介绍 C++ 上的内存监控方案。
默认使用 jemalloc。
MemoryTracker
原理是每次分配内存的时候,manually 去向⼀个 MemoryTracker 注册。下层级的 Tracker 和上层级的 Tracker ⼀起组成树状结构。
prof.dump
可以定期通过 prof.dump 的方式 dump 下堆文件。
需要配置 MALLOC_CONF 为 prof:true,否则会报错 Resource temporarily unavailable。可以设置 prof.activate:false 避免在不需要 profile 的时候,产生开销。
注意,prof:true 是不可以运行期修改的。但是 prof.activate 是可以的。
有关 dl_iterate_phdr 的死锁
在 Rust 中因为 Backtrace::new() 会调用 dl_iterate_phdr,而这个函数会调用 mutex。如果一个 signal 在获得这个锁之后过来,就会死锁。在 tikv 中,很容易就会调用到 Backtrace,特别是在有错误的时候。在 _Unwind_Backtrace 中,也会调用这个锁。对应的 libunwind 的 issue。
解决方案是在 prof-rs 中禁用掉 ["libc", "libgcc", "pthread", "vdso"] 这几个库的 unwind。
有关 dwarf 下 prof 变慢
【这里几个图在我的破 QQ 文档里面我就懒得放了】
事情的起因是无论是手动调用 profile 还是自动进行的 continuous profiling,预期 10s 的 profile 时,实际会花一分钟左右,从而将 status_server 线程卡住而无法处理 prometheus 的 http 请求。
经过加日志断点,发现时间主要花在生成火焰图上,耗时约 40s。
观察生成火焰图的火焰图,发现花费大量时间在 miniz_oxide 上。
后面发现这个错误在 frame pointer 上不存在。当然 frame pointer 上有 bug,所以我们对于 x86 统一换成了 dwarf。另外,如果将 TiFlash 的压缩 debug section 去掉,耗时也会显著减少。这个是在 cmake/tiflash_linux_post_install.cmake 里面 --compress-debug-sections=zlib-gnu 来清理的。但去掉之后,binary 大小是原来的三倍,所以去掉也不是长久之计。
去掉之后发现是 addr2line 耗时比较多。这里发现有个 do_rallocx 函数,对应了 Report::pprof 中将符号入栈的操作。它花了不少时间。
这从而也启发到我同事,说可以比较下 dwarf 拿到 backtrace 和 frame pointer 的栈的深度。可能 dwarf 拿到的栈会深很多(比如 inline 的函数可能能拿到),所以从地址转换成符号花的时间更长。这个比较下来,实际上两个栈差不多大。
然后同事发现,在 https://github.com/tikv/pprof-rs/blob/1f4ef0991dc780ed11dc17954a38d0a3abd59c61/src/report.rs#L72 处一个循环耗时很高,循坏一千多次花费四十多秒。
进而进入 Frames::from 中,这里根据 dwarf(即 bracktrace-rs) 或者 framepointer 实现,会选择不同的 Frame 实现。而在 backtrace 中的 resolve_frame 中会先读 mapping_for_lib,这是个 cache,如果 cache 不够才会读别的。
这里我怀疑可能是因为 dwarf 里面 symbol 比较多,然后 cache 被 evict 掉了。
根因应该是 dwarf 的 backtrace 深度比较深,涉及的 so 会更多,而 backtrace-rs 里 lib cache 最多只有4个,所以 dwarf cache miss 会比较频繁,需要不断地对 so 的 debug_section 解压缩和 addr2line。https://github.com/rust-lang/backtrace-rs/issues/499。
发现其实如果用 addr2line 去读 heap,耗时也会很长,感觉还是和 binary 的压缩有关。
1 | root 986545 1.8 0.1 520308 515644 pts/32 S+ 17:39 0:16 perl ./jeprof --add_lib bin/tiflash/libtiflash_proxy.so --add_lib bin/tiflash/libgmssld.so.3 --svg bin/tiflash/tiflash jeprof.910766.14.i14.heap |
另外,binutils 也要升级,不然会出 invalid or unhandled FORM value 0x25 错误。
Jemalloc allocatedptr
这个方案要求感知线程的创建和销毁,在对应的时候,通过 thread.allocatedp 和 thread.deallocatedp 来注册。这样就可以知道每个线程分配或者释放了多少内存。
该⽅案能够很好看到内存分配和释放的速率和增量,例如如果观察到 allocated 斜率⼤幅增加,则说明该线程最近在⾼速分配内存。但难以判断某个线程到底 own 了多少内存,原因是:
- ⼀个线程可能释放另⼀个线程分配的内存。例如同一个模块中线程 bg-1 分配的内存可能被另⼀个线程 bg-2 释放。
- Rust 的 move 语义和协程机制会加剧这个问题。
其实 allocatedp 这个调用是成对的,还有一个 thread.allocated 可以立即返回当前的 caller thread 分配了多少内存。而 thread.allocatedp 可以返回一个指针,解引用这个指针可以返回对应线程当前分配了多少内存。通过 allocatedp 可以避免频繁的 mallctl 调用,也可以实现从其他线程进行观测。但其中比较困难的一点就是如何监测线程的启动和释放,从而判断对应的指针是否能够被读取。一种做法是包装线程池的 API,在每个线程启动和释放的时候加上 hook。
此外,这种方式对于 Rust 程序会有一些问题:
- Rust 的移动语义会导致一些线程分配的内存会被另一个线程释放
比如返回一个 T : Send 给另一个线程作为 Result。通常在需要使用线程池进行处理的逻辑中。 - 协程跑在 executor 上面,难以分清辨认出具体的用途
Jemalloc Arena
该⽅案可以看做是对 allocatedptr 的补充。通过 arena.create 创建一个 arena,通过 thread.arena 绑定⼀个线程到某个 arena,则可以通过该 arena 获知该线程 own 了多少内存,所以这是看存量的⼯具。
但线程 own 多少内存,并不等于某个模块占⽤了多少内存。原因:
- 内存的 ownership 会在平⾏的模块之间转移。例如 P 模块分配出来的内存,可能会被转移给 S 模块。所以即便能够看到 S 线程池对应的 arena 的占⽤上升,也难以判断是 S 模块的原因,还是 P 转移过来的内存。
- 上级模块从同线程中调⽤下级模块,⽆法区分出上级和下级分别消耗了多少内存。
这个⽅案有下述的缺点:
- 我们更需要找内存增⻓的根因,知道内存都在哪些 arena ⾥⾯未必是⾜够的。
- 一些使用线程池的模块中的内存分配⼤致满⾜“⾃⼰⽤⾃⼰弃”的 pattern,因此可以通过减法来算出存量。因此,“Jemalloc Arena” 相⽐ “Jemalloc allocatedptr” 的⽅案的作⽤不是很⼤
可以使用 mallocx 为某个模块指定对应的 arena。TiKV 的 benchmark 展示这不会产生很明显的 overhead。
thread_local memory tracker
来⾃ Doris 的 Memtracker ⽅案。
该⽅案可以作为 “Jemalloc allocatedptr” ⽅案的补充。对于“上级模块从同线程中调⽤下级模块”的情况,可以使⽤⼀个 thread_local 变量记录栈中的⼀部分的内存开销。如下所⽰ kvs_page_mem 这个 thread_local 变量记录了 thread 1 中从 KVStore 调⽤到 PageStorage ⼀部分的开销。因此再结合 “Jemalloc allocatedptr” ⽅案本⾝的数据,就可以区分开来 PageStorage 产⽣
的内存(如新建⽴的 PageDirectoy)和调⽤链路上其他的内存,如 KVStore 和 PageStorage 中缓存的其他内容。
thread_local 的信息会被定时地上报给全局的 tracker,并由 tracker 做聚合后上报给 Prometheus。
也可以直接复⽤当前的逻辑,由 tracker 直接做聚合,但这样就需要⼀个全局的 hook 去线程启动的事件。
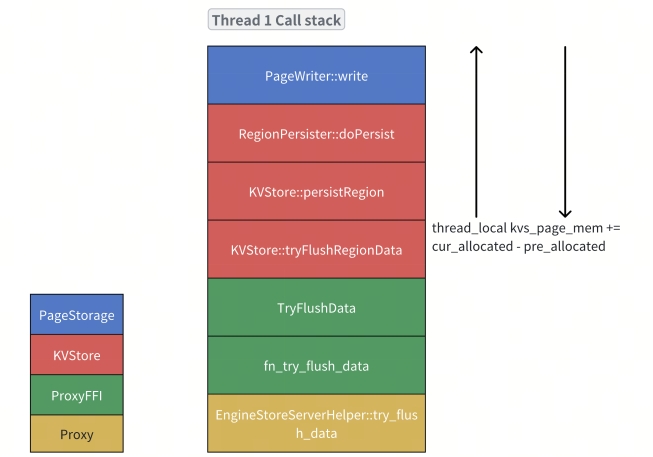
缺点:
- 只能根据调⽤链路细化,不能追踪某个组件占据了多少内存。
Jemalloc mallocx
通过 MALLOCX_ARENA flag,可以在 mallocx 的时候指定从某个 arena 分配。因此对于模块 A 可以替换它的所有 malloc 为 mallocx,从⽽实现追踪该模块的内存分配。
C++ 中内存管理层级和⽅式都很多,不能通过简单替换 mallocx 才能做到按组件统计。
C++ 的堆内存管理层级
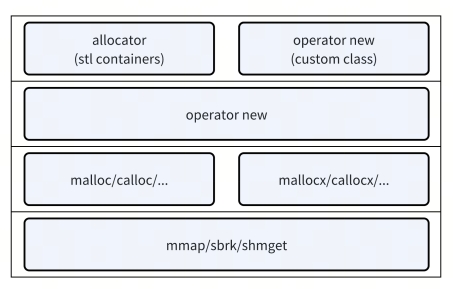
C++ Custom Allocator
对于 stl 中的 container 类型提供,指⽰如何构造 Container<T, CustomAllocator<T>> 。因为⼤部分内存的占⽤都是通过 C++ 的容器对⼀些基本类型组合产⽣的,因此通过指定⾃⼰的 allocator 可以达到较⾼的覆盖率。
缺点:
- 只对 stl 起作⽤,custom class 需要⾃⼰适配,并且会传染。
- Stl 的接⼝也不同,诸如 std::map、std::vector 需要提供⼀个额外的参数。⽽ std::make_shared
需要被 std::allocated_shared 代替。修改成本⽐较⼤。 - Allocator 是有类型的,所以不同 allocator 的容器之间不能简单实现互操作,除⾮使⽤ pmr。
pmr
需要⽤ std::pmr 下⾯的容器,同样具有传染性。
C++ Custom global operator new
可以通过下⾯实现⼀些类似 “thread_local memory tracker” 的功能,避免掉⼿动埋点。
- 在 new 或者 delete 中调⽤ backtrace 获得前⼀帧,判断组件来源
- 设法 inline 这些 operator,然后给需要监控的
__FUNCTION__加上特定的前缀
1 | inline __attribute__((always_inline)) void *operator new(size_t size) |
缺点:
- 在 critical path 上,打击范围太⼴。C++ 实践中不太推荐这么做。
C++ Custom class operator new
相⽐ global operator new 的⽅案,class operator new 的时候已经知道了对象的类型,所以打击范围不⼴。我们可以仅仅针对某些对象统计。
缺点:
- 只能追踪通过 new 分配的内存。栈内存⼀般较⼩,所以这⼀点不是问题。
- 在对象内部再通过 new 分配的动态内存⽆法被追踪。也就意味着
std::vector::push_back 、 std::make_shared 和 new T[] 这样的主⼒内存分配点⽆法被跟踪。
因此,基于这样的⽅案,需要在某个 T 提供⼀个 size() ⽅法,然后 hook 住 T 的 operator new,从⽽给到关于 T 的总内存占⽤的统计。例如对 Block 和 VersionedPageEntries 提供统计。
缺点:
- std::make_shared 直接调⽤ ::new,因此对此没有作⽤
我的一些实践
TiFlash 的 heap profiling
提供了几种方案:
heap_activate、heap_deactivate
这个接口会启动一个线程定期调用 prof.dump。后续可以通过 heap_list 获取所有的 heap 文件,然后 curl 命令下载某个文件到本地。set_prof_active、set_prof_inactive
这个接口只会操作prof.activate。用户需要手动在某个时候触发 prof.dump。这是因为只要 activate 了,就会开始记录堆分配的情况,不触发 prof.dump 这样就可以避免产生较多的文件,从而污染客户的环境。heap、symbol
这个接口最为灵活,因为它支持 jeprof 从外部环境访问这个接口,从而避免访问用户的机器,或者 binary。1
2
3
4
5
6//go:embed jeprof.in
var jeprof string
func fetch() {
cmd := exec.Command("perl", "/dev/stdin", "--raw", scheme+"://"+op.ip+":"+strconv.Itoa(op.port)+op.path)
cmd.Stdin = strings.NewReader(jeprof)
}注意,这种方式一般要持续开启
prof.activate。因为临时开启,则收集的时间过于短暂,可能无法生成有信息的报告。
这种⽅式其实上是 jeprof 调⽤/debug/pprof/heap?jeprof=false,把 heap 下载到本地来处理的。也可以⼿动 curl 这个下载下来,⽤ jeprof 处理。注意,这个时候需要⼿动指定 TiFlash 的 binary,如果没有指定,或者⼿动指定出错,则会报错 The first profile should be a remote form to use /pprof/symbol。
遇到的一些问题
Arm 架构下,一些功能无法执行:
- 在 AWS 的 arm + Rocky9 Linux 下,/heap 和 /heap_activate 不会显示 C++ 部分的栈,需要开启
lg_prof_interval才行- 开启
lg_prof_interval后,即使关闭 prof.active,仍然可能会有 dump 产生
- 开启
- 在 AWS 的 arm + ubuntu 下,profiling 正常
- 在 Kunpeng + Rocky9 Linux 下,会在 libunwind 中报错 panic
https://github.com/pingcap/tiflash/issues/10152
addr2line 的版本问题
上⾯提到过有的时候⽣成的不详细,如下所⽰。这是因为 addr2line 版本的问题,有条件的可以通过传参的⽅式把 jeprof.in 使⽤的 addr2line ⾃⾏魔改为 llvm-addr2line。注意,llvm-addr2line 的版本,也需要和 tiflash ⼀样,不然
1 | addr2line: DWARF error: could not find variable specification at offset |
DWARF error:section.debug_info is larger than its file size.
报错 DWARF error:section.debug_info is larger than its file size. 这个问题需要连同 nm、objdump 等全部换成 llvm 的版本。
生成不了 Cpp 或者 Rust 的栈
另外,一些情况会生成不了 Cpp 或者 Rust 的栈,例如只有其中某个语言的栈。此时需要检查:
1 | pprof = { version = "0.14", default-features = false, features = [ |
并且还需要检查 jeprof.in 的参数
1 | Command::new("perl") |
heap 火焰图的调参
1 | - $main::opt_nodecount = 80; |
需要的工具
如果使⽤宿主机 tiflash 上的 jeprof.in,则必须宿主机上有下列⼯具:
- perl
缺少 perl 可能会有报错 3329,或者 No such file or directory - objdump
但此时 raw 会报错 “jeprof can only dump remote profiles for –raw”,⽽ text 只有简略信息,并且不能反应出 addr2line 之后的结果。还需要⾄少如下⼯具,才能返回正常
- addr2line
- nm
- c++filt
另外,注意在 jeprof.in 中使用 llvm-addrline,不然可能会出现 0x25 的报错,并且生成的 svg 图有缺失。
TiFlash 的 continuous profiling
有下列问题会影响 TiFlash 开启 continous profiling
- https://github.com/pingcap/tiflash/issues/5285
一个修复在 https://github.com/pingcap/tidb-engine-ext/pull/640,但可能还有别的原因导致。 - https://github.com/pingcap/tiflash/issues/6228
修复在 https://github.com/pingcap/tidb-engine-ext/pull/213 - https://github.com/pingcap/tiflash/issues/3236
修复在 https://github.com/pingcap/tiflash/pull/9240,就是上面提到的 dl_iterate_phdr 死锁问题

