本文介绍 LevelDB的 SSTable 相关功能。
SSTable 是 LevelDB 的内存数据结构。当一个 Memtable 满之后,会被变成 Immutable Memtable,并写入 SSTable Level0。Level0 的 SSTable 是没有经过归并的,各个 Key 可能互相重叠。经过 Compaction 达到 Level1 之后,就是有序的了。
目录:
- LevelDB 之 Memtable 实现
- LevelDB 之 SSTable 实现
- LevelDB 之 Version
- LevelDB 之 Compaction
- LevelDB 之 WAL
- LevelDB 之流程概览
SSTable格式
SSTable 是后缀为 .sst 或 .ldb 的文件。
在官方文档中,对 SSTable 的格式已经有了介绍。
1 | <beginning_of_file> |
data block
放有序的 KV 对。在查询SSTable文件的时候,也可以二分。
将专门讨论 Block 的组织。meta block
用来快速定位 key 是否在 data block 中。容易想到,里面可以是一些类似于 bloom filter 的实现。metaindex block
每个 metaindex block 一条记录。其中 K 是 meta block 的名字,V 是指向这个 meta block 的 BlockHandle。
BlockHandle 类似于指针,具有下面的结构。这里面也用了 VarInt 结构。1
2offset: varint64
size: varint64有两种 meta block 类型,filter 和 stats:
- 如果在数据库启动时指定了某个
FilterPolicy,就会创建一个filter block。 - 统计信息
- 如果在数据库启动时指定了某个
index block
每个 data block 对应 index block 中的一条 entry。这个 index block entry 的.key()大于等于指向的 data block 最后一个 K【性质1】,但是严格小于下一个 data block 的第一个 K【性质2】。
因此可以通过和 index block 比较来快速定位 data block。footer
包含:- metaindex handle
- index handle
- padding
- magic number
Block实现
SST 的构建主要集中在 table_builder.h/cc 和 block_builder.h/cc 中。SST 的读取主要集中在 table.h/cc 和 block.h/cc 中。
从前面可以看到,SSTable 主要有两层结构,Table(SSTable) 和 Block(data/index 等)。
Table 由多个 Block 构成,所以从 Block 开始分析。
BlockBuilder/Block原理
BlockBuilder 负责生成诸如 data block、index block 等所有 block。
Block 对象负责读取这些 block。
共享前缀
因为 BlockBuilder 是有序的,所以使用如下的共享前缀来节约空间:
普通
1
2Hello World
Hello William共享
1
2Hello World
illiam
Block 的构造如下图所示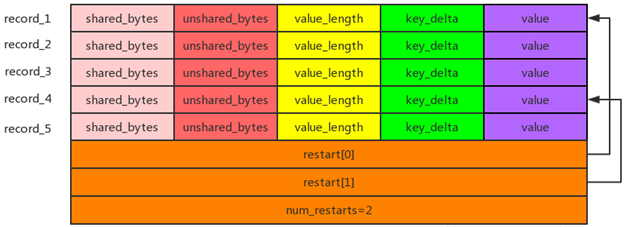
其中:
- shared_bytes
Key 和上一个 entry 的共享前缀的长度。 - key_delta/unshared_bytes
Key 除了共享前缀之外的剩余串,以及其长度。 - value/value_length
值的串和其长度。
那么如何读用共享前缀表示的 K 呢?
最坏状况,比如需要读到第一个 Entry
如下所示,第三个 K 是 abc,但是我们得回溯到第一个 K 即 a 才能确认。1
2
3a
b
c最好状况,读当前的就行
比如下面的 a 和 b 根本没有任何共享串。1
2a
b
restart
可见共享前缀会给读带来困难,因此又引入 restart 机制,即每隔 block_restart_interval 之后会去存储一次完整的 key,对应的 entry 的位置称为 restart point。在 block 中,会存储下所有的 restart point。
因为 Block 内部有序,所以能通过二分 restart point 来加速读取,具体代码在 Block::Iter 中。读取需求一般是给定 target,要求找到第一个 K 大于等于 target 的 entry。可以通过二分,即 Block::Iter 的 Seek 方法来做。
filter block
在每个 data block 内部,借助于二分 restart 可以实现 $log(n)$ 复杂度的查询,那么能在 data block 之间二分么?
可以通过 filter block 来判断某个 key 是否属于该 data block,实现是 bloom filter。
BlockBuilder实现
方法
void Add(const Slice& key, const Slice& value);
每一次 Add 的 Key,必须是有序的,从小到大的。Slice Finish();void Reset();
BlockBuilder::Add
首先是三个 assert:
- 第一个很好理解,如果
finished_,相当于已经调用了 Finish 或者 Abandon 等方法。 block_restart_interval表示每过多少个 key 就要设置一个 restarts。设置完之后,counter_会被重置为0,所以这个不等式是成立的。- 最后一个是有序性检验,要不是空的,要不新来的
key要大于老的last_key_piece。
1 | void BlockBuilder::Add(const Slice& key, const Slice& value) { |
下面判断要不要 restart:
- 如果不要,和前一个 key 即
last_key_比较,算出来能 share 多少长度。 - 如果要,就 restart。
1 | ... |
下面就是往 buffer_ 里面写数据了。
1 | ... |
下面这个优化点也很有趣,首先 last_key_ 保存的是一个完整的 key。但可以复用之前一个 key 的 shared 部分,这个是安全的。接着把 non shared 部分 append 上去。这样就在本轮迭代最后更新了 last_key_,后面还可以和 key 进行校验。
1 | ... |
BlockBuilder::Finish
为啥 restarts_ 不用 VarInt 存呢?
1 | Slice BlockBuilder::Finish() { |
Block实现
uint32_t NumRestarts() const;
之前了解过 Block 的结构,在 Block 的最后,是 restart 点的个数。也就对应了这个方法。1
2
3
4inline uint32_t Block::NumRestarts() const {
assert(size_ >= sizeof(uint32_t));
return DecodeFixed32(data_ + size_ - sizeof(uint32_t));
}const char* data_;/size_t size_;
也就是这个 Block 的指针和长度。uint32_t restart_offset_;
表示 restart 的开始位置1
size_ - (1 + NumRestarts()) * sizeof(uint32_t)
bool owned_;
取决于构造函数传入的BlockContents的owned_字段。
Block::Iter
Seek
这个函数是二分:
mid < target
则搜索[mid, right]mid >= target
搜索[left, mid-1]
这是一个 TTT…F/T 的二分,所以每次要令 mid = (left + right + 1)/2。
但这里二分的难点是,Block 中为了压缩空间,使用的是共享前缀的办法进行存储的。因此很难取得二分的 key。因此我们实际上是二分的 restart points。
有一个 GetRestartPoint 函数来计算当前 restart point 位置对应的 entry 的位置。
1 | class Block::Iter : public Iterator { |
下面是函数主体。介绍几个成员变量:
- restarts_
存储传入的 restart,表示在 restarts 数组里面的位置。 - current_
初始值为 restarts。
Valid() 主要是判断 current_ 和 num_restarts_ 的关系。
1 | void Seek(const Slice& target) override { |
1 | ... |
一些问题
Block 的大小如何选择?
Block size 变大,则:
- 索引变少,节约空间
- 写入的 IO 次数变少,提高性能
- Block Cache 只能缓存更少的 Block,可能造成较多的读盘,读放大加重
Table实现
TableBuilder
Status ChangeOptions(const Options& options);
修改 option。但如果 Table 已经被创建,那么有些 Option 就不能被修改了。此时会报错。void Add(const Slice& key, const Slice& value);
增加一个 KV 对。
key is after any previously added key according to comparator,往TableBuilder里面加KV,必须是有序的?void Flush();
将内存中缓存的数据写入磁盘。因为 SSTable 是一个文件,所以相当于是写一点,Flush 一点,从而控制 Block 的大小。
注释上说可以被用来保证两个相邻的 Entry 不会在同一个 data block 中,不是很明白什么意思。Status status() const;Status Finish();
结束当前表的构建。void Abandon();
表示需要丢弃当前缓存内容,并且结束表的构建。uint64_t NumEntries() const;
Add 了多少次,实际上返回的是TableBuilder::Rep里面的num_entries。uint64_t FileSize() const;void WriteBlock(BlockBuilder* block, BlockHandle* handle);void WriteRawBlock(const Slice& data, CompressionType, BlockHandle* handle);
此外,TableBuilder 持有一个 Rep 类型的对象指针,用来隐藏相关实现。
在 Add/Flush/Finish/Abandon 中会检查此时 Adandon 和 Finish 不能已经被调用。
TableBuilder::Rep
具有下面的:
Options options;Options index_block_options;WritableFile* file;
WritableFile是一个接口,具体实现可以分为随机读写文件,顺序读写文件等。uint64_t offset;Status status;
是ok()的返回值,表示是否发生了错误。一般,错误会在file里面的 Append 和 Flush 方法中出现。BlockBuilder data_block;BlockBuilder index_block;std::string last_key;
每一次 Add 会更新这个字段。因为 Add 是有序的,所以实际上就表示了当前最大的 key。int64_t num_entries;
见NumEntries。bool closed;
Finish 和 Abandon 会设置为 true。FilterBlockBuilder* filter_block;bool pending_index_entry;
当写完一个 data block 之后,设置pending_index_entry,表示需要更新 index block。
这里有个不变量,当且仅当data_block为空的时候pending_index_entry才是 true。一个 Table 中有多个 data block,当写完一个 data block 后,设置pending_index_entry为 true,之后更新 index block。BlockHandle pending_handle;
Handle to add to index block。不是说用这个 handle 来写 index block,而是会把这个 handle 里面的值写到 index block 里面作为 index。std::string compressed_output;
写 index block 的顺序是:
- 写一个 data block
- 接到下一个 Add 请求
- 根据
last_key和当前传入的 Key,写 index - 正常处理该 Add 请求
这里会有疑问,为什么不在写完 data block 的时候就直接写 index block,而是要等到读到下一个 data block 的第一个 key 的时候才写呢?其目的是这样可以通过之前提到的 FindShortestSeparator,在写 index 的时候用尽可能短的 key。例如,已经知道第一个 data block 中最大的是 “the quick brown foxggggggggggg”,而第二个 data block 中最小的是 “the who”。如果我们刚写完第一个 data block,就只能用 “the quick brown foxggggggggggg” 这个很长的字符串来写 index 了。而如果读到下一个 key 实际是 “the who” 的话,就很从容地可以用 “the r” 作为 index block 中的 entry。因为 “the r” 既大于等于第一个 block 中的所有 key,又小于第二个 block 中的所有 key。
TableBuilder::Add
1 | void TableBuilder::Add(const Slice& key, const Slice& value) { |
如果 pending_index_entry 是 true,说明之前已经写入了一个 data block。因此要插入 index,然后清理pending_index_entry标志。
1 | ... |
下面是 Add 的主要逻辑,先处理 filter block。
1 | ... |
然后设置 last_key,并向当前的 data block 中添加 KV。
估算当前 data block 的大小,如果超过配置的阈值 options.block_size就进行调用 Flush 生成一个 Block。
这个估算实际上就是统计所有 entry 以及 restart 的总大小。相比Spark 里面的大小估计,感觉 LevelDB/Redis 里面的大小估计要简单很多,感觉得益于 C/C++ 能自己管理内存。
1 | ... |
TableBuilder::WriteBlock
WriteBlock
Table 在 WriteBlock 要先调用 BlockBuilder::Finish 处理一些元信息,也就是说把所有 restart 都写到文件里面。
1 | void TableBuilder::WriteBlock(BlockBuilder* block, BlockHandle* handle) { |
接着,是写 data block 。实际写入的 block_contents 可能是被压缩了的,也可能是没有被压缩的。
1 | ... |
清空这个 Block 里面 buffer_、restarts_ 等状态。
1 | ... |
TableBuilder::WriteRawBlock
每一个block包含:
- data
- type 表示有没有压缩
- crc32
1 | void TableBuilder::WriteRawBlock(const Slice& block_contents, |
TableBuilder::Flush
当目前内存中的数据达到一个 Block 的大小时,就调用 Flush。
Flush 一开始是判断一些条件:
- 如果说 data block 是空的,那么就直接返回。
- 断言
pending_index_entry这个是 true。因为如果没写 index,肯定不能 flush。
1 | void TableBuilder::Flush() { |
根据 pending_handle 的说明,它的值会被写到 index block 里面。
1 | ... |
TableBuilder::Finish
Finish 操作用来生成一个 SSTable。需要区分 BlockBuilder::Finish。
首先先 Flush,也就是把 data_block 写盘。
1 | Status TableBuilder::Finish() { |
什么时候不 ok 呢?也就是发生错误的情况。
下面,写入 filter block。
1 | ... |
如果上面成功,接着写入 meta index block。
1 | ... |
如果上面成功,接着写入 index block。
1 | ... |
如果上面成功,接着写入 footer。
1 | ... |
Table
下面介绍 Table 类,它的作用是负责读取 SSTable。
static Status Open(const Options& options, RandomAccessFile* file, uint64_t file_size, Table** table);
解析传入的file。
如果成功,返回 ok,并且设置*table,这是一个指针,由调用方释放。
如果失败,返回一个非 ok,并且设置*table为 nullptr。
Does not take ownership of “*source”, but the client must ensure that “source” remains live for the duration of the returned table’s lifetime.Iterator* NewIterator(const ReadOptions&) const;uint64_t ApproximateOffsetOf(const Slice& key) const;
传入一个 key,返回它在文件中的大概位置。对不存在的 key,返回如果存在,那么大概在的位置。static Iterator* BlockReader(void*, const ReadOptions&, const Slice&);
TwoLevelIterator 需要这个函数,通过它来构建一个data_iter_Status InternalGet(const ReadOptions&, const Slice& key, void* arg, void (*handle_result)(void* arg, const Slice& k, const Slice& v));void ReadMeta(const Footer& footer);void ReadFilter(const Slice& filter_handle_value);
Table::Rep
Options options;Status status;RandomAccessFile* file;uint64_t cache_id;FilterBlockReader* filter;const char* filter_data;BlockHandle metaindex_handle;Block* index_block;
Table::Open
首先解析出 footer。
1 | Status Table::Open(const Options& options, RandomAccessFile* file, |
接下来,解析 index block。
1 | // Read the index block |
初始化 rep_ 字段。
1 | if (s.ok()) { |
Table::NewIterator
实际上调用 NewTwoLevelIterator 得到一个 TwoLevelIterator。
1 | Iterator* Table::NewIterator(const ReadOptions& options) const { |
方法 NewIterator 的实现如下。如果没有 restart 点,那么就创建一个空的迭代器,否则创建一个Block::Iter。
1 | Iterator* Block::NewIterator(const Comparator* comparator) { |
两个 Level 的含义是:
IteratorWrapper index_iter_负责查询 index block,找到 key 所在的 data block。
IteratorWrapper封装了Iterator,可以理解为一层对valid()和key()的 cache。整体上类似于 TiFlash 中 MultiSSTReader 的实现。
Iterator是个接口,实际类型应该是Block::Iter【待确认】。IteratorWrapper data_iter_负责在这个 block 里面查找。
TwoLevelIterator
BlockFunction block_function_;
由block_function_可以从一个index_iter_创建一个data_iter_。
在 Table 的实现中,是Table::BlockReader这个函数。我们将在后面详细分析这个函数。void* arg_;
在 Table 的实现中,传入了Table* this。const ReadOptions options_;Status status_;IteratorWrapper index_iter_;IteratorWrapper data_iter_;std::string data_block_handle_;
如果data_iter_不是 null,那么data_block_handle_持有传给block_function_的那个index_iter_的值。
TwoLevelIterator::Next
存在一个问题,如果一直 data_iter_.Next(),迟早会碰到一个 Block 的右边界,这样后面迭代器就 Invalid 了。因此需要检查如果 data_iter_ 当前已经失效了,那么就递增 index_iter_,获取下一个 data_iter_,具体实现见下面。
1 | void TwoLevelIterator::Next() { |
TwoLevelIterator::SkipEmptyDataBlocksForward
【Q】在上面说过这个函数的作用了,但是为啥这里实现是 while 而不是 if 呢?
1 | void TwoLevelIterator::SkipEmptyDataBlocksForward() { |
SetDataIterator 函数接受一个迭代器作为参数,如果迭代器不是空,那么就设置为 data_iter_,并且释放掉原来的 iter_ 内存。
1 | ... |
需要注意,这里需要显式将data_iter_移动到当前data block的开头。
1 | ... |
TwoLevelIterator::InitDataBlock
InitDataBlock 作用是从 index_iter_ 构建或者说解析出一个 data block。
如果 index_iter_ 无效,那么设置 data_iter_ 也无效。
如果 data_iter_ 不为空,并且等于之前的 data_block_handle_,说明 data_iter_ 现在就指向的这个data block,那么就跳过。
否则,以 index_iter_ 为参数,通过 block_function_ 生成一个新的 data_iter_。
1 | void TwoLevelIterator::InitDataBlock() { |
TwoLevelIterator::Seek
首先,在 index block 层 Seek。下面证明只要找这个 index_iter_ 指向的 data block 就行,也就是说,target 不会出现在 (index_iter_ - 1) 和 (index_iter_ + 1) 指向的 data block 里面。
- 因为 LevelDB 中的性质,Seek 得到的是第一个大于等于 target 的指针。此时,
(index_iter_ - 1)中的.key()是严格小于 target 的。而根据 index block 的【性质1】,这个 index block entry 指向的 data block 中的所有 K 都小于等于(index_iter_ - 1).key()。因此,(index_iter_ - 1)指向的 data block 里面所有的 K,都小于 target。 - 此外,
index_iter_.key()是大于等于 target 的。 - 下面还要证明
(index_iter_ + 1).key()指向的 data block 里面的所有 K 都大于 target。根据【性质2】我们知道index_iter_.key()会严格小于它指向的下一个 data block 中的所有 K,根据我们上一条结论可以知道 target 严格小于下一个 data block 中的所有 K,所以 target 如果存在的话,一定是当前 data block 上的。
1 | void TwoLevelIterator::Seek(const Slice& target) { |
接着调用 InitDataBlock 初始化 data_iter_。接着在 data block 层 Seek。
1 | ... |
Table::BlockReader
Table::BlockReader 创建一个 Iterator,这个 Iterator 实际上是一个 Block::Iter 对象,由 Block::NewIterator 产生。而 Block::Iter 的方法,例如 Seek,在前面已经介绍过了。
1 | Iterator* Block::NewIterator(const Comparator* comparator) { |
接受三个参数:
arg
这个类型设置就很奇怪,实际上是一个Table*,表示现在读的那个 Table 的上下文。index_value
1 | // Convert an index iterator value (i.e., an encoded BlockHandle) |
1 | ... |

