介绍 F1 的在线异步 DDL schema 变更。
如果将不同表的 schema 当做各个 row,那么 DDL 可以看做是写这些 row,而 DML 和 DQL 则需要读这些 row。因此,可以给每个 schema 赋予版本号,从而实现类似 MVCC 的性质。
但是 DDL 的版本和 DML 的版本是不协调的。所以可能出现不一致的问题。
简要问题
定义问题
需要处理 DDL 执行进度不一致的问题,比如:
- Node A 已经处理了a/b/c 三个 DDL
- Node B 刚处理完 a 这个 DDL
假定 c 是创建一个表,那么 Node A 能看见这个表,而 Node B 则看不见。那么分别从 Node A 和 B 查询,就会发现数据不一致的情况。
具体来说,有两类不一致问题需要考虑:
- orphan data anomaly
违反1/3/5/7 - integrity anomaly
违反2/4/6
其中:
- 所有 ColumnKV 都能找到一个包含它的 Row 和 Table。
- 所有 Row 都包含所有非空列的 ColumnKV。
- 所有 IndexKV 都能找到一个包含它的 Index。
- 所有 Index 都是完整的(不存在某个 Row 缺少指向它的 IndexKV)。
- 所有 IndexKV 都指向有效的 Row。
- 没有违反 Constraint 的数据。
- 不存在未知的 KV(特指除上述 1,3 以外的未知 KV)。
分步解决问题
目标1:在同一时刻改变所有 Node 的状态。很遗憾,因为各种延迟并不能做到。
妥协后的目标1:在某一时刻修改 Schema,在确定的时间长度 T 之后,整个集群中不会有使用旧 Schema 的 Node 继续提供服务。这样在 T 之后这个修改就是确定生效的了。
方案:
- 定时刷新
每个节点会按照固定时间刷新自己的 Schema。
例如,可以选举出一个 Owner,每个节点定时向 Owner 请求当前的 Schema。 - 强制失败
如果刷新失败,则停止服务,而不是继续按照旧 Schema 服务。
目标1.1:在集群间同步最新的 Schema
方案:借助于 Spanner
- 每次刷新时,从 Spanner 上的某个固定位置加载 Schema。
在实现目标1后,发现还是有问题。例如,虽然 a/b 在 a+T/b+T 时刻被完成,但在 a+T 之前的某个时刻,我们仍然不知道当前状态是 a 已生效,还是 a、b 都已生效。如果在加上个 c,那么情况更复杂。
目标2:在同一时刻,只会有最多两个 Schema 生效。例如在同一时刻内,最多只有 DDL a 之前的状态和 DDL a 之后的状态生效。
分析:直接 Bruteforce 搞就行,比如插一个 barrier,等到 DDL a 确定生效(等到a+T)后,再执行 DDL b。
方案:
- 引入 Lease,长度等于 DDL 确定生效的时间
- 每个 Lease中只能执行一个 DDL
- 我们在 T+2 个 Lease 时一定可以执行 DDL b
目标2.1:不会产生不合法的 DML。
方案:write fencing
- 事务允许跨越多个 Lease。
- 但是,如果事务中有写操作,写操作只允许在当前 Lease 中进行:
- 写操作在他们 submit 时,转换为 Spanner 上的 KV 操作
- 如果写操作跨 Lease,可能会违反同一时刻集群中最多只有两个 Schema 版本生效的限制。
通过实现之前的目标进行了问题的分解,不需要处理多个 DDL 的进度不一致问题了。但仍然存在问题,考虑一个 add index 的 DDL,Node A 上已经执行完了,Node B 则没有开始执行,然后考虑此刻开始执行的两个 DML:
- 通过 Node A 添加一个 Row:会添加数据和索引
- 通过 Node B 删除一个 Row:只会删除数据,因为尚未得到索引的 schema
现在如果从Node A索引读,那么会读到一开始被写入的索引,但对应的数据却被删除了。于是这里产生了孤儿索引的问题,这破坏了数据库的完整性。这是因为不同Node之间同一DDL的进度不同产生的不一致,如何解决呢?
目标3:将这一个DDL拆成多个Schema Change的步骤。由于Update可以看做是Delete+Insert,所以实际需要考虑Insert、Delete和Query三种操作。
从孤儿索引的问题可以看出,delete操作需要和insert操作分离,要拆出一个Delete Only状态,这个状态下该DDL的只对Delete操作可见,即该索引只对Delete操作可见:
- 从None到Delete Only
增和查都不会使用索引。
所有的删除操作会使用索引。 - 从Delete Only到Public
不会出现孤儿索引问题了。假如Node A在Delete Only状态,它会在删除时一并删除索引;Node B在Public状态,在查询时发现索引被一并删除了。
但有个新的问题,索引不会“多出来”,但却可能缺。这就得需要有个操作帮忙补索引,也就是reorg。
这个补索引的过程能发生在Delete Only到Public之间么?假设Node A在Delete Only阶段,它只能响应删除,然后开始为既有数据补索引,直到补完变成Public,同时可以处理增删改查。问题是这个过程中的insert,对应的索引并没有被补上啊。因此,需要引入新的状态Write Only。
于是引入Write Only状态,这个过程只不允许读:
- 从Delete Only到Write Only
- 从Write Only到Public
假如Node A在Write Only状态,它的所有写操作都会涉及索引。而Node B在Public状态,它也能读到Node A的修改。
考虑所有节点都到达了Write Only状态,现在就可以做Reorg补上之前的索引数据了,方式很简单,就是取一个现在的Snapshot,然后照着补。此时可能有并发写的冲突问题,但Spanner的Percolator协议可以解决。
目标4:缩短Lease长度。Lease长度一般都会很长,F1中是分钟级,TiDB中也有45秒。如果完全走Lease的方案,那么一次DDL的时间就是分钟级的了,这显然很难被接受
方案1:直接将Lease长度缩短,例如改为1s。
这个方案是有问题的:
- 在每个Lease结束后,Node需要去加载最新的Schema,这个伴随网络开销,需要时间。如果加载Schema的时间大于Lease的时间,那么就会导致刚加载的又失效了,从而重新加载,极大地降低了性能。
既然方案1不行,那么就有了方案2
方案2:
- Owner在修改完DDL后,主动通知其他节点,并统计ack。如果其他节点都回复了,那么就主动确定了这个ddl在所有节点上都生效了。
- 如果有节点没有回复,那么再主动等2个Lease。
论文证明
Denotation
一个 F1 schema 是一系列 table的定义。每个 table 包含一系列 column、index、constraint、optimistic lock。其中 constraint 包含外键以及 unique 约束。
Schema elements and states
schema elements 包括 table、column、index、constraint、optimistic lock。每个 element 都可以对应 absent 和 public 两个 state。此外,还有 delete only 和 write only 两个中间态。
【定义1】一个 delete only 的 table、column 和 index 不能被读,且:
- 如果 E 是 table 或 column,则只能被 delete
- 如果 E 是 index,则只能被 delete 和 update,这里的 update 不包含 create
注意这里的范围会更大一点了。
【定义2】一个 write only 的 column 或 index 可以被 insert、delete、update,但继续不能被读。
【定义3】一个 write only 的 constraint 会在执行 insert、delete、update 操作应用。但它不能覆盖所有的已有数据。
Database consistency
【定义4】一个 database representation(可以理解为某个快照) d consistent with respect to schema S,如果
- 所有的 column 都属于 row 和 table
- 所有的 row 都具有所有 public required 的 column 值
- 所有的 index entry(索引数据)在 schema 中都能找到对应的 index
也就是说我们写了条索引,但是 schema 里面却没有定义这一条索引 - 所有的 public 的 index 是完整的
也就是说不会存在某一个 row 上没有对应的 index - 所有的 index 都能指向 valid 的 row
实际上就是不会有孤儿索引 - 所有的 public 的 constraint 一定是满足的
- 不存在未知数据
这个定义在之前已经提到过了。
We denote the fact that database representation d is consistent with respect to schema S as d |= S. If d is not consistent with respect to schema S, we denote this as d |/= S.
【定义5】从 S1 到 S2 的 schema change,是 consistentcy preserving 的,当且仅当:
- d 在 schema S1 中任何操作下能够对 schema S2 也能保持 consistency
- d 在 schema S2 中任何操作下能够对 schema S1 也能保持 consistency
下图描述了不同元素的 schema 的变更。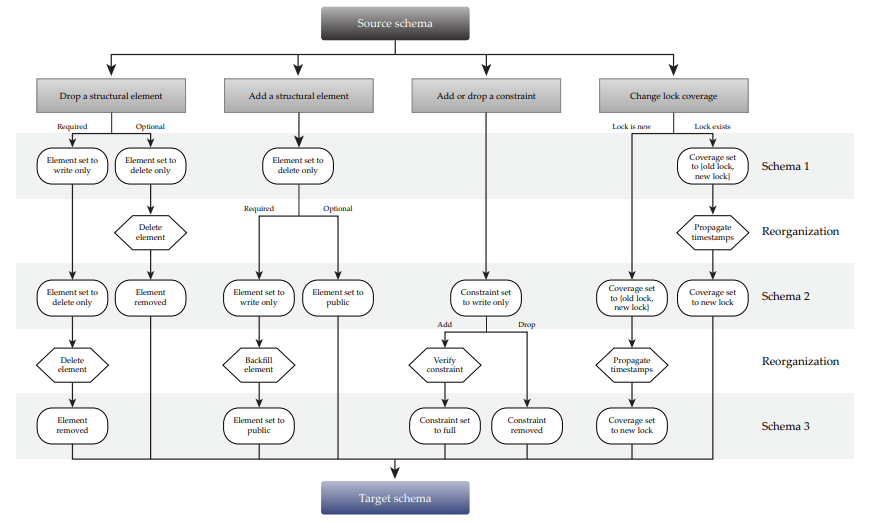
Adding and removing schema elements
我们将 table、column和 index 称为 structural elements。它们可以被理解为决定了 Spanner 上能存储哪些 KV 数据的元素。注意 optimistic lock 因为在处理上和 column 是一致的,所以我们将它包含在 column 中讨论。
【Claim2】所有从 S1 到 S2 的 schema change,如果涉及到增加或者删除 public 的 structual element E,那么它就不是 consistency preserving 的。在下面的例子中,假设 S2 包含了 E,但 S1 没有。即从 S1 到 S2 的变换是新增。
- E 是 table
如果对 S2 上的 E 做 insert,那么得到的 representation d2 和 S1 是不一致的。因为其中包含的新增的数据 S1 不能解析。违反了 Database consistency 中的第一条。 - E 是 table R 上的 column
同上 - E 是 table R 上的 index
如果在 S2 上的 E 做 insert,那么会同时违反3和4。对于 S1,违反了3,因为我们写入的索引在 schema 里面没找到定义。
【Claim3】从 S1 到 S2 的 schema change 是 consistency preserving 的,当且仅当它在 S1 和 S2 上都能避免 orphan data 和 integrity anomaly 两种数据不一致的情况。
Optional structural elements
这里的 Optional 指的是 element 是可选的,例如定义了 default,或者是 nullable 的。
【Claim4】【absent->delete only】考虑从 schema S1 到 schema S2 的 schema change,它添加了一个 delete only 的 structural element E。对于任意的 representation d,且 d |= S1, d |= S2。那么所有基于 S1 和 S2 在 E 上的操作都不会产生两种异常。
【Claim5】【delete only->public】类似 Claim4
Required structural elements
Reference
- http://zimulala.github.io/2016/02/02/schema-change-implement/
- https://github.com/zimulala/builddatabase/blob/master/f1/schema-change.md
- https://disksing.com/understanding-f1-schema-change/
- https://tongtianta.site/paper/57876
Online, Asynchronous Schema Change in F1 - https://www.zenlife.tk/schema-lease.md
- https://hhwyt.xyz/2021-03-27-online-async-schema-change-in-f1/
- https://zhuanlan.zhihu.com/p/309831009
一个翻译

