终值。
实现冲突合并解决有多种途径:
- 给每个写入一个唯一的 ID
这个 ID 可以是时间戳、长的随机数、UUID、键和值的哈希。
挑选最高 ID 的写入作为胜利者,并丢弃其他写入。
如果使用时间戳,这种技术被称为最后写入胜利(LWW, last write wins)。
很容易造成数据丢失。 - 为每个副本分配一个唯一的 ID
ID 编号更高的写入具有更高的优先级。这种方法也意味着数据丢失。 - 以某种方式将这些值合并在一起
例如,按字母顺序排序,然后连接它们。以 图5-7 中的情况为例,合并的标题可能类似于B/C。 - 在保留所有信息的显式数据结构中记录冲突
并编写解决冲突的应用程序代码,或者提示应用程序去处理冲突。
对于最后一种情况,可以允许用户在写入或者读取这两个阶段来处理冲突。
自动冲突解决的相关研究
- Conflict-free replicated datatypes,CRDT
A Conflict-Free Replicated JSON Datatype
A Comprehensive Study of Convergent and Commutative Replicated Data Types
CRDTs: An UPDATE (or Maybe Just a PUT)
A Bluffers Guide to CRDTs in Riak - Mergeable persistent data structures
显式跟踪历史记录,类似于 Git 版本控制系统,并使用三向合并功能 - Operational transformation
Etherpad and EasySync Technical Manual
What’s Different About the New Google Docs: Making Collaboration Fast
Multi-Leader Replication Topologies
A problem with circular and star topologies is that if just one node fails, it can inter‐ rupt the flow of replication messages between other nodes, causing them to be unable to communicate until the node is fixed.
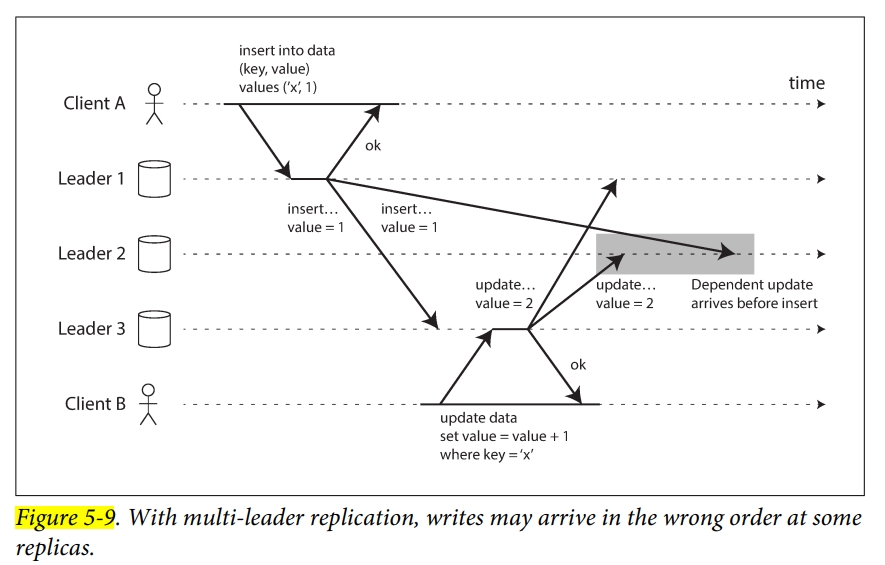
all-to-all 的方案中,因为拥塞的问题,网络中某些部分可能更慢。那么某些 replication message 就会被 overtaken。如下所示,insert 和 update 从两个不同的 Leader 1 和 Leader 3 写入,Leader 2 先收到了 update,而这个 update 依赖一个 insert,它随后才被复制过来。我们加一个普通的时间戳也解决不了这个问题,因为不能够信任本地时钟。
Leaderless Replication
在 single leader 或者 multi leader 复制中,一个 client 发送 write 请求到一个 node,也就是所谓的 leader。数据库系统负责复制到其他 replica。Leader 会决定 write 的 order,follower 会 apply 由 leader 决定的 order。
在 Leaderless 复制中,任何的 replica 都可以从 client 那里获得数据。主要是在 Dynamo、Riak、Cassandra、Voldemort 中使用。在一些实现中,client 会直接给 replica 发送 writes,在另一些实现中,会使用一个 coordinator node 来代表 client,但这样的 coordinator 并不会像 Leader 那样去定序。
Writing to the Database When a Node Is Down
在有 Leader 时,节点宕机后,会执行 failover。
而在 Leaderless 中,并不存在 failover。相应有下面的两种机制 Read repair 和 Anti entropy。
Read repair
需要显式加入一个 version tag,通过 version tag 来过滤掉陈旧的数据。如下图所示,user2345 从 replica 3 读到一个 version 为 6 的值(因为对应的机器可能宕机了,所以没收到更新的版本)。
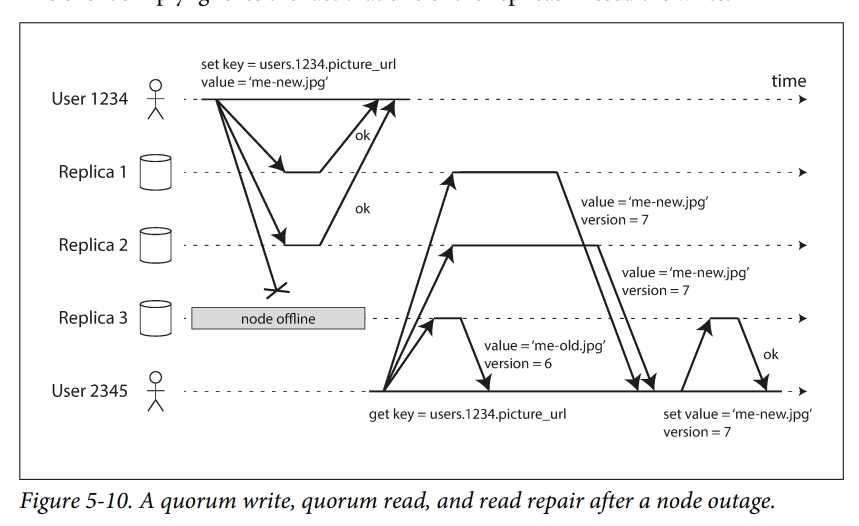
这里提一个问题,如果读了 3 个 node,其中 1 个返回较新的数据,另外 2 个返回较老的数据,那么是使用较新的,还是较老的数据呢?
- 如果回答较新的话,那么假如说较新的数据只被写入了一个 node,其他的 node 没有被写入,并且最终 client 放弃了写入,并且还没回滚,那么这就是后面 Limitations of Quorum Consistency 中提到的第 4 种情况了。
- 如果回答较旧的话,那么假如 5 个节点集群中有 3 新 2 旧,刚好读到 1 新 2 旧,那也是错的。
我理解要求写完 3 个节点之后,才能算写入成功。
Anti entropy
In addition, some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another. Unlike the replication log in leader-based replication, this anti-entropy process does not copy writes in any particular order, and there may be a significant delay before data is copied.
Quorums for reading and writing
这也就是所谓的 RWN 一致性。
这里需要注意 Leaderless 和 Leader-based 复制的区别。也就是读和写的 Quorum 是可以分开考虑的。
Limitations of Quorum Consistency
RWN 中 Quorum 的选择,并不一定是要满足至少 n / 2,而是要保证 w 和 r 至少有一个 node 是重叠的,而 n / 2 的方案肯定是能满足的。
如果令 r + w <= n,这样就不需要等待那么多节点回复了,但这样会由更大的不一致的可能。但如果令 r + w > n,仍然有一些情况会破坏线性一致,下面列出一些:
- Sloppy quorum
- 如果两个 write 是并发的,就无法确定谁先谁后
此时唯一安全的做法是在 Multi leader replication 中提到的 merge concurrent write 了。其实那里列出来的也不是什么特别好的办法了。
如果采用 last write wins 的办法,根据时间戳来选择,那么就要考虑 clock drift 的问题。
在有 Leader 的情况下,因为只有 Leader 能写入,所以顺序是确定的 - 如果 write 和 read 并发,那么这个 write 可能只会被某几个 replica 反映出来。此时并不知道 read 的结果是新的还是旧的
- 如果 write 在某些 replica 上成功,某些 replica 失败,并且没有达到 w。在那些成功的节点上,后续也没有 rollback。这样,后续的 read 无法确定是否要返回这个 write
- 如果一个 node 在写入了新值后宕机了,然后被从一个具有旧值的存档中恢复,那么可能 w 就不能达到了,破坏了线性一致性
这个我理解只是实现问题,必须要保证持久化之后,才能返回写入成功。 - 因为 timing 问题,即使使用了 Strict Quorum 也可能达不到 Linearizability
这个是在“【情况6】Strict Quorum 也可能达不到 Linearizability”描述的。通常可以被 Read repair 解决。
下面会对上面的一些问题进行讨论。
另外,Aurora 也引入了 r 和 w,但是它有更加严格的限制。
Monitoring staleness
For leader-based replication, the database typically exposes metrics for the replication lag, which you can feed into a monitoring system. This is possible because writes are applied to the leader and to followers in the same order, and each node has a position in the replication log (the number of writes it has applied locally). By subtracting a follower’s current position from the leader’s current position, you can measure the amount of replication lag.
【情况1】Sloppy quorums 和 Hinted Handoff
一些网络故障可以让 client 和很多节点断连。尽管这些节点实际存活,并且可以和其他节点连接。但可能达不到 w 或者 r quorum 了。当一些节点失联时,面临两个选择:
- 对于无法达成 w 或者 r quorum 的所有请求,返回错误
- accept writes anyway, and write them to some nodes that are reachable but aren’t among the n nodes on which the value usually lives
第二种解法就是 sloppy quorum。一旦网络故障恢复,这些临时用来接受 write 的节点,就会将写入重新转发给老节点,称为 hinted handoff。
但这样线性一致性就未必能得到保证,因为最新的值可能会被写到其他的某个节点上。换句话说,其实 sloppy quorum 就不是传统意义上的 quorum,它只是一个持久化的保证。在 hinted handoff 完成之前,读节点不能被保证 quorum 为 r 的读能够读到写入的数据。
Multi-datacenter operation
【情况2】Detecting Concurrent Writes
因为这一类型的数据库运行多个 Client 并发写入同一个 key,所以即使有 strict quorum,也会存在和 multi leader 类似的冲突问题。下图中列出三种情况:
- Node 1 receives the write from A, but never receives the write from B due to a transient outage.
- Node 2 first receives the write from A, then the write from B.
- Node 3 first receives the write from B, then the write from A.
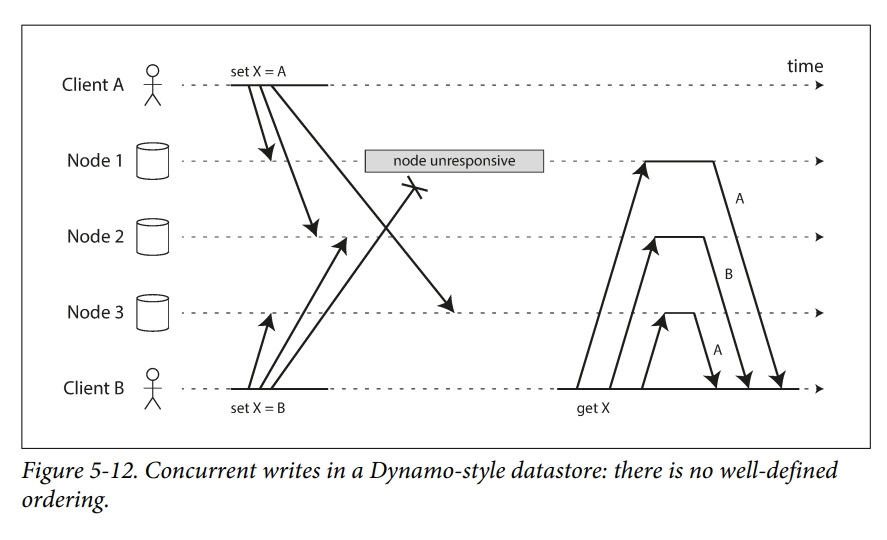
如果每个 node 收到什么 write 就写什么 write 的话,系统就永远不会一致。比如上面的情况下,Node 2 认为最终的值是 B,而其他节点认为是 A。
为了实现最终一致,系统需要最终能够收敛到一个值,但这很难。
一种实现最终一致的方案是永远使用“最新”的写入。这样,只要我们有办法定义出来什么样的是最新的,就可以等待复制完成。
但在上图中,根本无法定义最新,因为每个 write 在不知道其他 writes 的情况下发生,所以这些 write 都是并发的。对此,一种 last write wins (LWW) 的方案提出,可以指定一个顺序,这个顺序就用某种时间戳来表示。
但这种 last write wins 方案会丢失持久性,比如有多个 writes 都达到了 w quorum,所以它们都会给客户端返回成功,但是 LWW 会使得只有一个 write 存活,其他的写入都会被静默丢弃了。此外,在 clock drift 的情况下,LWW 可能会丢掉实际上不是并发的写入,见“关于 time-of-day clock 的问题”。
关于 time-of-day clock 的问题
这一部分主要在 Chapter 8 中。
Cassandra 的 time-of-day clock 基本上是不可能 Linearizability 的。作者列了很多原因:
- clock drift
- 如果 CPU 有缺陷,或者网络配置错误,那么计时服务极有可能不能正常工作
- 如果 quartz 钟有缺陷,或者 NTP 客户端配置错误,那么计时服务会看起来正常工作,但实际上越来越离谱
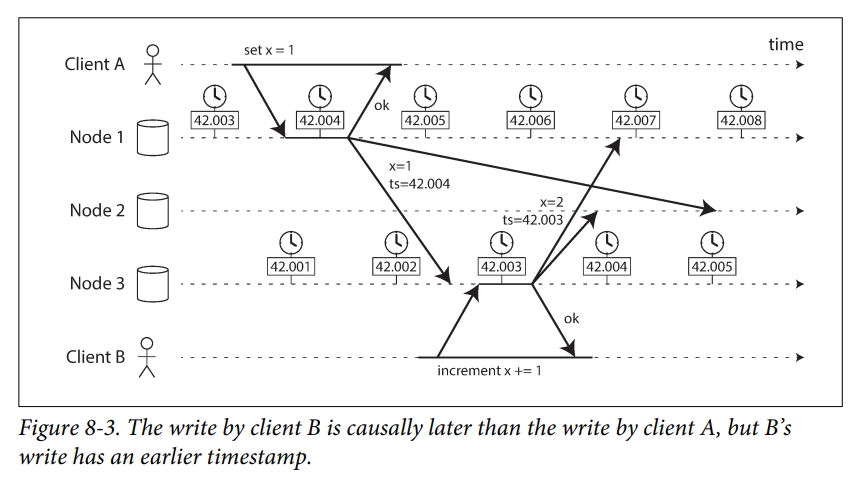
如下图所示,当消息被发送给其他节点时,会带上一个标记本地时间的时间戳。在下图中,因为 node 1 和 node 3 之间存在 clock drift,node 1 快了不到三毫秒,所以导致了本来应该在前面的 x = 1 到了 x = 2 的后面。这就导致了 client B 的 x += 1 的写入丢失了。
如上的行为称为 last write wins (LWW),被 multi leader replication 或者 leaderless replication 广泛使用。
关于 concurrency
It may seem that two operations should be called concurrent if they occur “at the same time”—but in fact, it is not important whether they literally overlap in time. Because of problems with clocks in distributed systems, it is actually quite difficult to tell whether two things happened at exactly the same time—an issue we will discuss in more detail in Chapter 8.
For defining concurrency, exact time doesn’t matter: we simply call two operations concurrent if they are both unaware of each other, regardless of the physical time at which they occurred. People sometimes make a connection between this principle and the special theory of relativity in physics, which introduced the idea that information cannot travel faster than the speed of light. Consequently, two events that occur some distance apart cannot possibly affect each other if the time between the events is shorter than the time it takes light to travel the distance between them
In computer systems, two operations might be concurrent even though the speed of light would in principle have allowed one operation to affect the other. For example, if the network was slow or interrupted at the time, two operations can occur some time apart and still be concurrent, because the network problems prevented one operation from being able to know about the other.
The “happens-before” relationship and concurrency
Merging concurrently written values
LWW 能不能不静默丢弃数据呢?可以,这被 Riak 称为 merge sibling values,需要应用层做额外的工作。
比如可以将写入 union 起来,然后如果需要删除,那么就要用一个 deletion mark 来标记。
Version vectors
【情况6】Strict Quorum 也可能达不到 Linearizability
如下图所示,register x 的初始值是 0,现在 Writer 写入 x = 1,并异步地复制到三个 Replica 上。那么 Strict Quorum 是 2。Reader A 读了 2 个节点发现 x = (1, 0),Reader B 同样读了 2 个节点,发现 x = (0, 0)。从 RWN 的角度来看,r + w > n 了,但这显然不是强一致的,Reader A 的请求被返回之后,Reader B 才开始执行,但 B 获得的值却比 A 要旧了。这实际上也类似于 Figure 9-1 中的定义的问题,也就是访问不同的节点能够得到更旧的结果。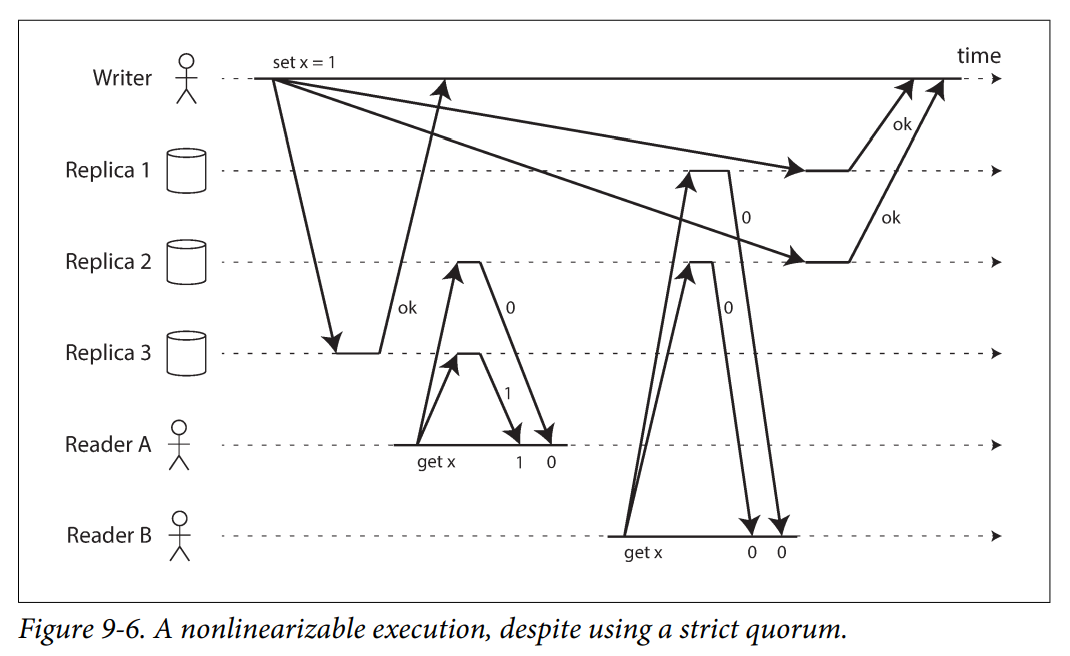
当然,按照 Linearizability 定义,Dynamo 的 RWN 也是可以做到的,这需要上面提到的 Read Repair 机制。但是也有人说 Read Repair 也不一定能实现线性一致,得看如何实现的,比如如果是异步去 Read Repair,那可能就不行。
但是 Riak 并没有使用同步的 read repair,因为影响性能。Cassandra 确实会等待 read repair 才会返回,但它同样会丢失线性一致,因为它使用了 last write wins 策略。
级联复制
级联复制模式下,部分 Slave 的数据同步不连接 Master,而是连接 Slave。
分布式系统上的一致性和 Order
这一部分总的来说是对 Chapter 5 和 Chapter 9 的更为细节的介绍,例如会介绍 Chandy-Lamport 快照、FLP 定理等,也会对本文中提到的一些问题进行总结。理论性较强,拓展较多,所以详见我的专题文章。
partition
一致性Hash
雪崩问题
令环 A -> B -> C -> D -> A,如果 A 崩溃了,会导致数据从 A 往 B 迁移,这几乎导致 B 必然崩溃。
为了解决以上的雪崩问题,可以引入虚拟节点的方案。
缓存的一致性问题
讨论一下缓存相关的问题,主要以 Redis 为主。
缓存双写
最经典的缓存数据库双写模式是 Cache Aside Pattern,也就是先更新库,再删除缓存。与之配合的是先读缓存,如果缓存没有的话就读库,顺便更新缓存。
为什么选择删除缓存,而不是更新缓存的原因是更新缓存的代价比较大。例如缓存中有数据库里面 a 和 b 两个字段的缓存,还有一个缓存 c 是由一个复杂的函数 func(a, 6b) 计算得到的,那么单独更新 a 之后,还需要重新计算一下 c,而事实上这个 c 并不一定是被频繁使用到的,所以等到用到再 lazy 算就可以。
Cache Aside Pattern 模式依然存在不一致问题,它常常在高并发场景下出现。
比如有人提出可以用一个队列维护。总的来说就是先删除缓存,然后写数据库,并更新缓存,这两个会进入一个队列中。然后查询发现缓存为空了,就在同一个队列中先入队一个更新缓存的请求,再入队一个从缓存读的请求。我理解这种方案实际上还是强制每次从数据库读了,但是它在内存中维护了一个全序的单点队列,通过这个队列,它能够得到一个全序关系。通过这个全序关系,它可以判断什么时候从缓存读是安全的。这里强一致的保障是单点,如果我们有两个缓存,分别用不同队列维护。那么因为队列被 apply 的进度不一样,我觉得客户端从不同缓存读的结果可能是不一样的。如下所示,B 的读早于 A 的读,但是它返回的值却比 A 要新,这肯定是违背强一致的:
- 客户请求缓存 B 的写
- 客户请求缓存 B 的读
- 客户请求缓存 A 的读
- 缓存 A 要求更新,得到 x = 1
- 缓存 B 写入 x = 2
- 缓存 B 要求更新,得到 x = 2
- 缓存 B 返回读取 x = 2
- 缓存 A 返回读取 x = 1
而一旦单点,对同一个数据的读写请求必须要在一个节点上完成。那么当数据更新很频繁时,读请求可能被长时间阻塞。并且也很容易出现热点。
缓存雪崩、穿透和击穿
缓存雪崩、穿透和击穿是使用缓存时出现的致命性问题。
缓存雪崩主要出现在缓存宕掉后,所有的流量会打到数据库上,从而数据库也挂了,导致整个服务崩溃。“雪崩”二字,形象生动。处理方案分为:
- 事前:Redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:限流降级,避免 MySQL 被打死。
例如本地 ehcache 缓存、hystrix - 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
缓存穿透是一种恶意攻击的手段,它构造大量的请求去查询一些缓存中肯定没有的数据,迫使所有的请求都打到数据库上面,从而导致数据库宕机。解决方案就是对所有查不到的值,在缓存中创建一个空值。
缓存击穿指的是一个热点 Key在失效的瞬间,大量对它的请求会击穿缓存,打到数据库上面。和雪崩相比,它更接近于在缓存上凿了一个洞。解决方案包含:
- 如果更新频率低,可以设置为永不过期
- 如果更新频率较低,可以通过分布式锁来保证只有少数的请求能请求数据库并更新缓存,其余的线程在所释放后再请求缓存
- 如果更新频率高,可以用定时线程在过期前主动构建缓存,或者延迟缓存过期时间
并发竞争写
这个问题出现在多客户端并发写一个 key 时,其中 A 读和 B 读可能乱序,A 写和 B 写也可能乱序。可以采用分布式锁来解决该问题。并且维护一个时间戳,往数据库更新时,必须要满足缓存的时间戳要比数据库的时间戳大。
缓存Demo:Redis
Redis内存淘汰机制
详见我的专题文章
Redis主从模式
Redis集群模式
在之前版本的 Redis 中,多节点部署需要依靠诸如 codis、twemproxy 等中间件实现。也就是客户端对中间件读写,由中间件管理 Redis 实例。
现在版本的 Redis 原生支持了 Redis Cluster 方式。Sentinel 是高可用和一写多读方案,Redis Cluster 是 Sharding 方案。
生产环境下的 Redis 部署
Redis持久化方式
详见我的专题文章
分布式事务
由于分布式系统中存在多个副本,所以维护这些副本的一致性成为核心问题之一。分布式事务相对于仅涉及单个数据库事务的难点在于其提交或回滚不仅决定于自身,还决定于其他节点上事务执行的状态。从理想考虑,只要有一台节点失效,其他节点就要进行 rollback。为了实现这一点,需要一个协调者(Coordinator)来根据所有参与者(Cohorts)的情况判断是否完成提交或终止提交。同时协调者的故障称为单点故障,也就是这个故障能够直接导致集群无法运行,需要特别考虑。
详细讨论,可以参考 数据库系统中的事务
2PC和3PC
对于分布式事务处理,MySQL 引入了 XA 机制,也就是所谓的 2PC、3PC 的算法。这种方案是在数据库层面的,也就是通过一个事务管理器去协调各个事务的提交,因此往往不能很好地适配现在微服务的框架,因为微服务下不允许访问其他服务的数据库。
出于篇幅限制,见文章2PC和3PC。
TCC
补偿事务(Try-Confirm-Cancel, TCC)的中心思想是:针对每个操作都要注册一个与其对应的确认和撤销操作。相比于2PC等算法,TCC是一个应用层面的协议。
这个方案对应用架构是强侵入性的,因为要求每个业务的接口都要实现 TCC 三个接口。所以一般用在金融领域。
分布式锁
在使用分布式锁前,可以先考虑是否能够通过原子写+多读来维护分布式状态。
通过Redis实现分布式锁
SETNX命令
这里NX表示会创建也就是说如果不存在就创建一个key,表示这个进程获得了锁。- 解决持锁进程崩溃带来的死锁问题
给锁字段加一个超时时间,即使用EXPIRE命令。 - 现在需要SETNX和EXPIRE两条命令,不是原子的了
有两个选择:- 对于旧版本,可以使用LUA脚本
- 对于新版本,可以使用新的SET命令
- 确定锁的所有权
有人问,为什么要确定锁的所有权呢?我加锁的进程自己知道,没加成锁的进程也自己知道。其实不然,假如说进程A加锁之后,锁过期了,被进程B重新获得,那进程A是不知觉的。他可能直接把锁DEL掉了,但实际上他DEL的是进程B的锁。但如果每个进程,用随机数,或者pid来标记,并且在删除的时候判断下,就不会有这个问题了。
分布式共识
本章有一些部分理论性较强,现在已经移动到专题文章,包含:
- CAP
- FLP
- 拜占庭问题
可用性
可用性即reads and writes always succeed。这个要求系统能够始终在正常时间内对用户的请求进行响应。当然由于可能出现的一致性问题,这个响应不一定是正确的。
分区容错性
分区容错性即the system continues to operate despite arbitrary message loss or failure of part of the system。由于分布式集群中常出现网络分区情况,即集群中的一部分机器与另一部分机器中断连接,这可能是由于网络故障,产生网络分区;也可能是由于某些节点宕机。网络分区可能产生的一个后果是脑裂(split brain),也就是存在多个节点认为自己是领导者。
除非设计出一个永远不会出故障的网络,否则必须要容忍 P。于是 C 和 A 便成为了 trade-off。由于网络分区的概率比较小,并且是易于探测的,所以 C 和 A 大多数情况是能够比较好地满足的。所以要做的不是根除网络分区及其导致的部分失效(partial failure)问题,而是去正确地处理它,这就引入了诸如 2PC、RWN、Paxos 等分布式共识协议。
常见的共识算法介绍
Raft
出于篇幅限制,有关Raft已经移到新文章Raft共识算法中。
Paxos
出于篇幅限制,有关Paxos已经移到新文章Paxos算法中。
Reference
除去在原文中标注引用的内容外,本文还参考了一下内容:
- DDIA
- 本文中提到的所有概念的原论文,例如FLP定理等。
- Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores
- High Performance MySQL, 3rd edition
- Zookeepers’s atomic broadcast protocol: Theory and practice
- ZooKeeper: Wait-free coordination for Internet-scale systems
- A simple totally ordered broadcast protocol
- http://duanple.com/
- https://danielw.cn/FLP-proof
- https://www.cnblogs.com/firstdream/p/6585923.html
- http://loopjump.com/flp_proof_note/
- https://www.cnblogs.com/grefr/p/6087942.html
- https://www.bilibili.com/video/BV17A411W7Cr?p=12
- https://danielw.cn/history-of-distributed-systems-5

