我将直接根据github上的unstable分支代码分析。主要是2018年7月版本(dict实现的大部分)的和2020年8月版本(其他部分)的,所以可能会有细微差别。因为Redis的代码比较好读,并且质量很高。这里还推荐《Redis设计与实现》一书,它介绍了Redis中部分比较有趣的设计思路,可惜还有些没有覆盖到,本文中对这些有趣的设计也进行了论述。
Redis中主要包含了字符串STRING、列表LIST(双向链表)、集合SET、哈希表HASH、有序集合ZSET五种最常见的类型。在后续的版本中,还提供了bitmap、geohash、hyperloglog、stream这四种类型。
这些对象依赖于一些内部结构,包括字符串(SDS)、哈希表(dict)、链表(list)、跳表(zskiplist)、压缩双向表(ziplist)、快表等。注意出于性能原因,一个对象的实现往往根据具体的内容而选择不同的实现。列举如下:
- STRING
使用int、sds(raw)或者embstr。
下面的类型也是使用STRING的存储的:- hyperloglog
- bitmap
- HASH
使用dict或者ziplist方案。 - LIST
3.0是使用list或者ziplist的方案。
目前使用快表。 - SET
使用dict或者intset的方案。 - ZSET
视数据规模选用ziplist和skiplist+dict的方案。
下面的类型也是使用ZSET的存储的:- GEOHASH
本文中不介绍的是,它们在系列的其他文章中讲解:
- Redis基础设施
- Redis Sentinel
- Redis Cluster
- Redis AOF/RDB
最后,本文的主体部分已经完成,但后续仍然会进行修订,或者补充。
SDS
SDS(simple dynamic string)是Redis中的动态字符串实现,没错,Redis又重复了C/C++的传统,自己造了套轮子。我们考虑一下设计一个字符串的几个方面,复制/移动效率、空间效率、编码问题。例如在std::string中就会进行一些短串优化(SSO)(对每个字符串对象内部维护一段较短的buffer,当buffer不够用时再向堆请求空间)、写时拷贝(COW)的方法来进行优化,这会导致不同STL下c_str的不同行为。但在字符串设计时,常将其实现成immutable的,以Java为例,这是为了防止在外部对容器(如Hashset)中对象的更改破坏容器的特性(Hashset的唯一性)、并发、便于进行常量池优化考虑。但是SDS却是可变的,并且被用在实现键和值中。例如SET hello world中,键hello和值world的底层都是SDS。此外,由于其可变性,SDS还被用作缓冲区。
查看sds的实现,发现是一个char*,难道直接就是一个char*的原生表示么?其实还真是这样,可以直接通过printf("%s", s)打印这个sds。
1 | // sds.h |
那么问题来了,sds的中间段可以有\0,Redis总不会用O(n)来算字符串长度吧,那么元信息报错在哪里呢?我们看到Redis提供了支持不同最大长度的sdshdr类型,和sds开头的C-style的字符串函数。所以说元信息是保存在sdshdr里面的。
1 | struct __attribute__ ((__packed__)) sdshdr5 { |
简单解释一下这几个参数:
- len
len表示了字符串的长度,所以我们省去了strlen的开销,虽然我们还是可以直接对sds用。 - buf
特别地,buf实际上是一个二进制数组,\0可以出现在中间,Redis只保证buf最终以\0结尾。而这个buf实际上就是sds所指向的东西,我们将在稍后解释这一点。
现在要讲解的重点是Redis是如何组织sdshdr和sds的,事实上它们的内存布局如图所示。容易看出,给定一个sds,可以直接当做char*来处理,但也可以往前推sizeof(sdshdr)大小,去获得sdshdr结构。而到底往前推多少字节,取决于
1 | sds |
创建
1 | sds sdsnew(const char *init) { |
可以发现,主要是会调用sdsnewlen这个函数。这个函数根据传入的init和initlen创建一个sds,例如:
1 | mystring = sdsnewlen("abc",3) |
如果init传入的是NULL,那么就用\0初始化。但不管怎么样,这个sds总是以\0结尾,所以可以用printf打印。但和char*不同的是,sds的中间段可以有\0。
1 | sds sdsnewlen(const void *init, size_t initlen) { |
特别注意,这个函数会导致“复制”,而不仅仅是将指针指向init。
首先,看一下这个type
1 | static inline char sdsReqType(size_t string_size) { |
可以看出,根据要分配的字符串的长度,会给到不同的SDS_TYPE_,实际上也就对应到不同长度的sdshdr对象。比如对长度小于1<<8的字符串来说,我们只需要一个sdshdr8类型的头部去维护它的长度。
1 | struct __attribute__ ((__packed__)) sdshdr8 { |
下面我们就要具体来分配一个sdshdr对象了。
1 | // 续sdsnewlen |
看一下sdsHdrSize,不出所料,是根据type去sizeof算得需要使用的sdshdr对象的大小。
1 | static inline int sdsHdrSize(char type) { |
下面是分配了sdshdr对象和sds字符串的所有的内存。sh指向的是包含头部和实际数据以及结尾的\0的一块内存。
1 | ... |
下面一个有趣的是s,它实际上就是最后要返回的sds了。SDS_HDR_VAR(T,s)表示最大长度为T,指针为s(实际数据而不是header)的sds,生成其header的指针,命名为sh。fp指向header中的flags字段,直接从s计算了。
1 | ... |
list
在新版本下,Redis中的list(t_list)的实现借助于快表,但本章主要是讲解原始双向链表list的实现,它被定义在adlist文件中。
1 | typedef struct listNode { |
可以看到,保存了head、tail和len的值,因此len操作是O(1)的。
dict
dict是Redis中非常重要的结构,它不仅被用来实现HASH等数据结构,而且还被广泛地使用到Redis数据库服务器等基础设施中。在本章中,将介绍dict的实现,并使用HASH数据结构跟踪到dict的上层调用。我们首先看一下dict类的包含关系。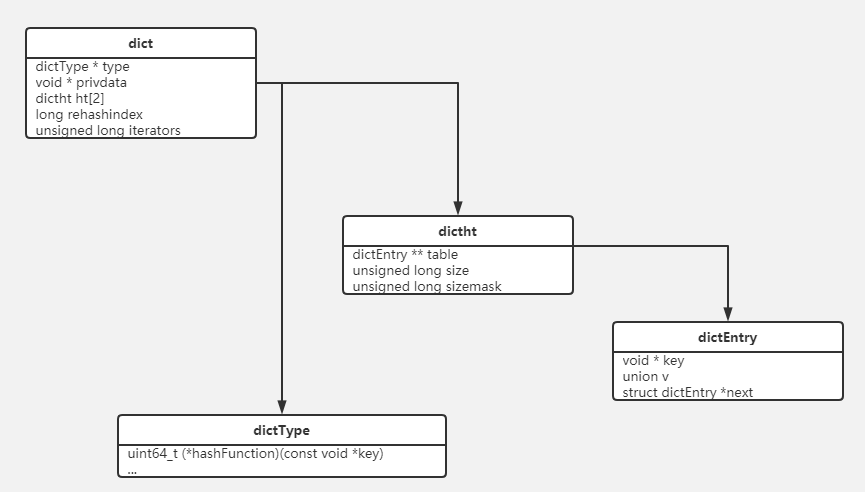
其中,union v包含下面的几个类型
1 | union { |
dict的基本实现与Rehash机制
在这个章节中,我们主要介绍dict的主要实现和Hash以及Rehash机制。
dictEntry、dictType、dictht
dict的实现在dict.h中,注意在deps/hiredis中也有另一个实现,注意不要搞混。
1 | typedef struct dictEntry { |
dictEntry是一个KV对,可以看到Redis以链表的形式存储KV,并且使用union来优化空间存储。我们不能从dictEntry获得任何的类型信息,实际上它是作为下面dictht对象的一个组件来使用的。
下面是dictType这个类,实际上决定了对应的行为。
1 | typedef struct dictType { |
在server.c中,分门别类定义了各种dictType。这些type都是在dictCreate作为参数传入的,会产生不同的复制、析构、hash、比较等特性。
我们在先前也介绍过了db->expires是一个keyptrDictType,他在析构的时候不会删除对应的key,但是db->dict是dbDictType,这就不一样了。
1 | /* Generic hash table type where keys are Redis Objects, Values |
dictht描述了一个哈希表,它将dictEntry组织起来,它维护了长度和节点数等信息,但并没有描述这个哈希表的行为、类型等信息,它将被进一步封装。
1 | typedef struct dictht { |
具体解释一下dictht的一些成员:
- table
乍一看,就很奇怪,为啥是个二维数组呢?
外面一维是哈希的桶,里面一维是开链表。
这个在Rehash的时候有介绍,到时候要将这些桶拆开来,将每个dictEntry而不是每个桶进行Rehash。【Q】为什么要这样麻烦呢?这是因为到时候桶里面的元素不一定都属于新的桶里面了。 - size
这里的size表示桶的数量,是2的指数。因此size的扩张只会在dictExpand中发生。而真正添加元素只是加到对应桶的开链表里面。
需要和dictSize函数区分一下,后者表示dict中两个ht中所有的元素数量而不是桶的数量。 - sizemask
始终是size-1,这个是2质数增长的一个很经典的一个实现了。 - used
表示哈希表中装载的元素数量,也就是每个桶中所有链表的长度之和。
因为开链表的存在,used是可能大于size的
Hash
看到这里有个疑问,似乎这里的key是一个指针,而不是我想象中的一个SDS或者char*值,难道我们仅仅是根据key的指针值来进行哈希么?事实上并非如此,根据不同的dictType,实际上会有不同的Hash函数。可以看到对于大多数key为SDS的情况,会落到dictGenHashFunction的调用上。在3.0时代,这个函数是一个对MurmurHash2函数的调用,在当前版本下,这是一个对siphash函数的调用
1 | // server.c |
dict和dictAdd
我们接着来看上面的dictht结构。就和我在libutp里面看到的环状缓冲区一样,这里size和sizemask已经是老套路了,我们已经可以想象size一定是按照2的级数增长的,然后sizemask一定全是1给哈希函数算出来的值&一下。下面我们来看一个dictAdd的调用过程,以验证我们的思路。
这些宏用来封装调用dictType中定义的方法,从而实现对不同类型的不同哈希。
1 |
|
检查是否已经存在
dictAdd会最终调用dictAddRaw,然后会调用一个_dictKeyIndex,这个函数给定key,返回哈希表中可以插入到的slot的index。如果key已经在哈希表中存在,返回-1,并通过existing取回。
1 | // dictAddRaw <- dictAdd |
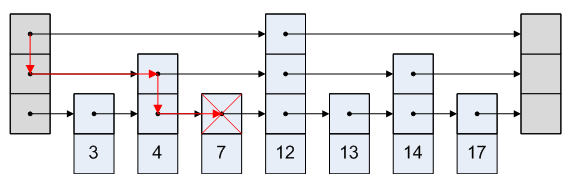
这个函数主要就是一个for循环,这个循环在dict中是非常常见的对所有dictEntry遍历的循环,我们列在“dict遍历抽象主干代码”这个章节里面。循环关键如下:
遍历所有的table,如果正在Rehash过程中,那么就会有两个table。
【Q】根据源码中的注释,如果在Rehash过程中_dictKeyIndex返回那个idx,一定是ht[1]对应的索引值?
这在说啥呢?参考“会不会有两个键出现在两个table里面?”这个讨论,如果在Rehash过程中,我们插入要插入到新的表ht[1]中,所以插入的位置idx,也应该是新的表中的位置idx。下面的for循环从0到1的顺序保证了这一点。1
for (table = 0; table <= 1; table++)
我们根据key的哈希值,找到对应的桶
d->ht[table].table[idx]。我们遍历这个桶的开链表。
1 | // _dictKeyIndex <- dictAddRaw <- dictAdd |
函数的返回值选取idx即可,具体的dictEntry *,如果调用者有需要,我们才设置*existing用来返回。因为我们用这个函数不仅是看有没有,还要顺便获得在后面插入位置。返回并保存链表头,后面就可以直接从链表头插入,这样的好处是一方面我们只要记录一个链表头,另一方面是Redis假设最近被添加的字段会被频繁访问。
这里可以总结出链表使用的经验,如果需要快速push,保存链表头。如果需要快速pop,保存链表尾。
1 | ... |
在刚才的代码中出现了dict这个结构,它也就是我们真正提供的完备的哈希表。因此,到这里的“继承关系”是dict <- dictht <- dictEntry
1 | typedef struct dict { |
同样简单介绍一下成员:
- type/privdata
用来实现类似继承的机制,这样我们可以自定义dict的行为。 - ht
是两个dictht结构,每一个dictht就是上面提到的一个哈希表。这个用来实际保存数据。
可是为什么是长度为2的数组呢?这里的ht[1]在rehash的时候用,在rehash的时候会把ht[0]慢慢搬到ht[1]上。 - rehashidx
用来表示此时Rehash的过程(具体机制查看后文)。
-1表示未在Rehash。
>=0表示Rehash开始,将要移动ht[0].table[rehashidx]这个桶。 - iterators
表示这个字典上的安全迭代器的个数。
哈希表的扩容
当哈希表容量不够时就需要进行扩容,同时需要进行Rehash。下面我们正式来研究哈希表的扩容与Rehash部分
根据_dictExpandIfNeeded,扩容需要满足几个条件:
used >= size
回忆一下,size是桶的数量,used是键的数量。used是会大于size的,因为开链表。dict_can_resize
根据updateDictResizePolicy函数,在一些情况下dict_can_resize是false,这时候不会扩张。
根据《Redis设计与实现》,这种情况发生在BGSLAVE或者BGREWRITEAOF命令运行时针对COW机制的一个优化。这两个命令实际上是后台写RDB和AOF的实现。- 但是当used/size大于一个比例,默认是5,会强制扩张(注意扩张还是按照2倍)。
1 |
|
下面的dictExpand就是扩容函数
1 | /* Expand or create the hash table */ |
假如ht[0]是空的,那这是一次初始化,直接将ht[0]指向新的hash表n。
1 | ... |
否则将ht[1]指向新的哈希表n。
1 | ... |
Rehash
我们看到扩容操作只是创建了一个空的哈希表,并没有真正移动ht[0]的元素到ht[1]对应的位置上(这个过程被称作桶转移),难道这里又是COW了?
答案是肯定的。通过优秀的英文能力,我们猜到了真正做Rehash的函数int dictRehash(dict *d, int n),dictRehash在dictRehashMilliseconds和_dictRehashStep中被调用。
dictRehash对d做**n**步的Rehash,其中一步表示将ht[0]中的一个桶d->ht[0].table[d->rehashidx]移到ht[1]上。注意下面几点:
这里的
d->ht[0].table[d->rehashidx]是一个开链表。我们不能直接移动桶,因为到时候里面的元素可能Rehash到不同的桶里面。所以,我们只能遍历桶的开链表里面的所有key,然后逐个放到新的table里面。
容易看出
ht[0].size > rehashidx是始终成立的。
因为ht[0].size就是桶的最多数量,rehashidx表示现在哈希到第几个桶了。这个**
n**的计算不包括空桶,Redis每次哈希可以跳过empty_visits个空桶,这时候我们要做的仅仅是自增d->rehashidx。dictRehashMilliseconds
定时Rehash函数incrementallyRehash在后台被databasesCron定时调用,起到定时Rehash每个db的dict和expire表的作用。
dictRehashMilliseconds是一个时间相关的函数,它会在在ms毫秒的时间里面rehash尽可能多的桶,也就是每rehash 100个桶之后检查一下有没有超时,没有就接着来。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// server.c
void databasesCron(void) {
...
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
...
}
int incrementallyRehash(int dbid) {
/* Keys dictionary */
if (dictIsRehashing(server.db[dbid].dict)) {
dictRehashMilliseconds(server.db[dbid].dict,1);
return 1; /* already used our millisecond for this loop... */
}
/* Expires */
if (dictIsRehashing(server.db[dbid].expires)) {
dictRehashMilliseconds(server.db[dbid].expires,1);
return 1; /* already used our millisecond for this loop... */
}
return 0;
}
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}_dictRehashStep
_dictRehashStep在诸如dictAddRaw、dictGenericDelete、dictFind、dictGetRandomKey等函数中被调用,作为dictRehashMilliseconds的补充。1
2
3
4static void _dictRehashStep(dict *d) {
// 只有当
if (d->iterators == 0) dictRehash(d,1);
}
下面我们来看一下Rehash的过程。最外面是一个大循环,表示移动最多n个桶。
1 | int dictRehash(dict *d, int n) { |
我们最多跳过empty_visits == n*10个空桶,此时只更新rehashidx,不计算n。
1 | ... |
下面开始移动非空桶。注意我们不能直接将这个非空桶整个移植过去,因为里面的key在Rehash之后可能会去到其他的桶里面,所以我们用de来遍历这个开链表。
1 | ... |
在大循环移动完n个桶,或者遇到太多的空桶退出之后,检查ht[0]是不是已经结束了。
1 | ... |
我们发现在Rehash的过程中,调用dictRehash都将ht[0]掏空一点给ht[1],直到最后过程结束后将ht[1]指针赋值给ht[0]。
ht[0]和ht[1]的顺序
【Q】如果在Rehash过程中,增删改查需要考虑下面几点(注意我们的语境是在Rehash下!!):
- 对于插入操作,会不会在
ht[0]中已经有了,我们又新插入到ht[1],导致一个值在两个地方,或者反过来?
这个是不可能的。首先,我们要规定插入只能在ht[1];然后在每次插入前,我们都要在ht[0]和ht[1]中都检查一遍。 - 对于删除操作,会不会只删除ht中的数据?
总结一下,在Rehash的过程中我们插入必须对ht[1],而查找删除优先在ht[0]操作,然后再ht[1]。Rehash在对哈希表每一次的增删改查中渐进进行,我们查看相关代码。
首先看插入,我们首先调用_dictKeyIndex,如果不存在,则:
- 如果不在Rehash,那么返回
ht[0]中待插入的idx - 如果在Rehash,则返回
ht[1]。关于这部分,在_dictKeyIndex讲过了。
1 | // dictAddRaw |
对查找来说,也是从ht[0]查,再查ht[1]
1 | // dictFind |
删除同理
1 | // dictGenericDelete |
遍历机制(dictScan)
Redis中的遍历分为两块,第一个是dictScan函数,第二个是借助dictIterator这个迭代器。其中,前者用来对外提供SCAN,后者主要用来服务其他数据结构。我们首先介绍dictScan。
由于Redis中哈希表的动态扩展和缩小中有渐进Rehash的过程,所以做到恰巧一遍的遍历是非常难的,函数dictScan的实现确保了每个元素都能遍历到,但可能存在元素被重复遍历。函数dictScan接受一个cursor即参数v,并移动这个cursor,返回其新值,初始情况下我们传入v为0。
dictScanFunction表示需要对每一个dictEntry设置的函数。
dictScanBucketFunction表示需要对每个桶设置的函数。
1 |
|
这里对v的更新十分奇妙,按照理想情况,我们完全可以去直接v++,然后遍历完所有的桶。但是那四行代码的行为却很奇特,这种遍历方法被称为reverse binary iteration:
- 首先第一行将
v的会和~maskor一下 - 第二行调用
rev将v按比特反转,这时候高位填充的1就到了最低位上。 - 接着后面两行进行自增,再倒回去。
这么做的结果是二进制的进位是反向的,我们首先对最高位自增,如果高位溢出了,就对低位进位。
我们首先介绍一下rev这个函数,它的作用是将一个二进制串前后倒置。
1 | // 进行位反转 |
打印下来是这样的
1 | 0000000000000000000000000000000000000000000000000001011011101111 |
以mask = (uint8_t) 15(0x1111)、v = (uint8_t) 2为例查看一下这个过程。
1 | 00000010(2)初始状态 |
我们从v=0开始迭代,发现值依次是
1 | 0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15 0 |
【Q】为什么要做这样的设计呢?因为Rehash是以2为倍数扩展或者收缩的,这样遍历之下,能够保证Rehash之后,既不会漏掉,也不会重复遍历。
我们考虑将数字[0,7]哈希到2和4的不同情况,可以发现哈希到4时每个slot里数字的后2位都相同,而哈希到2时每个slot里数字的后1位相同。我们可以认为从$2^i$到$2^{i+1}$,我们将每个slot中的数按照第i位的值分成两个slot。
1 | 0(00):0(000),4(100) |
在上面讨论了更通用的情形,特别用了slot而不是之前提到的桶的概念。在这篇文章中,一个桶指的是ht中哈希值相同的所有元素组成的链表,也就是dictht的dictEntry** table的第一维。现在讨论的dictScan是针对桶的扫描而不是元素的扫描。特别地,我们将哈希表中的N个桶合并成N/2个桶时,相当于做一次针对桶的哈希。考虑一个8个桶的哈希表,其桶的遍历顺序是0 4 2 6 1 5 3 7 0。假设遍历6(110)前我们将8个桶缩小到4个桶,那么桶6中的元素应当被映射到新桶2(10)中了,因此我们应当遍历2(10)这个桶,此时我们已经遍历过的桶如下示意
1 | 新桶 原桶 |
容易发现此时我们重复遍历了原来桶2(010)中的元素。这个过程结束时新的mask为3,v会更新到1(01),我们发现下面要遍历的1 5两个就桶被合并到了1(01)这个新桶里面。如果考虑遍历2(010)前发生了缩小,那么我们就不要重复遍历元素。
遍历机制(迭代器)
迭代器的声明如下,容易看出通过d、index和table我们可以确定一个桶。safe表示这个迭代器是否是一个安全的迭代器。
1 | typedef struct dictIterator { |
我们将在下面逐一介绍相关的字段用法
安全迭代器
安全的迭代器是什么意思呢?比如在Rehash机制中,存在safe迭代器的情况下是暂停Rehash的。只有当iterators数量为0时,才会进行Rehash。1
2
3
4
5
6
7
8
9/* Rehash for an amount of time between ms milliseconds and ms+1 milliseconds */
int dictRehashMilliseconds(dict *d, int ms) {
if (d->iterators > 0) return 0;
...
}
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}需要注意的是,在Redis的6.0版本上,dictScan也会增加iterators,从而导致rehash停止。而在5.0版本还没有这个限制。【Q】为什么会有这个限制呢?
fingerprint
用来将两个ht的指针、size和used进行哈希,在dictNext开始和结束之后比较哈希值,如果不一样的话,就assert。这主要是用来保证,当不安全迭代器被使用时,该迭代器的使用者不能对这个哈希表做出不合法的操作。
dict迭代器相关方法
搜索dict这个迭代器主要作用是在redis内部,例如持久化相关的工作。dict迭代器的相关方法主要包括dictNext、dictGetIterator、dictGetSafeIterator、dictReleaseIterator。
dictNext
dictNext的实现比较特别,它会缓存当前的iter->entry,以及下一个iter->nextEntry。主要流程如下:
- 初始化
指向0这个table。指向0这个dictEntry。
iter->index表示遍历的distEntry的位置,iter->entry表示被遍历的那个distEntry。 - 如果
iter->entry是NULL
通常是因为初始化,或者遍历完了一张表
如果遍历完了所有的dictEntry,就换到table 1。当然没有Rehash的话就结束。 - 如果
iter->entry不是NULL
这是大部分情况。
我们移动到iter->nextEntry,然后去更新iter->nextEntry。
这里要用nextEntry的原因是安全迭代器是能够对哈希表进行增删的,因此如果iter->entry在迭代时被删除了,那么就会导致iter->entry->next是无法访问的,因此这里要提前保存一下。
1 | dictEntry *dictNext(dictIterator *iter) |
dict的其他相关方法
dict遍历抽象主干代码
由于在dict中常出现遍历操作,为了方便阅读代码,我们将整个遍历操作先抽象出来,在下面相关代码的介绍中,只列出主干。关于这个循环的说明,可以参看_dictKeyIndex的讲解
1 | // dict.h |
dictFind
这个函数用来根据给定的key找到对应的dictEntry,如果找不到,就返回NULL。
其中涉及一些Rehash相关的机制,我们在先前已经讲过了,在这里就略过。
1 | dictEntry *dictFind(dict *d, const void *key) |
dictGet系列函数
这个系列的函数主要通过读取union v里面的不同类型的值。
1 |
dictDelete和dictGenericDelete
dictDelete实现,就是调用dictGenericDelete,并且指定是要free的。注意,我们不要和hiredis里面的dictDelete实现搞混起来
1 | /* Remove an element, returning DICT_OK on success or DICT_ERR if the |
现在我们介绍其依赖函数dictGenericDelete。这函数表示要从d中删除一个key。
在前面已经看到,dictDelete系列函数相比其他操作会多一个场景,也就是会考虑是不是立即将key和value的对象free掉。
1 | static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) { |
但这里对dict遍历抽象主干代码的处理会有一些修改,首先用prevHe来记录待删除节点he的父节点,从而将链表接起来。然后是一个nofree选项,可以不去析构key和value。
1 | // dictGenericDelete中不连续的部分代码 |
而dictUnlink就是设置了nofree=1调用了dictGenericDelete。
1 | dictEntry *dictUnlink(dict *ht, const void *key) { |
HSET的相关数据结构
HSET是对dict的封装。
hset实现
我们还是从redisCommandTable里面查到hset的对应函数是hsetCommand。hashTypeLookupWriteOrCreate这个函数就是调用lookupKeyWrite,如果找不到,就通过createHashObject创建,这个函数是创建一个OBJ_HASH对象。
1 | void hsetCommand(client *c) { |
ZSET
在本章中,我们将会从ZSET切入,了解它是如何包装ziplist和zskiplist的。但是具体到ziplist和zskiplist的实现,是在单独的章节里面讲的。
ZSET有两个实现,基于跳表的和基于ziplist的,具体来说:
- ziplist
是一个双向压缩链表的实现,这里的压缩链表指的是不会保存prev和next信息,而是采用类似线性表的方式将整个list存放在一整块内存中。对应于元素数量少于128,且每个元素的长度小于64字节。 - zskiplist
是个跳表的实现。对应于1之外的情况。
ZSET和zadd
从redisCommandTable找到绑定的函数zaddCommand,它会调用一个zaddGenericCommand
1 | // t_zset.c |
查看zaddGenericCommand,它接受一个flags参数,我们稍后介绍。
1 | void zaddGenericCommand(client *c, int flags) { |
下面一部分代码是用来处理一些额外输入的flag参数,这里引入了scoreidx表示score/value对开始的位置,在3.0版本中写死了是2,但是由于后面版本允许了nx、xx等参数,所以这边改为动态计算的。
1 | ... |
下面的代码主要是校验参数的合法性
1 | ... |
下面,我们开始正式处理参数了
1 | ... |
为了阅读接下来的代码,首先了解两个参数,可以看到,这两个参数就是规定了何时使用ziplist的阈值。上面两个指示了对zset而言,ziplist能用到什么时候,后面就是skiplist。下面两个指示对hash而言,ziplist能用到什么时候,后面就用dict。
1 | // config.c |
然后我们来看一下两个对象的创建方法
1 | robj *createZsetObject(void) { |
下面来看一下创建的逻辑,可以发现,在创建时默认是创建一个ziplist的,其实在后面zsetAdd添加的时候,当超出了ziplist的阈值的时候会调用zsetConvert来转成skiplist。
1 | ... |
下面,就是调用zsetAdd依次往ZSET里面添加元素了。
1 | ... |
zsetAdd的实现
zsetAdd
在3.0版本里面,并没有这个函数,而是直接放到了zaddGenericCommand里面。但由于后续版本支持了各种flag(注意3.0是可以incr的),逻辑复杂了,所以单独做出了一个函数。
1 | int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) { |
首先来讨论一下参数,flags按照指针传递,是因为它同时用来保存输入信息和输出信息。
1 | /* Input flags. */ |
newscore被用来存储返回的incr后的分数。
下面我们来看函数的具体实现过程。
1 | ... |
ziplist存储的分支
1 | ... |
跳表存储的分支
1 | ... |
zsetConvert
参数encoding表示要转换成什么格式。
1 | void zsetConvert(robj *zobj, int encoding) { |
1 | ... |
1 | ... |
zrangeGenericCommand
zrangeGenericCommand主要处理ZRANGE命令。
1 | void zrangeGenericCommand(client *c, int reverse) { |
通过start和end计算出需要取出的长度rangelen。
1 | ... |
对于ziplist的实现
1 | ... |
对于跳表的实现,通过zslGetElementByRank获得我们要遍历的起点ln。在找到之后,直接移动backward指针,或者最底层的forward指针,取出rangelen的元素。
所以对于面试日经题目,跳表的zrange复杂度是多少?答案就是O(log(n)+rangelen)。
1 | ... |
zskiplist
zskiplist是跳表,Redis用它来作为有序集合ZSET的一个实现。
跳表的查找复杂度是平均$O(log n)$最坏$O(n)$,而插入/删除复杂度是$O(log n)$。
基本数据结构
跳表的结构如下所示
结构定义如下所示。
1 | typedef struct zskiplistNode { |
容易看到,这里的level是一个Flex Array,这是C99里面的特性,实际上是一个长度为0的数组。
跳表里面的一个元素,对应一个zskiplistNode。每个zskiplistNode可能有若干个zskiplistLevel,从而组成跳表的层次结构。
backward
这个指针是一个zskiplistNode一个的,指向最下面一层的前一个节点。zskiplistLevel::forward
每一层都有一个,指向当前层的下一个节点。层数越往上,zskiplistLevel::span越大。span
span表示当前节点当前层的后向(forward)指针跨越了多少节点。对于最下面一层,它的span就是1。如果在某一层上,forward相对对下面一层跳过了一个节点,那么span就是2。
这个值对跳表实现不是必要的,增加它是为了方便计算rank[i]。
rank是为了实现zsetRank设置的。【Q】一个问题是为什么需要用rank[i]数组。这个我加日志打印了一下,发现这反映了插入新Node时,我们插入到的是update[i]的后面,而rank[i]就表示这个update[i]到链表头的距离。
考虑zslInsert,我们要插入下面两行1
2
3zadd y 1.0 a 2.0 b 3.0 c 4.0 d 5.0 e 6.0 f
zadd y 4.5 de
zadd y 3.5 cd检查插入cd前的行为。对于4/5层来说,d前面都没有该层节点了,所以rank都是0。同时可以注意到,因为最底层(第0层)永远表示待插入的节点前面有多少个。
1
2
3
4
5
6
7
8
9
10
11
12
13
14rank[0]=3
rank[1]=3
rank[2]=3
rank[3]=3
rank[4]=0
rank[5]=0
SUMMARY: tot level 6
( )[S: 1] ( a)[S: 1] ( b)[S: 1] ( c)[S: 1] ( d)[S: 1] ( de)[S: 1] ( e)[S: 1] ( f)[S: 0]
( )[S: 2] .............( b)[S: 1] ( c)[S: 1] ( d)[S: 3] ..........................( f)[S: 0]
( )[S: 3] ..........................( c)[S: 1] ( d)[S: 3]
( )[S: 3] ..........................( c)[S: 1] ( d)[S: 3]
( )[S: 4] .......................................( d)[S: 3]
( )[S: 4] .......................................( d)[S: 3]
node_len 13
zslCreateNode
我们进一步查看zslCreateNode是如何被初始化的,容易看出,它的空间占用等于zskiplistNode的大小,加上level的长度乘以zskiplistLevel的大小。
1 | // t_zset.c |
跳表数据结构的展现
下面的代码可以轻松地打印出zskiplist的结构。
1 | void printZsl(zskiplist *zsl){ |
我们修改zslInsert代码,并输入下面的语句,为了便于得到更高的跳表,我们设置ZSKIPLIST_P到0.5(参考下文)。
1 | zadd zs2 1 a 2 b 10 c 5 d 5 e 6 f1 6 f2 6 f3 6 f4 6 f5 6 f6 6 f7 6 f8 6 f9 6 f10 6 f11 |
得到打印的结果如下(这里输出是反的,第0层实际上是“最下面一层”,也就是最密集的那一层)
1 | SUMMARY: tot level 7 |
可以比较容易得看出:
- header节点是空的
- span表示当前层上相邻两个节点的实际距离。对于level 0来说,相邻两个节点的实际距离一定为1
zslInsert的实现
跳表遍历抽象主干代码
我们首先看到的是跳表遍历抽象的主干代码,它会在很多地方重复出现。这段代码的含义是计算update[i]和rank[i]。
1 | zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) { |
在以上的代码执行完之后,我们得到了计算好的update和rank数组。我们要在update[i]后面插入节点,并且用rank[i]来更新span。
在这里,我们假设元素没有在跳表中,这是因为:
- 跳表是通过score排序的,而score是允许重复的,所以无法通过score来判断。
- 而在跳表中插入相同的元素是不可能的情况,因为zslInsert的调用者通过dict来维护是否有相同元素。
在插入新节点前,首先需要为这个节点生成一个随机层高,同时处理这个随机层高大于现有层高的情况。
1 | // 续zslInsert |
zslRandomLevel生成待插入节点的随机高度。
注意,这里层数越往上的概率是越低的,最终能够形成一个powerlaw的分布。
1 | // t_zset.c |
下面就是将新增的节点插入跳表中。新链表的前后顺序是update -> x -> update.forward
1 | // 续zslInsert |
下面我们的目标是计算x->level[i].span。从前面介绍过了,span表示当前节点当前层的后向指针跨越了多少节点。由于x被插到了中间,所以需要更新x和update的span。
对于x而言,它继承了update的span的后半部分,即+号覆盖的部分,这个后半部分的长度等于总span的长度减去从update到x的span。
1 | 插入前 update-------------update.forward |
下面这个公式,有点愣神了。为了方便理解,不如先看i=0的情况。
1 | x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); |
- 计算
x最下层的span,即x->level[0].span
结果是update[i]->level[i].span。这是因为x是紧插到update后面的,这样会导致x实际上继承了update的span。 - 计算
update最下层的span,即update[0]->level[0].span
结果是rank[0]-rank[0]+1=1。这是因为update紧后面就是x了,所以这里的1就表示跨越到x节点的距离。
那么,往回看到i取任意值的情况:
- 计算
x->level[i].span - 计算
update[i]->level[i].span
从前面的讨论中,我们可以知道rank[0]表示第0层中,待插入节点x前面有多少个节点。
同理rank[i]表示在第i层中,待插入节点x前面有多少个节点。
那么(rank[0] - rank[i]) + 1就是第i层上,update[i]和x中间有多少个节点。
1 | ... |
zslGetRank实现
注意Rank是从1开始算的。
这里实现还是一个经典的二层循环。
1 | /* Find the rank for an element by both score and key. |
zslUpdateScore的实现
1 | zskiplistNode *zslUpdateScore(zskiplist *zsl, double curscore, sds ele, double newscore) { |
在下面几种情况下,可以不进行先删除再添加的操作,而只是更新score:
- 如果是第一个节点,或者前面的节点的分数比新分数要小。
- 或者是最后一个节点(必须最下层),或者后面的节点的分数比新分数要大。
1 | ... |
在更通用的情况下,我们只能删除原节点x,并且重新插入新节点。
1 | ... |
zslGetElementByRank的实现
这个函数作用是获得的元素,被用来处理跳表对zrange的实现。这里的rank是从1开始的。
此外还有个zsetRank,用来获得元素从0开始的RANK。
这里的遍历,其实和经典的遍历类似。我们从最高层尝试往右移动指针,一旦我们发现移动过头了,我们就转而下沉一层。
1 | /* Finds an element by its rank. The rank argument needs to be 1-based. */ |
ziplist
ziplist是一个比较神奇的结构,通常被用在ZSET和HASH等结构上面。首先我们解释一下它的名字
- zip
说明ziplist是压缩的,空间优化的。那么既然优化了空间,时间可能就会受损。 - list
说明ziplist是一个双向链表,可以存储SDS和整数。
那么,ziplist优化在哪里呢?
- ziplist整体是连续分配的
虽然作为一个链表存在,但它的内存是一次性连续分配的。 - 因为连续分配,所以ziplist省去了前向指针
可以根据这个entry的encoding,直接算出来下一个元素的offset。 - ziplist节约了后向指针的大小
因为只是指定了后向指针的偏移。
格式与创建
首先,分配了头部和尾部的空间
1 | // ziplist.c |
那么头部和尾部究竟是什么呢?
头部包含了32位的int,表示总长度;32位的int表示最后一个元素的offset。16位表示item的数量。在头部保存尾部指针的实现逻辑在链表中是非常常见的,这使得查找尾部的操作是$O(1)$的。
1 |
尾部有一个”end of ziplist” entry,它是一个值为255的byte,表示结束。不过为什么需要这个ZIP_END来表示结束呢?也许是为了遍历的方便,那么在这里我们就能猜测到ziplist里面的元素肯定是经过特殊编码的,255这个编码表示结束,没有第二个编码长这样。
1 | /* Size of the "end of ziplist" entry. Just one byte. */ |
这两个宏可以取头和尾
1 | /* Return total bytes a ziplist is composed of. */ |
下面继续看实现,我们可以看到,ziplist的大小是包括了头和尾的大小的
1 | ... |
格式
下面我们来看看ziplist的编码格式
- 00xxxxxx
xxxxxx表示字符串的位数,最大长度63。 - 01xxxxxx xxxxxxxx
xxxxxx xxxxxxxx(14个x)表示字符串的长度。 - 10000000 aaaaaaaa bbbbbbbb cccccccc dddddddd
从a到d表示字符串的长度。 - 11000000
int16 - 11010000
int32 - 11100000
int64 - 11110000
int24 - 11111110
int8 - 11111111
ZIP_END是255表示结束。 - 1111xxxx
xxxx的范围只能是(00011101), 也就是113。
因为int8和EOF占了14和15的情况。
HyperLogLog
HyperLogLog算法主要用在基数统计中,也就是能用很小的内存占用统计出集合的大小。在Redis中,只需要大概12KB的内存就能够统计接近2**64个不同元素的基数。
HyperLogLog算法是对LogLog算法的改进。包括LogLog Counting采用的算数/几何平均数对离群值(比如0)更敏感,而HyperLogLog采用了调和平均。这里的LogLog指的是算法复杂度是$O(log(log(N_{max})))$
HLL原理
HLL通过一个哈希函数把输入x映射到一个bitset上,然后对这个bitset进行考察。考虑bitset长度为4,那么出现0001这样的结果的概率是1/16,也就是说平均要抛16次才能得到。在对数字的二进制表示进行采样的过程中,我们认为有一半的数字是以1开头的,另一半是以0开头的。同理,有1/4的数字是以01开头的,1/8以001开头的。那么在一个随机流中,我们恰恰发现一个001开头的,那么至少这个集合有8个元素。
进行推广,如下所示。考虑长度为L的bitset,那么前k-1项都为0,而第k项为1的概率,根据二项分布是$1/2^k$。因此可以通过统计bitset中第一个1出现的位置来估算数量。具体来说,我们把一批元素通过哈希函数映射成一系列bitset并放入一个桶里面,然后统计整个过程中,每个哈希值中第一个1出现的最大值(越往左越大)。我们假设最左端是第1位,那么假如第一个1出现的位置的最大值是在第$m$位,那么集合中就有$2^m$个元素。
1 | m |
为了提高精度,实际上可以使用多个桶而不是一个桶来进行统计。Redis使用了一个分桶的技巧,也就是说给定一个序号$b$,将bitset中小于$b$的所有位数bitset[0..(b-1)]决定桶的序号,剩下的部分用来就是做那个伯努利过程。那么最终就能够得到这$2^b$个桶中第$i$个桶的预估元素个数$2^{m_i}$。
如何从这多个桶的输出结果中总结到最终结果呢?HLL使用调和平均数来计算。令$B = 2^b$,表示总的桶数。那么计算$A$就是平均每个桶里面的元素个数。
$$
A = \frac{B}{\sum_{i=1}^{B}{2^{-m_i}}} = \frac{B}{\sum_{i=1}^{B}{ \frac{1}{2^{m_i}} }}
$$
那总元素的个数就是$AB$。
在实际操作的时候,发现有一个问题,例如有的桶直接就是0,也就是说没有出现一个1,对这种情况我们如何处理呢?或者说,我们认为这表示这个集合的值是比001这样的小还是大呢?我觉得,其实应该认为这个集合是**远远大于001**的,事实上集合的大小至少应该等于10...0(共有len(bitset)个0)。形象一点,这里都是0的原因是因为真正的1其实还在更前面!所以在计算的时候,0...00和0...01表示的值之间就会存在一个很大的落差,不知道我理解是否正确。
最后,我们得到的$AB$其实不准确,还需要进行修正。
Redis的HLL的基本结构
1 | struct hllhdr { |
encoding
它的取值是HLL_DENSE和HLL_SPARSE,分别对应Dense存储模式和Sparse存储模式,这两个存储模式是Redis的HLL实现的一个精妙的部分,用来节省存储空间。此外,在内部还会有一个HLL_RAW的模式,这个只在pfcount上用到,并且不对外暴露。后面详细介绍这两个结构。registers
一个Flex数组,即上面提到的bitset。因为Sparse存储模式一开始用的空间很少,所以我们的数据也是弹性分配的。
Dense和Sparse结构
Dense模式就是经典的HLL算法,其中registers大概占据了12KB的大小。容易看到,这个空间占用还是比较大的,考虑到这里面大多数都是0,所以Redis又使用了Sparse模式。
Sparse模式是创建时默认的,实际上不会占用12KB的大小,主要用来表达连续多个桶的值为0的情况,也就是用CPU换存储。它使用下面三种编码方式,称为opcode:
- XZERO:格式为
01xxxxxx yyyyyyyy
这个能表示最多的0形态。初始化之后,因为一个数都没有加入HLL中,就使用XZERO,占用两个字节。
前面的6个x叫Most Signigicent Bits(MSB),后面8个y叫Least Significant Bits(LSB)。这14位组合起来可以表示16384个0,这也对应了后面提到的HLL_SPARSE_XZERO_MAX_LEN这个宏的取值,刚好等于HLL_REGISTERS的值。 - ZERO:格式为
00xxxxxx
ZERO能表示的0比XZERO要少,但只占用一个字节,所以能表示较少的0。
表示xxxxxx+1个0,所以实际上能够表示最多64个0。 - VAL:格式为
1vvvvvxx
当HLL开始进一步稠密时,就可能出现VAL这种情况。
5个v表示重复的计数值。注意,如果vvvvv为0,说明计数值是1。如果我们需要表示0的情况,就直接用XZERO和ZERO了。
2个x表示重复的桶的数量,也就是说有连续xx+1(<4)个桶的值都是vvvvv+1(<32)。 - 变换为Dense
注意,当VAL也无法描述时,例如:- 某一段重复的桶的数量超过4了,那么就要变换为Dense。
- 出现超过32的值之后,就会切换为Dense模式。
HLL的空间占用
1 | // hyperloglog.c |
先说一下这几个常数:
HLL_P
桶的数量,默认值14。P越大,计算得越精确。HLL_Q
用来做伯努利过程的尾数。HLL_REGISTERS表示有多少个桶
如果默认值14,则可以构成16384个桶(对应到hllhdr中的registers)。HLL_P_MASK
可以通过&来取出实际桶的序号。
所以Dense的实际排布是1
| Q bits of hash | P bits of register index |
HLL_BITS
每个桶的大小,这里是6bit。为什么不是8bit,正好一个bytes呢?因为2**6是64,可以用来表示63个0了。
不过我觉得最多只有50个0。首先,我们得到的是64位的哈希,然后其中有14位被用来分桶了,那剩下最多还能表示64-P+1=51位的count(参考“pfadd的Dense实现”的实验),而这个是最少需要6个bit来表示的,所以这里用了6bit而不是8bit。不过这样会不会因为内存不对齐从而产生开销呢?
当然,这里用6bit,实际上会给定位某个桶带来麻烦。可以查看hllDenseGet和HLL_DENSE_GET_REGISTER。
另外,我们还可以计算得到,Dense情况下HLL的大小为6bit*16384=12KB。
createHLLObject实现
由于创建的HLL结构中每个桶的值都是0,所以默认肯定是Sparse存储省空间。所以要手动构造一下Sparse结构。首先分配sparselen的空间,包括:
HLL_HDR_SIZE也就是HLL头部的大小- register的空间
它的值是
$$
\frac{(HLL\_REGISTERS+(HLL\_SPARSE\_XZERO\_MAX\_LEN-1))}{HLL\_SPARSE\_XZERO\_MAX\_LEN} * 2
$$
这个公式看起来很奇怪,但是$\frac{X + (Y-1)}{Y}$实际上是向上取整的常规操作,所以说实际上要做的就是算出
$$
\lceil \frac{HLL\_REGISTERS}{HLL\_SPARSE\_XZERO\_MAX\_LEN} \rceil * 2
$$
所以这就好理解了,总共有多少个桶,然后除以每个XZERO opcode能放存多少个桶,最后乘以2,因为每个XZERO占用两个bytes,这就是要给这个Sparse结构分配多少内存。而一个HLL_SPARSE_XZERO_MAX_LEN能表示16384个桶,这在上文已经讲解过了,刚好等于HLL_REGISTERS的值,因此实际上一开始所有register用两个bytes就完全可以cover了。
做个实验,打印下来发现sparselen为18,HLL_HDR_SIZE是16,所以确实一开始register只用了两个字节。
1 | robj *createHLLObject(void) { |
分配完空间,下面就是要初始化,具体做法就是调用HLL_SPARSE_XZERO_SET每两个字节set一下。
1 | ... |
可以看到,实际上HLL是一个String对象。Redis中的String是可以存储二进制序列的,而不局限于是字符串。
1 | ... |
pfadd实现
如果没有,就新创建一个HLL对象
1 | // server.c |
否则,调用dbUnshareStringValue确保对象o能够被原地进行修改。
1 | ... |
根据dbUnshareStringValue的注释,一个对象是可以被修改的,除非:
- 它是被shared的,即refcount > 1
- 它的encoding不是RAW
如果有对象是满足上面两个条件的,那么会存入这个string对象的一个unshared/not-encoded的副本,否则直接返回这个对象o。我们可以查看下面的实现。
1 | robj *dbUnshareStringValue(redisDb *db, robj *key, robj *o) { |
下面就是对于所有要添加的项目调用hllAdd,这和前面的zaddGenericCommand等命令很相似。
1 | ... |
下面的话同样会调用signalModifiedKey和notifyKeyspaceEvent进行通知,参考之前的讲解。有趣的是这个HLL_INVALIDATE_CACHE,它涉及了cache的机制,我们将在稍后讲解。
1 | ... |
下面的是主要的hddAdd实现,主要分为Dense和Sparse两种
1 | int hllAdd(robj *o, unsigned char *ele, size_t elesize) { |
pfadd的Dense实现
hllDenseAdd
hllDenseAdd函数主要在HLL结构中“插入”一个元素,事实上并没有什么元素被加上,只是说在需要的时候自增一下这个哈希值所属的max 0 pattern counter。
首先,通过hllPatLen计算ele的哈希,并从哈希值获得桶的序号index,并且把这个哈希值里面第一个1出现的位置count返回(具体含义见下面说明,这里难以理解的是到底从左边数还是从右边数。。。)。需要注意的是,我们并不需要实际的哈希值。
1 | int hllDenseAdd(uint8_t *registers, unsigned char *ele, size_t elesize) { |
为了更方便进行调试,我们将createHLLObject中新对象的创建默认改为HLL_DENSE,并加上一系列调试语句,来观察行为。
1 | void format_binary(uint64_t x, char *buf) |
但是单纯这样改会有问题,当第二次调用pfadd时会报错WRONGTYPE Key is not a valid HyperLogLog string value,原因是下面的语句检查不通过。
1 | int isHLLObjectOrReply(client *c, robj *o) { |
所以比较好的做法是在createHLLObject最后直接调用hllSparseToDense(o),让它从Sparse转成Dense进行研究。
hllPatLen
查看hllPatLen的实现。首先,它基于MurmurHash64A算得哈希值hash,并且得到所在的桶(register)的编号index。容易知道,这个index的取值是在[0, 2**HLL_P=16384)之间的,这也对应了桶的数量。
1 | /* Given a string element to add to the HyperLogLog, returns the length |
接着,将表示桶的P位mask出为index,并开始对剩下的64-HLL_P=50位进行原始的HLL算法。
首先,将hash右移HLL_P位,去掉register index。然后将最高位设为1,这样的话返回值count最大为Q+1,也就是51。这样做的目的:
- 顺应了前面提到的全是0的情况。
- 防止后面死循环。
1 | ... |
从第HLL_REGISTERS位开始计算0的数量,也就是从低位往高位找,最多找到64-P+1=Q+1位。我们令bit为1,然后从右往左扫,直到看到第一个1为止。根据注释,是结尾的1也要被算在计数里面,例如”001”的count是3;count的最小值是1,此时没有前导0。
可以看出这里和HLL的原算法还是有点不同的,原算法是找leftmost 1,而现在的实现是找rightmost 1。这个循环看上去很没有效率,但在平均情况下在很少的迭代之后就能找到一个1。
1 | ... |
Demo
pfadd p1 a中添加了一个元素,返回count为2。实际输出1。
1 | Raw hash 101001111010010010001110000101010011011010000111011000110100111 |
接着运行pfadd p1 b c d e f h i0 i1 i2,现在有10个元素,返回count为5。实际输出10。
1 | Raw hash 110100001100001000111001011000101111000000001000000001111010000 |
hllDenseSet
下面再来看hllDenseSet的实现,它应该就是根据hllPatLen计算的结果更新对应桶的值了。hllDenseSet是一个一个底层的函数,用来设置Dense HLL register。将index处的值设为count,如果count比当前值大。
registers应该能够容纳HLL_REGISTERS+1的长度,这个是由sds的实现来保证的,因为sds字符串始终会在最后自动加上一个’\0’。
这个函数始终会成功,返回1表示发生了修改,否则返回0。
1 | int hllDenseSet(uint8_t *registers, long index, uint8_t count) { |
逻辑很简单,就是先把老的oldcount读出来,如果count比较大,那么就更新,比较麻烦的就是这两个宏。
首先是HLL_BITS,它的取值是6,为什么这么奇怪呢?先前说到这是出于压缩空间的考虑。所以HLL_DENSE_GET_REGISTER做的就是从数组p中找到第regnum个register(桶)。方案也很简单,可以算得这个桶在第几个byte。然后从这个byte开始读6个bit,其中可能还会读到后一个byte上。
1 | /* Store the value of the register at position 'regnum' into variable 'target'. |
pfadd的Sparse实现
几个宏
1 | // xzero类型前缀 01xxxxxx |
下面的三个宏用来判断类型
1 | // 0xc0=0x11000000 判断是否是zero类型 |
下面的几个宏,对于XZERO和ZERO,是取出它表示有多少个0;对于VAL,还需要获得VAL的值,以及对应VAL的个数。
1 | // 00xxxxxx & 0x00111111 获得后6位的值,即zero的长度 |
下面的几个宏给出每个op对应的数值范围,为什么取这些值之前已经介绍过了。
1 | // spase值5bit最大32 |
下面几个宏是用来写入VAL、ZERO和XZERO的
HLL_SPARSE_VAL_SET
这是通过移位进行拼装。
为什么是(val)-1而不是val呢,回想之前说过VAL为0的时候表示VAL为1而不是0,有0个的情况直接用ZERO和XZERO表示。1
2
3
*(p) = (((val)-1)<<2|((len)-1))|HLL_SPARSE_VAL_BIT; \
} while(0)
hllSparseAdd
hllSparseAdd的实现还是需要先通过hllPatLen来获得count和index。
1 | int hllSparseAdd(robj *o, unsigned char *ele, size_t elesize) { |
hllSparseSet
hllSparseSet是一个贼复杂的函数,作用是将第index个register的值设置为不小于count。参数o是用来存储HLL的String对象,这个函数需要一个可变引用(指针),从而在需要的时候扩容。
返回值:
- 当集合的cardinality发生变化后,函数返回1。
- 返回0,表示没有实际更新。
- 返回-1表示错误。
另外一个副作用是使得HLL从Sparse表示变为Dense表示,这个通常发生在某个值不能通过Sparse格式表示了(参考之前对VAL表示方法的论述),或者结果集的大小超过了server.hll_sparse_max_bytes。
不过,在createHLLObject创建HLL时,却不会判断server.hll_sparse_max_bytes为0的时候就直接Dense,此外,还有个HLL_SPARSE_VAL_MAX_VALUE阈值。
1 | int hllSparseSet(robj *o, long index, uint8_t count) { |
后面讲到,我们先得在这里为最差情况(XZERO变为XZERO-VAL-XZERO)额外分配3个字节。这个必须要现在做,因为sdsMakeRoomFor可能realloc,也可能malloc,但这两种都不保证返回的ptr不会变化。而我们希望以后的o->ptr能够是不变的。
1 | ... |
下面是第一步,先定位到sparse的头sparse,也就是registers数组,和尾end。目的是定位到需要修改的opcode,从而检查是否真的要修改。
下面这个大循环,主要就是从头遍历,先通过HLL_SPARSE_IS_宏判断是具体哪种op类型,然后前进对应的oplen和span。
在上面的while循环结束后,我们维护了下面几个性质:
first储存了当前的opcode所覆盖的第一个register,注意这里的register对应了Dense里面桶的概念,而不是表示一个uint8_tnext和prev分别存储了后一个和前一个opcode,如果不存在前驱后继,对应值是NULLspan表示当前opcode覆盖了多少个register,也就是跨过了多少个相同的数字oplen表示这个op实际长度是多少个byte,根据前面对ZERO、XZERO和VAL的定义,其实取值只会在1和2p指向了当前的opcodeindex表示要哈希到哪个桶里面
1 | ... |
现在,我们找到了包含index的那个op了,判断这个op的类型,并且计算runlen。也就是这个opcode表示有多少个0或者VAL,对应的诸如HLL_SPARSE_ZERO_LEN宏之前也讲过了。
1 | ... |
在得到类型后,我们需要进行分类讨论。
首先是VAL的两种平凡情况,尝试进行原地修改。
- 如果这个VAL opcode所表示的
count大于现在这个哈希产生的count,那么实际上并不需要进行更新
在这种情况下PFADD会返回0,因为没有发生任何更新。 - 特例。如果这个VAL opcode仅仅就覆盖了一个register,那么就仅直接进行更新
我们稍后会去具体查看updated的具体实现。
相对的不平凡的情况就是这个VAL opcode覆盖了多个register,也就是有相邻的多个桶都是这个count,可想而知,需要把这个register切出来单独做一个VAL opcode,实现稍后分析。
1 | ... |
然后是数量为1的ZERO平凡情况。如果是0,并且只覆盖了一个register,同样直接进行更新。注意这里对这个函数的调用是HLL_SPARSE_VAL_SET(p,count,1)。count被传给了形参val,而不是语义上更接近的len。这表示在p处有连续1个桶,它的值为count。
1 | ... |
下面是较为复杂的普通情况。opcode要不是VAL,要不是len大于1的ZERO,要不就是XZERO。
这些情况特殊在需要将原来的opcode拆分为多个opcode。其中最坏情况要把XZERO拆分成XZERO-VAL-XZERO的结构,也就是在原来的XZERO范围中有一个register被hit了。这个变化会占用5个字节,比原来多3个,也就是我们前面提前分配3个字节的原因。【Q】如果最后发现这3个字节不需要的话,会回收么?如果不会回收的话,每次访问这个opcode,会不会导致每次都会尝试多分配3个?其实sdsMakeRoomFor是对当前实际使用的长度len而言的,而不是每次都增加capacity。
下面就是先将新序列写到n里面,然后将n原地插入到旧数组中。创建一个长度为5的buf即seq,保证不会溢出。
首先处理ZERO和XZERO这块,这个处理主要就是将它分为Z-VAL-Z的序列,其中Z可能是ZERO可能是XZERO。具体查看代码中的注释。
1 | ... |
下面是分割VAL的情况。我们也是在n上面进行修改。把除自己之外的设为curval,自己设置为count。
1 | ... |
下面将n插入到老序列里面,其实就是一个memmove。
1 | ... |
下面,来看updated的实现,这一块代码,主要是从处理VAL和ZERO的两个goto过来,以及通常情况的顺序执行过来。
1 | ... |
下面是promote流程,是比较直截了当的,也就是先hllSparseToDense转换到Dense,然后调用hllDenseSet。注意这也反过来意味着PFADD命令需要保证被广播到slaves和AOF中,从而保证slaves中也进行这个转换。
1 | ... |
pfcount实现
pfcountCommand函数
照例是pfcountCommand作为入口。
首先是处理PFCOUNT给出多个key的情况,此时会返回将这些HLL做union之后的近似cardinality。
1 | /* PFCOUNT var -> approximated cardinality of set. */ |
下面的情况是处理一个HLL的cardinality。
1 | ... |
假如可以使用cache,那么就直接使用cache去组装card。可以看出低字节在数组的低index中,所以是按照小端存储的。【Q】为啥不直接放一个uint64_t,而是要自己用uint8_t去维护一下?难道仅仅是为了在高位留一个字节表示是否是valid的?那其实可以用位域来实现啊?
1 | ... |
假如cache是无效的,那么会实际调用hllCount。hllCount有个invalid参数,表示这个HLL的结构是有问题的。
1 | ... |
在下面,同样需要调用signalModifiedKey。这是因为虽然PFCOUNT不会修改实际的存储,但是它可能会修改cache值。考虑到HLL实际上是作为String来存储的,所以我们需要广播这个变化。
1 | ... |
cache实现
在先前可以看到,HLL结构有个card[8]字段用来缓存cardinality。这个card会在PFCOUNT被访问到。此外,在PFADD和PFMERGE操作中,会调用HLL_INVALIDATE_CACHE使得缓存失效。
1 |
hllCount函数
返回估计的cardinality,基于register数组的调和平均数。hdr指向持有这个HLL的SDS的开始位置。如果HLL的Sparse疏表示形式是不合法的,则设置invalid为0,否则不设置这个值。hllCount支持一种特殊的内部编码HLL_RAW,也就是hdr->registers会指向一个长度HLL_REGISTERS的uint8_t数组。这个有助于加速对多个键调用PFCOUNT,因为我们不需要处理6bit的整数了,所以实际上这是一个空间换时间的方案。
1 | uint64_t hllCount(struct hllhdr *hdr, int *invalid) { |
下面计算每个register的直方图。注意到直方图数组reghisto的长度最多是HLL_Q+2,因为HLL_Q+1是哈希函数对"000...1"这样序列所能返回的最大的frequency。当然,很难检查输入的合法性,所以不如分配reghisto就直接大一点。
1 | ... |
下面是HLL_RAW这个特殊的encoding。
1 | ... |
在这个操作之后,我们得到了直方图reghisto[reg],表示在所有HLL_REGISTERS个桶中,count为reg的桶的数量,而这个count表示第一个1出现的位置。即之前的while end bit 10000 count 5这样的内容。
下面就是根据直方图来计算估计的数量。我们设计了一个很naive的naiveHllCount,即基于调和平均数的多桶的实现方案,而这里用了一篇很屌的论文里面的一个很屌的做法。
一个naive的count函数
下面我们根据自己的理解实现一个count函数。
1 | double naiveHllCount(int * reghisto) { |
实际运行下来,对于pfadd p1 a的结果是
1 | v 37 countofV 0 bucketCount 68719476736.000000 delta 0.000000 |
修正
有个修正来自于论文中,知乎给出了解释。参考
1 | switch (p) { |
牛逼做法
1 | // 续hllCount |
1 | // New cardinality estimation algorithms for HyperLogLog sketches |
hllDenseRegHisto
hllDenseRegHisto会根据HLL_REGISTERS == 16384 && HLL_BITS == 6的通用情况进行优化,我们对这个优化暂时按下不表,只关注实际在做什么。可以看到,它实际上去遍历了所有的register,然后通过HLL_DENSE_GET_REGISTER把这个HLL_BITS=6位的register取出来,并增加这个register的数量。
1 | void hllDenseRegHisto(uint8_t *registers, int* reghisto) { |
hllSparseRegHisto
hllSparseRegHisto对Sparse情况进行统计。这个实现其实也很简单,遍历每个opcode,对于ZERO和XZERO就增加reghisto[0],对于VAL就增加reghisto[val]。
1 | ... |
intset
intset是存储int的集合。在底层存储上体现为一个有序的数组,这是它和ziplist的一个不同点。intset数组中的每个元素具有相同的长度,这个长度由encoding指定。length表示Intset里面元素的个数,所以柔性数组(Flex Array)contents的长度实际上就是encoding * length的值。
1 | // intset.h |
encoding
类似于HLL的实现,intset也要考虑节省空间。
出于节省空间考虑,支持三种encoding,当出现该encoding装不下的数时,会新创建一个更大的encoding,当然这样会伴随空间浪费。
1 |
给定v的值,得到能够承载它的最小encoding。需要注意的是,这里都是有符号整数。
1 | static uint8_t _intsetValueEncoding(int64_t v) { |
编码
因为支持不同的编码,所以intset索性用一个int8_t contents[]来存这些int。如果我们要把一个64位数字按照8位8位地存到char数组里面,那么就会涉及到选择大端或者小端两种存储方式。其实在Redis的很多数据结构的实现中,我们可以明显地看到Redis开发者,或者很多C开发者的一个特点,也就是喜欢把所有的数据结构都自己编码到char*上面。intrev32ifbe这个函数用来从小/大端序转为小端序。
1 |
查找
intsetFind语句首先排除掉encoding过大的,比如在一串最大32767的数组里面肯定找不到99999。
1 | /* Determine whether a value belongs to this set */ |
下面就是intsetSearch,因为intset是有序的嘛,所以我想这个肯定是个二分的实现吧,果不其然。这个函数返回1表示找到,并用pos标记找到的位置/插入位置;否则返回0
在二分前,需要先特判一下value过大或者过小的情况,从而能够快速失败,而不是进入下面的二分。
1 | static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) { |
这里的二分每次都会对mid进行+1或者-1,和我们通常的二分还不太一样。通常的二分因为要在一个F/T…TTT或者TTT…F/T型的序列中找到边界的T,所以在移动mid时,如果我们发现当前的mid是T,并且我们想移动l/r的话,我们不能移动到mid-1/mid+1,这是因为mid可能就是我们要找的值。但这个二分我们要找的是exact value,所以我们可以激进一点,直接-1或者+1。
1 | ... |
添加
对于intsetAdd的情况,想想肯定是有一个$O(logn)$的查找和一个$O(n)$的移动的。
1 | intset *intsetAdd(intset *is, int64_t value, uint8_t *success) { |
Resize走的zrealloc,这个函数之前讲到过,并不保证不会重新分配内存,这也是为什么intsetResize会重新返回intset *指针的原因。
1 | static intset *intsetResize(intset *is, uint32_t len) { |
intsetMoveTail实际调用了memmove,直截了当的函数。
1 | static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) { |
这里就是先把64位的value放上去,如果机器上是大端(be)存储,那么再调用下面的宏倒成小端。
1 | static void _intsetSet(intset *is, int pos, int64_t value) { |
大端小端宏
简单介绍一下memrev系列大小端转换的代码。
16的简单,3次交换
1 | void memrev16(void *p) { |
32位的,6次交换,实际上是轴对称交换
1 | 0 1 2 3 |
代码如下
1 | void memrev32(void *p) { |
64位的,12次交换,同样也是轴对称交换,代码就不列了。
bitmap
bitmap底层是一个SDS
count实现
这个命令可以统计得到从[start, end]区间内的1的数量,但是这个start和end是以byte为单位的,从0开始。我们可以参考下面的这个demo
1 | setbit test1 10 1 |
下面两个命令返回值都是3
1 | bitcount test1 |
其实bitmap底层是从左到右开始编号的。乍一看有点本末倒置,为啥最高位是0,但仔细想想,这种方式方便扩展啊。
1 | byte offset : 0 1 2 3 |
再举一个例子
1 | setbit test2 15 1 |
计算15/8=1.875,所以是位于第1个byte的最后一位
1 | 00000000 00000001(15) |
因此getbit test2 0 0 返回0getbit test2 0 1 返回1,因为第一个byte被包含了getbit test2 2 3 返回0
‘
下面看bitcountCommand
1 | // bitops.c |
上面一堆废话结束,最关键的是redisPopcount这个函数,统计从s开始的bytes长度的slice里面的1的个数。
一开始发现一个表bitsinbyte,这里面bitsinbyte[i]表示i这个数字的二进制表示里面有几个1。可以从中看出,bitcount统计bytes而不是统计bits的原因可能很大程度上就是对bytes可以查表处理,起到加速作用。
1 | /* Count number of bits set in the binary array pointed by 's' and long |
下面的代码中(unsigned long)p & 3的目的是用一个while循环统计下前面没有对齐到32位的数量。其实如果我们愿意慢一点,直接这个while循环就能全部统计完了。
1 | ... |
一次性计算 28 个 bytes,这个算法经历过疯狂的升级,3.0 的时候是同时计算 16 个,但总体来说还是一个 SWAR 算法。为了便于理解,先看 3.0 版本的 16 bytes 的算法,它其实有点类似于在 GeoHash 中看到的 interleave64 的算法。快速计算 64 位和 32 位整数二进制表示中 1 数量的算法是种群算法,我在csapp data lab这篇文章中有介绍。这篇文章 中的介绍也很详细。此外,gcc 提供了对于不同长度类型计算 1 的数量的 __builtin_popcount 的系列内置函数。
1 | //for 64 bit numbers |
我们以32位为例,复习一下该算法的原理。首先回顾一下这几个常量的表示,F实际上是01的重复,T是0011的重复,O是00001111的重复
1 | F = 0x55555555 = 01010101010101010101010101010101 |
这个算法的思路是首先把32位长度的数组按照奇偶组合成16组,然后在每组中统计1的个数,容易看到,这个结果只能是0b0/0b1/0b10,不会溢出。
1 | 数字 01 11 01 01 10 11 11 00 11 01 00 01 01 01(123456789) |
这个过程是可以用位运算解决的,即
1 | i = (i & 0x55555555) + ((i >> 1) & 0x55555555); |
然后我们发现,为啥函数里面不是这样写的?其实下面两种是等价算法
1 | i = (i & 0x55555555) + ((i >> 1) & 0x55555555); |
一般来说,& 对 + 是不满足分配率的,但在对按4移位的情况下是可以的,即不会产生溢出。所以后面我们还可以提出 0x0F0F0F0F公因式。注意对 2 移位是不能提公因式的,考虑 1010b 这种情况,移位相加会出现 10b + 10b 从而导致溢出。
下面我们来对照看看3.0版本的16 bytes的实现,在前面执行NumberOfSetBits32的A步骤,依次计算4个byte的数量到aux1/2/3/4里面。在最后执行B步骤,将最后结果加到bits里面。
1 | p4 = (uint32_t*)p; |
下面看28 bytes算法也是类似,不过为啥要选择28这个数呢,我不是很明白
1 | ... |
这个循环和之前的(unsigned long)p & 3循环是对应的,用来处理余下来和28个bytes不对齐的。
1 | /* Count the remaining bytes. */ |
set/get实现
1 | /* SETBIT key offset bitvalue */ |
下面这个命令,进行检查,该创建的创建,该扩容的扩容
1 | ... |
bitop
bitop指令的格式如下面所示,结果存到dest里面。
1 | bitop opname dest src1 src2 ... |
1 | /* BITOP op_name target_key src_key1 src_key2 src_key3 ... src_keyN */ |
在字符串判定的时候有个优化,因为strcasecmp的开销比较大,所以会先判断第一个字母合不合法,合法再调用这个函数。
1 | ... |
遍历所有要查找的key,统计一些信息:
- objects
调用getDecodedObject。因为这个是raw encoding,所以相当于就是自增了一下引用。 - src
每一个src的指针 - len
每一个src的对应长度,这个长度是按照字节算的 - maxlen/minlen
所有src的最大长度和最小长度
1 | ... |
比较有趣的是这里同样针对对齐数据有个优化。我们需要在ARM架构上跳过这个优化点,这是因为ARM不支持multiple-words load/store,即使在V6架构下。
首先,解释一下几个临时变量:
- j
表示SDS里面的每一个字节 - i
表示op作用的每一个key
出于从普通到特殊,可以先阅读后面的普通实现,再看这个优化实现。
优化实现能够处理最短的bitmap至少有4个long(32位)的情况,但是要求key的总数小于等于16。也就是说我们能够一批4个地对所有的key做bitop。【Q】不过不需要什么特殊的指令,直接这样写CPU就可以优化了吗?
1 | ... |
专门提取第一个出来作为左操作数,下面i从1开始循环
1 | ... |
这里我有个疑惑了,既然里面都不处理BITOP_NOT了,为啥不直接跳过这个for循环呢?
1 | ... |
下面是清理工作了
1 | ... |
quicklist
Geo和GeoHash
Redis在3.2版本之后提供GeoHash的实现,主要包含下面的命令:
GEOADD key longitude latitude member [longitude latitude member ...]
将某个经纬度以及对应的名字(member)加入到指定的key里面GEOPOS key member [member ...]
以member为输入,返回经纬度为输出GEODIST key member1 member2 [unit]
返回两个位置之间的间隔,以unit为单位,默认为米GEORADIUS key longitude latitude radius unit
返回给定经纬度为中心radius范围内的位置,默认返回未排序的元素GEORADIUSBYMEMBER
同上,但是不是给出经纬度,而是直接给一个member名字GEOHASH ley member [member ...]
返回member的GeoHash值ZREM
用来删除一个GEOHASH对象
GEOADD
对应GEOADD指令。
可以看到,Geo的底层存储是一个ZSET。这也是可以理解的,因为通过GeoHash确实可以实现有序的地理坐标,所以我们是按照顺序存储的。
1 | /* GEOADD key long lat name [long2 lat2 name2 ... longN latN nameN] */ |
在这里构建将来**提供给zadd命令的argc和argv**。elements表示坐标的数量,一个坐标需要有(long, lat, name)三元组来表示,所以这里要除以3。
1 | ... |
这里自增argv[1]的引用计数是因为直接把argv[1]指向c->argv[1]了,所以实际上也是自增c->argv[1]的引用计数。实际上这么做同时也保证了replaceClientCommandVector在释放掉c->argv后,c->argv[1]所指向的对象仍有一个引用。
1 | ... |
在这个语句之后,我们得到Step 1: argv[1]->refcount 2, c->argv[1]->refcount 2。
下面的循环依次解析每个坐标,并构建score和member字段。
首先通过extractLongLatOrReply把经纬度读到xy里面,如果出现经纬度超出范围的问题函数会返回C_ERR,从而导致直接return。
1 | ... |
下面的geohashEncodeWGS84函数根据我们取出来的xy算GeoHash,最后会调用到geohashEncodeType -> geohashEncode,关于GeoHash部分会在后面讨论。
1 | ... |
geohashAlign52Bits函数能够将得到的哈希值GeoHashBits,其中hash.bits是哈希值,hash.step是精度。我们需要将它做成一个52位的整数。
1 | // geohash_helper.h |
接着来看函数geoaddCommand,我们将得到的bits组装成SDS,并且安装到argv里面,接着**调用replaceClientCommandVector得到一个以argc和argv为参数的新的redisCommand**,放到c->cmd里面。
1 | // 续geoaddCommand |
在这之后,输出是
1 | Step 2: argv[1]->refcount 2, c->argv[1]->refcount 2 |
replaceClientCommandVector
replaceClientCommandVector函数会释放c->argv和c->argc,并且使用传入的argc和argv替换。
1 | // networking.c |
freeClientArgv
查看freeClientArgv
1 | static void freeClientArgv(client *c) { |
lookupCommandOrOriginal
lookupCommandOrOriginal用来根据指令名name找到对应的redisCommand项目。首先会在server.commands里面找,如果没找到会在server.orig_commands里面找。orig_commands表示没有被redis.conf里面的rename命令修改过的原始的命令名字。看起来很奇怪,不过人家注释也说了lookupCommandOrOriginal一般只和lookupCommandOrOriginal配合使用。
1 | /* This is used by functions rewriting the argument vector such as |
GEOHASH算法介绍
GEOHASH是将二进制的经纬度转换为字符串,每个字符串表示一块矩形的区域。这些字符串越长,那么表示的范围就越精确。
下面阐述如何计算GEOHASH:
- 如何编码精度或者纬度
例如纬度的范围是[-90,90],那么我们不断二分就可以得到一个二进制的表示。例如00表示[-90,-45),11表示[45,90]。 - 如何组合精度和纬度
通过interleave来组合。也就是偶数位放经度,奇数位放纬度。 - 如何生成字符串
我们组成的GeoHash有52位,通过Base32编码(一个char能表示5位)可以得到长度为11的字符串。
这种interleave的组合方式成为Peano空间填充曲线。如下所示,这个曲线可能存在编码相邻但是实际距离很远的情况,例如0111和1000。因此,在通过GEOHASH召回部分空间点后,还需要去判断一下实际距离。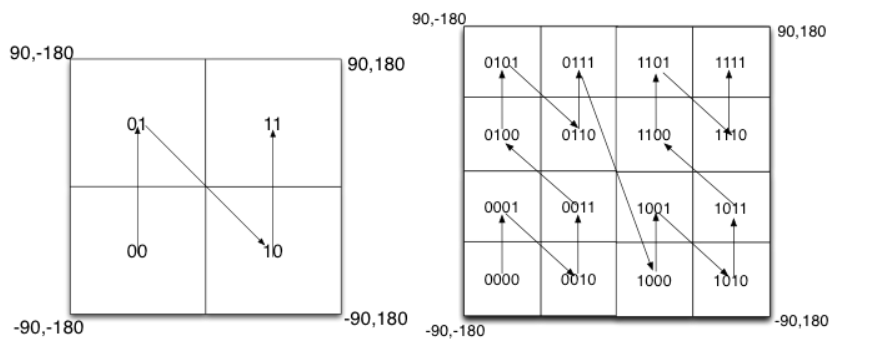
GEOHASH实现
GeoHashBits/geohashGetCoordRange
GeoHashBits是GEOHASH结构。bits表示hash值,是interleave64之后的结果。step表示进行二分的次数,Redis中默认是26,所以最终得到的hash是52位的。
1 | typedef struct { |
下面四个宏规定了经纬度的取值范围。在这里需要说明的是Redis的GeoHash的内部存储和标准有差异。标准规定纬度的取值范围是[-90, 90],而Redis的实现是[-85, 85]。因此Redis实际上是不能索引位于南北极的一小块范围的。
【Q】为什么这么做呢?我觉得可能有两个原因:
- 南北极的位置本来也不常用
- 南北极的经度变化比较敏感,所以其实有点浪费
1 | /* Limits from EPSG:900913 / EPSG:3785 / OSGEO:41001 */ |
我们回顾之前看到的geohashEncodeWGS84的函数的调用链,它会通过geohashGetCoordRange来获得这次经纬度的范围,并作为参数传给geohashEncode。
1 | // geohash.c |
geohashCommand
查看geohashCommand的实现,它主要是通过geohashEncode去得到一个GeoHashBits对象。
1 | void geohashCommand(client *c) { |
首先通过zsetScore获得指定member即c->argv[j]->ptr的score。
1 | ... |
在前面提到过,Redis的GeoHash的内部存储和标准的GEOHASH坐标有差异。Redis的是[-85,85]这个区间,但是普通的GEOHASH是[-90,90]区间。因为这个命令会返回标准的GEOHASH值,所以我们需要将它转换到标准GeoHash。
因此需要用decodeGeohash将score解码到xy,并且再通过GeoHashRange编码,得到纬度取值范围为[-90, 90]的hash。
1 | ... |
下面我们得到了符合标准的hash,接下来我们将这个hash值根据geoalphabet编码到字符串buf上。
1 | ... |
geohashEncode
下面我们来看最关键的geohashEncode的实现。
首先是进行校验,包含两部分。首先检验经纬度Range是否合法,然后校验经纬度是否在GEO_宏规定的区间内,然后校验经纬度是否在经纬度Range给出的区间内。
【Q】在这里有一个问题,从上面的代码实现可以看到,其实lat_range是可能比GEO_LAT_MAX/GEO_LAT_MIN范围大的,那么这是否影响GeoHash的结果呢?
1 | // geohash.c |
longitude和latitude既要满足GEO_宏定义的区间限制,也要满足传入的long_range和lat_range区间限制。
1 | ... |
下面计算的两个offset,实际上就是根据传入的long_range和lat_range做min-max归一化。
1 | ... |
接着对归一化的结果,乘以$2^{step}$
【Q】这是为什么呢?这里的两个offset是无量纲的比例。我们乘以(1ULL << step)相当于就是先把地图分step次,然后找到对应的offset在的位置。所以在读取GeoHash的时候,实际上是需要知道对应的step的。我们参考geoaddCommand里面的调用是geohashEncodeWGS84(xy[0], xy[1], GEO_STEP_MAX, &hash)。
1 | ... |
接下来就是GeoHash算法的一个核心,也就是将得到的两个offset,按照奇数为纬度,偶数为经度的方式组成一个二进制序列。
1 | ... |
下面我们来看这个interleave64的实现,他看起来就像一个拉链一样,交错。
1 | /* Interleave lower bits of x and y, so the bits of x |
我们不妨以一个32位的0xffff进行调试。
1 | x (ffffffff)11111111111111111111111111111111 |
GEORADIUS/GEORADIUSBYMEMBER
GeoHashRadius类
这个类是一个非常大的上下文,包含了一个GEOHASH位置本身,以及他解码后实际的经纬度,以及它的八个邻居的GeoHashBits。
1 | typedef struct { |
GeoHashBits之前介绍过,包含哈希位bits和精度step,也就是一个GEOHASH地址,表示一块区域。
GeoHashArea的定义如下所示,它实际上就是对hash值的一个经纬度的表示,可以由geohashDecode算得。
1 | typedef struct { |
GeoHashNeighbors表示周围八个区域。
1 | typedef struct { |
georadiusGeneric函数
在很多应用中有查找附近的人这样的功能,这就可以通过GEORADIUSBYMEMBER命令来实现。
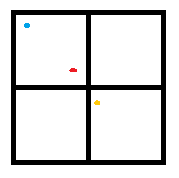
【Q】在启用了GEOHASH之后,两个hash值越接近,说明两个点距离越近。所以说,这个函数是不是可以直接匹配前缀呢?答案是不行的,因为这样会漏掉跨边界的情况。如下图所示,如果我们采用前缀匹配的方式,则红点和蓝点的前缀更为接近,但实际上它和黄点的实际距离更近。所以在搜索时,我们要搜索周围的8个方块。
这个函数包含两部分:
- geohashGetAreasByRadius获得上下文GeoHashRadius
- membersOfAllNeighbors得到所有满足条件的点
1 |
|
函数geohashGetAreasByRadiusWGS84(实际上是geohashGetAreasByRadius)根据中心点位置xy和搜索范围距离radius_meters计算georadius,这个GeoHashRadius georadius可以理解为是一个上下文对象。
1 | ... |
函数membersOfAllNeighbors对中心点以及它周边八个方向进行查找,找出所有范围内的元素,返回满足搜索距离范围的点。该函数中依次对中心点及周边8个区块调用membersOfGeoHashBox函数。这个函数比较厉害,我们后面单独讲。
1 | ... |
如果我们找不到对应的点,那么就返回一个空的Array。
1 | ... |
否则我们就进行排序。
1 | ... |
geohashGetAreasByRadius
1 | GeoHashRadius geohashGetAreasByRadius(double longitude, double latitude, double radius_meters) { |
我们首先以(longitude, latitude, radius_meters)构造一个圆,我们通过geohashBoundingBox计算这个圆的外接矩形的经纬度范围。
1 | ... |
接下来,我们要计算精度steps。
1 | ... |
geohashGetCoordRange函数没鸟用,就是单纯用GEO_LONG_MAX/GEO_LONG_MIN设置一下range,得到的range被用来做Encode。
1 | ... |
计算所有的邻居。这里的neighbors是GeoHashNeighbors结构的指针,这个结构里面保存了周围8个块的GeoHashBits。
1 | ... |
把一个GEOHASH值,解码成经纬度的表示area。
1 | ... |
我们需要检查自己算出来的step是否足够。下面的注释说有的时候,search area太靠近area的边缘了,step就还不够小,因为东南西北侧的正方形太靠近search area,以至于无法覆盖所有的东西。
【Q】反正我是没懂search area和area的区别是啥?
反正对于这种情况,我们需要再减小一下step。
1 | ... |
1 | ... |
membersOfAllNeighbors
这里讲解一下返回值geoArray,这是一个简单的数组,buckets和used让我们联想到了之前的dict等结构。实际上,它也就是保存了一些列的点。buckets表示数组的容量,used表示实际数组用了多少。
1 | typedef struct geoPoint { |
下面看主体函数
1 | /* Search all eight neighbors + self geohash box */ |
主要逻辑就是遍历所有的neighbors,并调用membersOfGeoHashBox。这里唯一值得一提的逻辑是,如果说我们的半径范围很大,例如超过5000km了,那么neighbour可能会重复,所以我们判断一下重复的neighbour。
1 | ... |
membersOfGeoHashBox
首先,我们根据hash,通过scoresOfGeoHashBox算出这个里面的位置点对应在ZSET中的score的范围。这个函数的实现,我们稍后讲。
1 | /* Obtain all members between the min/max of this geohash bounding box. |
scoresOfGeoHashBox
如果step是3,那么我们的hash就有step * 2 = 6个有效位。例如,二进制的hash值,即bits是101010。
但是因为我们的分数是52位的,我们需要获取101010?????????????????????????????????????????????的范围,所以我们要在101010后面填充,让它对齐成52bit。
因为我们补齐部分的?可以取0,也可以取1,所以我们可以直接自增二进制的hash值即bits。
1 | /* Compute the sorted set scores min (inclusive), max (exclusive) we should |
geoGetPointsInRange
在membersOfAllNeighbors中,ga最后是通过geoGetPointsInRange设置的。geoGetPointsInRange在ZSET中查找score位于min和max之间的所有元素,然后再通过geoAppendIfWithinRadius用(log,lat,radius)条件过滤一遍,将符合要求的点通过geoArrayAppend加入到ga中。
1 | /* |
geoAppendIfWithinRadius
1 | /* Helper function for geoGetPointsInRange(): given a sorted set score |
Rax
Redis还提供了一个基数树的实现。这个实现被用作Redis Cluster模式下面存储slot对应的所有key的信息。此外,在Stream、RDB、客户端缓存等模块中也用到了这个数据结构。
Stream
zipmap
总结
总结一下本章节中比较有意思的实现:
- sds可以通过一个指针同时访问header和data。
- sds的多种大小的header以节省空间。
- hash表的reverse binary iteration。
- 跳表实现中的span,用来方便计算rank。
- hyperloglog算法。
- redis实现hyperloglog算法中技巧:
- 分桶。
- 使用Sparse模式解决连续桶为0的情况,从而大大节省空间。这个方案可以被用来参考实现压缩稀疏的一维线性数据。
- 在8bit数组中维护6bit元素。
- geohash中interleave组合经度和纬度。

