本文介绍 LevelDB 的 SSTable 之间的 Compaction。Compaction 分两种:
- Minor Compaction
对应 Memtable 到 SSTable 的过程。 - Major Compaction
对应 SSTable 文件之间的归并。涉及到两个 Level 的 SSTable 文件。
Major Compaction 中还可以细分,比如是否 Manual 等。对于非 Manual,还有 seek compaction 和 size compaction。
同样的,文章中的【Q】表示我在阅读源码的过程中产生的疑问,有的我找到的解答,或者自己产生了思考,有的则未必清楚。
目录:
- LevelDB 之 Memtable实现
- LevelDB 之 SSTable实现
- LevelDB 之 Version
- LevelDB 之 Compaction
- LevelDB 之 WAL
- LevelDB 之流程概览
首先来回顾一下 LevelDB 的整体架构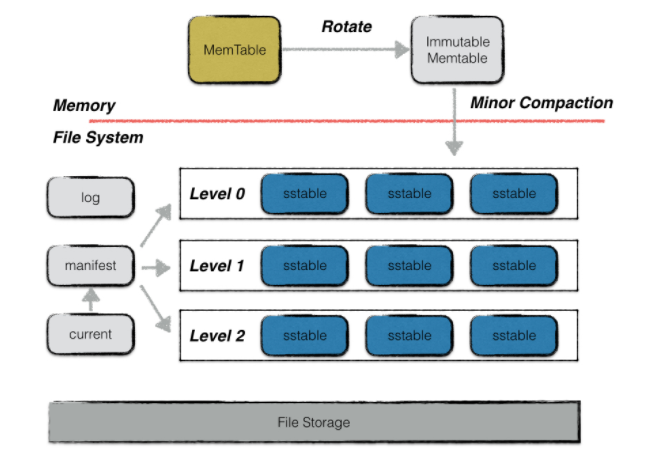
之前提到过,当一个 Memtable 满了之后,会转化为 Immutable Memtable。Immutable Memtable 会被 Dump 成 SSTable 文件,SSTable 文件是不可变的。
这里 GUARDED_BY(m) 实际上是 __attribute__(guarded_by(m)) 这个线程安全注解,方便编译器帮助检查有没有遗漏掉加锁的情况。
1 | class DBImpl : public DB { |
前置知识
读放大、写放大、空间放大
读放大表示每次读盘请求带来的实际读盘次数。
写放大是实际写入的数据大小除以期望写入的数据大小。
写放大和系统对数据的 Order 的要求的强烈程度有关。如果系统要求数据更有序,那么就需要花费更多的时间用来整理数据,从而产生更高的写放大。如果降低对数据有序性的要求,就会导致碎片越来越多,读放大和空间放大严重。
为什么 LevelDB 要针对写入优化呢?因为:
- 大多数读取请求可以由 Block Cache 兜住。
- 对于不存在的 Key,可以由 Bloom Filter 兜住。当然,这里 BloomFilter 的 False Positive 率就很敏感了,会直接影响到读取的性能。
LCS 和 STCS
有两种 Compaction 方案:Size-Tiered Compaction Strategy(STCS) 和 Leveled Compaction Strategy(LCS)。
本段参考了 https://github.com/facebook/rocksdb/wiki/Compaction。
STCS
Memtable 刷成小 SSTable。当这些小的 SSTable 达到一定个数时,会被 compact 成一个稍大些的 SSTable。当稍大些的 SSTable 又达到一定个数时,又会被一起 compact 成更大的 SSTable。每一层的 SSTable 之间是 overlap 的,组成了多个 run。
下图是 STCS 的一个示意,可以看到,每层的 SSTable 数量不变,但是大小越来越大。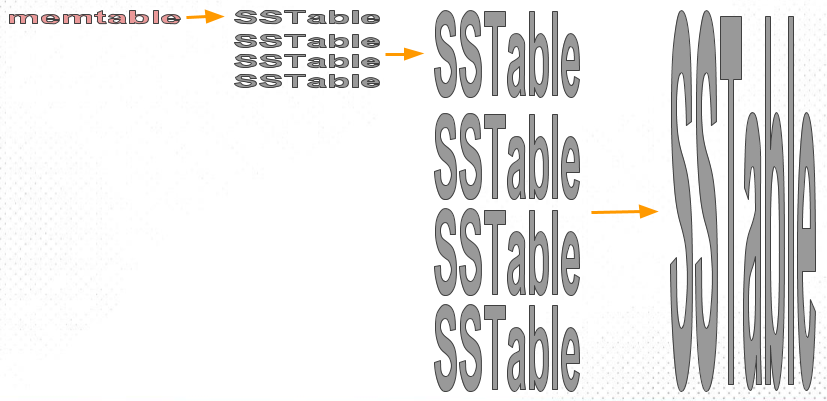
STCS 的写放大比较好,但读放大和空间放大高:
- 空间放大1
因为 Compaction 时,在新 SSTable 生成前,旧的 SSTable 不能删除,所以可能会造成额外一倍的开销。另外,LevelDB 中有 Version 的概念,其实更复杂。
为此,增加 SSTable 数量,而控制大小不变,不就能控制这额外一倍开销的绝对数量么?这是 LCS 的思路。 - 空间放大2
如果 Key 更新频繁,可能导致同一个 Level 以及不同 Level 中的 SSTable 中存在相同的 User Key,也就是版本太多。这些数据在被 Compact 后只会产生一个 Internal Key 了。
假设相邻 level 的 size 比为 T,每个 level 包含的 run 数达到 T 时即触发整层的合并,空间放大为 O(T)。 - 读放大
从数据量来说,点读基本上落在最后一层。range 读的可能需要合并多个层的数据,从而带来读放大。
LCS
为此就得到了 LCS:
- 当 Level0 层数量达到 Level0 层阈值时,将 Level0 和 Level1 层的所有 SSTable 做 Compaction。
实际上,具体涉及哪些 SSTable,在 LevelDB 中控制更为精细。并且 Compaction 的条件也更复杂。 - 如果 Level1 层的 SSTable 数量还是超过 Level1 层的阈值,再把这些超出的 SSTable 更下面的层做 Compaction。
- 除了Level0,其他层的所有 SSTable 中的 key 都是不重叠的。
下图是 LCS 的一个示意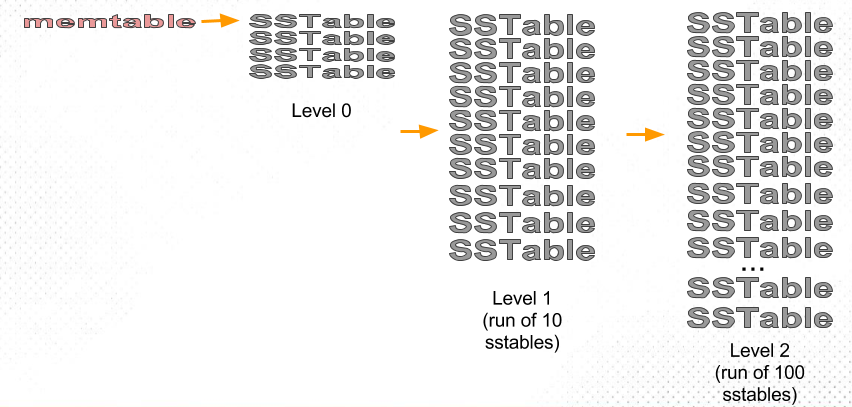
注意到,LCS 中,SSTable 的大小不变,但是数量会增多,Level N+1 的文件数量是 Level N 的 10 倍。这里的 10 倍也被称为 fanout。
【Q】这里看上去和 LevelDB 的实现还有区别,LevelDB 里面的 MaxBytesForLevel 函数更多的是计算了10倍的大小,Why?这个在“Major Compaction流程”章节中讨论过了,每个文件大小是固定的,LevelDB 通过限制每层的总大小来间接限制文件数量。这是为了在 dump 的时候更方便统计大小而不是文件数量。
所以,假如 Level1 有 10 个文件,Level2 就有 100 个文件。但是 key 在两个 level 中都是均匀分布的,因此 Level1 拿出一个文件出来,Level2 中估计只会有10个文件和它重叠,所以只需要合并重叠的这些文件就行了。
当然,LevelDB 中,Level0 是采用的 STCS 策略,就不讨论。
LCS 的空间放大相比 STCS 小很多。假如 fanout 是 10,因为 LCS 中最下面一层是有序的,也就是只包含一个 run,那么这个 LSM 中至少 10 / (1 + 10) 的数据是不重复的。而上层那个 1,就算都是和最下面一层重复的,也左右不了大局。当然,LCS 的空间放大也许不能始终达到最优,最坏情况下有 2-fold space amplification。此时最下面一层并没有被填满,而是大约等于倒数第二层的大小。
LCS 的缺点是写放大会比 STCS 显著提高:
- Compaction 因为需要 merge 成一个 run,所以涉及更多的文件,导致写放大变大。
在最差的情况下每一层的 Compaction 的写放大等于 fanout。也就是说要和下一层所有的文件进行合并。
但实际上会少一些,因为 Compaction 是 some to some 的,只涉及 overlap 的文件。
读放大也会更高:
- SST 文件变多。特别是对 L0 来说,因为他是会 overlap 的,所以文件变多之后需要读更多的文件,读放大更大。
【Q】既然 LCS 的写放大高了很多,为什么说基于 LSM 的写性能很好呢?可能是因为下面几点
- SSTable 是顺序写,性能好【Q】
- 根据RocksDB的文档,在一些情况下写放大不是很严重
首先是按 key 顺序的写,对于这种情况 RocksDB 可以优化。
其次是有 skew 的写,会导致只有小部分的 key 被更新。
层数和写放大的关系
考虑极限情况,也就是只有一层。那么 Memtable 在 flush 下来后,就可能需要和整个数据库中的所有 SST 文件进行 Merge,这会产生非常大的写放大。
那么是不是层数越多,写放大越小呢?从另一个方面考虑写放大,一个 Key 从写入,直到一步步被移动到最下层,会经过:
- WAL +1
- Minor Compaction +1
- L0->L1 Major Compaction +2
L0 和 L1 基本是全量的 Compaction。 - Major Compaction +11 each
所以可以看出,总的写放大是 4 + 11 * (n - 1)。如果层数 n 越大,那么总的写放大就越大。但一个 Key 不会在单次 Compaction 中就经历 n 轮的重写。
RocksDB 的实现
首先基本的 STCS 和 LCS 就不说了。
Tiered+Leveled
RocksDB 中 L0 是 Tiered,下面的是 Leveled。这也是默认模式。
L0 设为 Tiered 的好处是可以快速承接 Flush 下来的 Memtable。
Level-N
相比 LCS 有更高的读放大,和更小的写放大,实际上是个权衡。也就是从上层来的所有 SST 文件会和下层其中一个 SST 文件合并。
减少写放大
思路1:KV 分离
类似于 WiscKey 或者 Titan。这样的优化的特点是:
- 由于 Value 大小显著大于 Key 的大小,它占用了大部分的 Compaction 带宽。Compaction 的目的之一是为了排序,从而减少随机性,提高读取速度。而 Compaction 时,Value 是否参与对有序性的维护并无贡献。
- 对 Scan 不友好,需要通过 Prefetch 优化。如果需要该优化,那么保存 Value 的结构同样需要遵循 Key 的 Order。
- GC 的时候需要反查 Key。
- 存储 Value 时需要同时存储 Key。
WiscKey 收到一个写入请求的时候,先把 Key+Value 写到 vLog 的 head 处。这样可以省掉写 WAL 的一次 IO。相比 Compaction 的写放大来说,这只是小头。但是因为 Value 本身不要先写在内存的 Memtable 中了,所以实际上也减少了 Minor Compaction 的压力,从而减少了写放大。随后,WiscKey 会在 LSM 中写入 Key 和 Key+Value 在 vLog 中的位置。对点查而言,WiscKey 需要先查 LSM 找到 Value 的地址,再到 vLog 中插,多一次 IO。对扫表而言,支持 Prefetch,也就是从 LSM 处拿多个地址,然后从 vLog 中一次性读出。
WiscKey 的 vLog 是一个环形结构。Key+Value 在 head 处写入,而 GC 发生在 tail 处。根据 tail 处的 Key 反查 LSM,如果 Key 在 LSM 中存在,并且记录的位置也等于 vLog 中的位置,则将这个 Key+Value 移动到 head,否则前进 tail,表示删除。容易发现,一轮 GC 后,如果 Key 还存在,那么它的位置也会变更,这导致需要重新在 LSM 中记录新位置。如果存在 Snapshot,这会使得复杂度变高。
针对 WiscKey 的方案还可以进行优化。例如对 Key 进行冷热分离的存储,只有比较冷的 Key 才会被存入 vLog 中。
思路2:Partition
限制一个 LSM 引擎管理数据的大小。这里就需要进行 Partition。可以通过 Range 或者 Hash 进行 Partition。
Partition 的问题是 Split/Merge 或者 Rehash 同样可能造成写放大或者空间放大。
思路3:容忍一定程度的无序
PebbleDB 将每一层分为多个 guard,guard 之间不 overlap。guard 中存有多个 overlap 的 SST 文件。
Compaction 主流程
总览
调用路径
列表中的下层会调用上层
- BackgroundCompaction 这个函数是 Compaction 的主入口,会区分各种 Compaction 种类进行执行。
- BackgroundCall 主要负责调用 BackgroundCompaction 和调度 BackgroundCompaction
- BGWork 可以理解为就是 BackgroundCall
- MaybeScheduleCompaction
会 Schedule 方法BGWork。
这个函数在 BackgroundCall,以及诸如 DBImpl::Get 等读写方法中都会被调用。
DBImpl::Get 中调用不会导致这个函数被重复调度,因为 BackgroundCall 中会检查如果 background_compaction_scheduled_ 设置了,就不会再调度。
- MaybeScheduleCompaction
- BGWork 可以理解为就是 BackgroundCall
- BackgroundCall 主要负责调用 BackgroundCompaction 和调度 BackgroundCompaction
Compaction种类
- Minor Compaction
存在 Immutable Memtable 即imm_。那么会在BackgroundCompaction中被调用CompactMemTable,即 Minor Compaction。
在 Recover 过程中ApproximateMemoryUsage检测到 Memtable 超限,会直接触发对 Memtable 的 Compaction。但这个 Compaction 是局部的,因为在恢复过程中,所以不需要诸如 LogAndApply 这种维护 Version 的工作。 - Manual Compaction
CompactRange 调用。 size_compaction
在VersionSet::PickCompaction中检查并启动。
当 Level0 文件数目过多,或者某个 Level 的总大小过大。seek_compaction
seek 次数太多。当一个 key 在某一层落到 range 里面,但是找又找不到时,就需要到下一层中去查找。假如在Level(n)中没找到,但是在Level(n+1)中找到了,就认为Level(n)有一次未命中。容易发现如果未命中次数多了,就说明 Level N 和 Level N+1
的文件 overlap 很厉害,这就需要通过一次 Major Compaction 来解决这个问题。这就不用再在Level(n)中找了。
Compaction条件
在函数 NeedsCompaction 中判断当前 Version 的:
compaction_score_导致 size compaction
在 VersionSet::Finalize 更新。也就是当前版本中 Level0 层中文件数量,或者其他层中的文件大小,只要有一层的超过阈值,NeedsCompaction 就是 true。file_to_compact_导致 seek compaction
在 Version::UpdateStats 中更新。也就是在读的过程中,会不断设置GetStats::seek_file表示当前正在读取的文件。
1 | bool NeedsCompaction() const { |
DBImpl类
LevelDB 通过 class DB 对外暴露 C++ 接口,这个 DB 的实现就是 DBImpl。
Compaction 的触发和调度
DBImpl::BackgroundCall
BackgroundCall 是在后台线程中执行的。
1 | void DBImpl::BackgroundCall() { |
MakeRoomForWrite 函数会使用 background_work_finished_signal_ 等待 Compaction 结束。所以在可能完成一次 Compaction 之后,会 signal 一下这个 CV。
1 | ... |
DBImpl::MaybeScheduleCompaction
函数 MaybeScheduleCompaction 用来调度 BGWork,而这个函数主要就是做 Compaction。MaybeScheduleCompaction 在 DBImpl::Get 时也可能被调用。其调度关系上文已经讲了。
这里需要加锁,LevelDB 只允许一个后台进程做 Compaction。
1 | void DBImpl::MaybeScheduleCompaction() { |
PosixEnv::Schedule
这里的 env_ 的实现实际上是一个 PosixEnv。
查看源码,Schedule 中会先判断 started_background_thread_ 是否为 true。否则就创建一个 background_thread,然后 detach 掉。
接下来就是一个生产者消费者模式。
1 | void PosixEnv::Schedule( |
下面放一下消费者的代码
1 | void PosixEnv::BackgroundThreadMain() { |
有点奇怪,是先 Signal,再入队。这样不会导致消费者从 Wait 中醒过来,发现 background_work_queue_ 还没被入队么?这里其实是通过消费者中 while (background_work_queue_.empty()) 来避免的。如果从 Wait 出来后,发现条件不满足,那么就会继续 Wait。而一旦从 Wait 出来,CV 的实现是保证 background_work_mutex_ 是被持有的,所以 background_work_queue_ 不会再被更改。
有关条件变量,可以参考并发编程重要概念及比较。
和Compaction的实际执行
DBImpl::BackgroundCompaction
这个过程是 Compaction 的主过程,需要全程持锁。
Minor
在 BackgroundCompaction 中先处理 CompactMemTable,也就是 Minor Compaction。这个肯定是优先级更高的,因为总共只有两个 Memtable,所以肯定想把 Immutable Memtable 快速腾空。
1 | void DBImpl::BackgroundCompaction() { |
非Minor Compaction
详见 Major Compaction 章节。
Minor Compaction 流程
CompactMemTable
主要流程三部分:
- WriteLevel0Table
- 将 Immutable Memtable 生成 SSTable 文件
这个文件的基本信息写到FileMetaData里面,并在最后写入VersionEdit。
注意,在 Recover 的过程中,这里其实也可以传入 Memtable。 - 计算添加到哪一层
这个文件未必会放到 Level0,可能会直接放到 Level1 甚至 Level2,具体由kMaxMemCompactLevel控制。 - 将上面说的
FileMetaData写入 VersionEdit
因此这个函数的实际返回是传入的VersionEdit* edit。
- 将 Immutable Memtable 生成 SSTable 文件
- LogAndApply
用得到的VersionEdit,去更新数据库状态。 - RemoveObsoleteFiles
重置 Immutable Memtable。
删除无用文件。主要包括kLogFile/kLogFile/kTableFile等。
1 | void DBImpl::CompactMemTable() { |
下面,就是要把 edit 应用到当前的 VersionSet 上。
解释下 edit.SetLogNumber(logfile_number_):
- edit 的
log_number_之前是对应了现在 Immutable Memtable 的log_number_。 logfile_number_对应了现在 Memtable 的log_number_,它在 MakeRoomForWrite 中创建新的 Memtable 的时候就被更新了。
我们要做的是用现在 Memtable 的 log_number_ 替换掉现在 Immutable Memtable 的 log_number_。 从前,因为 Immutable Memtable 还没落盘,那显然它对应的 log 还是需要的,所以它应该存在在 base 中。现在,新 Version 中它已经落盘了,那么对应的 log file 就不再需要了。所以要在 edit 中记录了当前 Version 对应的日志起始编号。然后通过 LogAndApply 创建一个新的 Version。
1 | ... |
下面是清理掉 Immutable Memtable,并且调用 RemoveObsoleteFiles。
1 | ... |
WriteLevel0Table
在前文中,已经介绍过了 WriteLevel0Table 的作用,下面看实现。
首先计算出一个 NewFileNumber,也就是落盘时体现的文件名。这个函数之前已经介绍过了,它会生成诸如 MANIFEST-xxxxx 或者 yyyyy.log 这些 Manifest 和 Log 等等之类文件的序号。
pending_outputs_ 中保存了所有正在 Compact 的 SSTable 文件,这些文件不能被删除。这引发了我两个问题:
- 什么时候会删除这些文件?
在RemoveObsoleteFiles里面,马上就能看到了,不急不急。 - 为什么在 BuildTable 之后就可以清理掉
pending_outputs_结构了?
1 | Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit, |
接着,BuildTable 创建一个 TableBuilder 写入数据。这个函数在 LevelDB 之 SSTable 实现 中介绍过了。
值得注意的是,这里并没有加锁。我之前认为这是因为 BuildTable 里面会自带加锁,但是检查代码并没有。而且 BuildTable 也是要等文件全部写完,然后 fsync 的,所以可能确实是同步写吧。
1 | ... |
新生成的文件未必会放到 Level0,可能会直接放到 Level1。例如,如果新的 SSTable 文件和 Level1 中的文件没有重叠,那么就有可能被放到 Level1,具体还需要查看 Level2 和新 SSTable 的重叠情况。这通过 PickLevelForMemTableOutput 来计算,我们在 LevelDB之Version 中已经介绍过了。
下面的 edit->AddFile 就是将这个 SSTable 加到当前的 VersionEdit 中。
1 | ... |
env_ 实际上是封装了文件系统等操作。
1 | ... |
RemoveObsoleteFiles
清理文件的范围?看 env_->GetChildren 的实现,应该是所有该 db 下的文件。
1 | void DBImpl::RemoveObsoleteFiles() { |
清理文件的类型?
- 日志:从当前的 LogNumber 开始保留
- Manifest 文件:从当前的 ManifestFileNumber 开始保留
- TableFile
- TempFile
1 | ... |
Major Compaction流程
思考
在开始研究 Major Compaction 前,思考下列问题:
L0 中的 SST 文件是 Overlap 的。可是为什么 Level0 使用 Tiered 策略而不是 Leveled 策略?
如果 Memtable 向 L0 中的 Minor Compaction 使用了 Leveled 策略,那么很可能会导致整个 L0 被重写。而我们只有 Mutable 和 Immutable 两个 Memtable,为了减少 Memtable 的 flush 的开销,所以 Level0 使用 Tiered 策略。对于 Level0 里面的文件,能不能直接选一个和 Level1 中的文件 Merge?
答案是不行的,可以看下GetOverlappingInputs的论述。如果 level 中的某个文件的 key 的 range 过大,它可能和 level+1 层的很多文件有重合,这样的 compaction 写放大很重,如何解决这个问题?
首先,这也是为什么 LevelDB 要分成很多层的原因,在 Merge 的时候,最多和下一层中的所有文件 Overlap,写放大是被分摊的。
其次,在 Compact 的时候,LevelDB 一直关注和 level+2 层的 key 的重叠情是否超过一定量,即MaxGrandParentOverlapBytes函数。- 在
ShouldStopBefore判断是否要结束当前 SSTable 写入,新开文件的时候,考虑当前文件和 level+2 的 Overlap,如果过了,就新开文件。 - 在
IsTrivialMove判断是否可以直接移动文件到下层的时候,考虑要移动的文件和 level+2 层的 Overlap,如果过了,就不能移动。 - 在
PickLevelForMemTableOutput选择 Minor Compaction 的层时,考虑这个 Immutable Memtable 的 Overlap,如果过了,就不能放在这一层。
- 在
从 level 到 level+1 的 Compaction 会对 level+2 产生什么影响?
LevelDB中多个不相干的合并是可以并发进行的,这个的实现是怎样的?
需要注意,Level0 文件是彼此 Overlap 的,所以是相干的。
【Q】那么当一个 Major Compaction 开始的时候,是如何判定是否相干,如果不相干就不 Compact 的呢?从 LevelDB 的代码来看,只有一个后台线程进行 Compact 操作,所以我认为虽然在设计上 LSM 树是允许并行 Compact 的,但是 LevelDB 并没有实现,但 RocksDB 肯定是实现的。LevelDB 中,每个 user key 在一层中是不是只会出现一次?
大多数情况是的,有两个例外。
首先,Level0 是 Overlap 的,可能有多个。
其次,如果使用了 Snapshot,那么在下层可能也会有 user key 相同,但是 sequence 不同的。见AddBoundaryInputs的论述。我们往 Manifest 文件里面写了什么?
见 LevelDB之Version。LevelDB 有容量限制么?
应该是没有的,但是当最下面一层变得特别大之后,Compaction 的开销会很大。LevelDB 到底是限制的每一层的文件数量还是大小?
【Q】如果限制的是总大小,如果保证生成的 SSTable 的大小是大致相同的?
对于 Major Compaction 来说,是在DoCompactionWork里面通过下面的代码来判断的,也就是说当文件大小达到一定规模后,就会产生新的文件了。1
2
3if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
status = FinishCompactionOutputFile(compact, input);这个调用最后会转到
options->max_file_size上。LevelDB 每一层的文件数量有限制么?
首先 Level0 肯定有,大家说是4个么?我觉得不是。参考下面的代码,4只是表示有4个文件就开始 Level0 的 Compaction。当文件数达到12个,才是上限,这个时候就要停止写了。1
2
3
4
5
6// Level-0 compaction is started when we hit this many files.
static const int kL0_CompactionTrigger = 4;
// Soft limit on number of level-0 files. We slow down writes at this point.
static const int kL0_SlowdownWritesTrigger = 8;
// Maximum number of level-0 files. We stop writes at this point.
static const int kL0_StopWritesTrigger = 12;LevelDB 底层 SSTable 中的数据永无出头之日么?
怎么可能,只要数据被修改,那么就会先到 Memtable 里面。Compaction 是如何删除文件的?
详见 DoCompactionWork。对于一个 Key 有多个 Put 和 Delete 的情况下,有哪些 Put 和 Delete 是可以被删除的呢?
见 DoCompactionWork。可以列出几点:- 如果只有一个 Delete,并且这个 Delete 是最新的,也不能删除这个 Delete 记录。这是因为可能这个 Key 在没处理到的更下层有记录。这样尽管我们删掉了这最新的 Delete 记录,但查找的时候会在更下层找到对应的 Key。
- 如果有连续多个 Put,可以干掉较老的 Put。
Compaction 类
Compaction 类定义在 version_set.h 文件里面。它主要用来管理非 Minor Compaction。
成员:
std::vector<FileMetaData*> inputs_[2];
表示这个 Compaction 涉及的两个 level 的文件,也就是输入。
其中 level 层是inputs_[0]。level + 1层是inputs_[1],称为 parents。
【Q】这里面的文件会按照 key 的顺序来排列么?从 PickCompaction 来看是这样的。std::vector<FileMetaData*> grandparents_;
level + 2 层的文件,通常称为 grandparents。size_t level_ptrs_[config::kNumLevels];size_t grandparent_index_;bool seen_key_;int64_t overlapped_bytes_;size_t level_ptrs_[config::kNumLevels];
函数:
int level() const { return level_; }
我们将level_和level_+1层进行 Compact。int num_input_files(int which) const
表示那两个 inputs_ 中分别有几个文件。bool IsTrivialMove() const;
是否可以直接移动,而不涉及 merge 或者 split 操作。bool ShouldStopBefore(const Slice& internal_key);VersionEdit* edit() { return &edit_; }/edit_
Compaction 肯定会有文件增删,即使仅仅是 TrivialMove,也是跨层的,所以会导致变化。这里需要一个VersionEdit来描述。
IsTrivialMove
这个函数用来判断在 Major Compaction 的时候能不能直接移动老的文件到下面一层,免去归并生成新文件的开销。需要同时满足三个条件:
- level 层只有一个 SSTable
【Q】疑问:如果 level 层有多个,level+1 层没有,直接移动到下面一层安全么?禁止这么做的目的是什么?
检查对GetOverlappingInputs的分析,可能是不安全的。如果说 Level0 的某个文件f和 Level1 的文件有 Overlap,那么就必须要扫描整个 Level0 层的所有文件,将与f有 Overlap 的文件都要移到下一层。 - level + 1 层没有
这个原因应该好理解,如果 level+1 层有,那就得比较和这个文件有没有 Overlap。 - 和 level + 2 层的 overlap 没有超过阈值(实际上是20M)
1 | bool Compaction::IsTrivialMove() const { |
这三个条件满足,就可以将文件从 level 移动到 level+1。
DBImpl::CompactionState 类
DBImpl::CompactionState 这个类封装了 Compaction,这是因为要处理两个 Level 之间的合并,所以要加一些额外的字段。
SequenceNumber smallest_snapshot;
小于smallest_snapshot的 Sequence Number 是不重要的,因为不会提供smallest_snapshot的 snapshot。
所以,如果看到 Sequence Number 小于等于smallest_snapshot的某个S,就可以丢弃小于S的这个 key 的其他版本。
【Q】这里是不是在说,如果只有 S 这个独苗,那还是要写进去的?std::vector<Output> outputs;Output* current_output() { return &outputs[outputs.size() - 1]; }
保存每个输出文件的元信息。例如 smallest 和 largest。WritableFile* outfile;
Major Compaction 过程中,需要输出到 level+1 层的文件。注意,可能有多个这样的文件,参考ShouldStopBefore。TableBuilder* builder;uint64_t total_bytes;
DBImpl::BackgroundCompaction
下面是对 Major Compaction 的处理。
构造Compaction对象
首先处理 Manual Compaction 的情况。
如果manual_compaction_不是 null,就触发 Manual Compaction。我没看到非测试的代码里面有设置manual_compaction_的,但是leveldb_compact_range这个 api 会显式调用CompactRange,并且DB这个接口中也有CompactRange方法,也就是说 LevelDB 对外暴露这个方法。1
2
3class LEVELDB_EXPORT DB {
...
virtual void CompactRange(const Slice* begin, const Slice* end) = 0;其次,调用
PickCompaction处理 size compaction 和 seek compaction 的情况。
PickCompaction会返回当前要 Compact 的文件,如果返回 null,就啥事都不做。对于PickCompaction而言,如果既没有 size compaction,又没有 seek compaction,返回 null。
这个过程是持锁的
1 | void DBImpl::BackgroundCompaction() { |
根据Compaction对象进行Compact操作
经过上面的代码得到了一个 Compaction* c 对象,下面是两种平凡情况:
- 如果之前
PickCompaction没给出这c,那么就说明这一次不要 Compact。 - 如果满足
IsTrivialMove条件,就可以不生成新的文件,直接将原文件移动到下一层。
对于 Trivial 的情况直接更新c->edit(),不走InstallCompactionResults的逻辑了。
主要就是将 level 层的 SSTable 移动到 level+1 层。然后调用 LogAndApply 来得到一个新的 Version。 - 如果不满足
IsTrivialMove条件,就是一般情况,由DoCompactionWork处理。
1 | ... |
DoCompactionWork 进行 Compaction。
然后要 CleanupCompaction:
- 清空 compact 对象
- 根据
compact->outputs,找到pending_outputs_里面对应的文件,并移除出pending_outputs_
compact->outputs记录了每个输出文件的元信息,而pending_outputs_记录了正在 compact 的文件,compact 结束后,就把这些文件移出去。
在 Major Compaction 中,文件是在DoCompactionWork -> OpenCompactionOutputFile中被加入pending_outputs_的。
1 | ... |
收尾
如果是 Manual 的,需要清空 Manual 状态。
1 | ... |
Version::PickCompaction
PickCompaction 用来生成一个 Compaction 对象。
size compaction 的优先级是高于 seek compaction 的,所以 PickCompaction 首先处理 size_compaction。
首先是处理 size compaction,这个 compaction 的缘由是某一层太大了,所以具体 compact 哪个 range 是可以优化的。在 LevelDB 中,size compaction 每次 Compact 的 range 是轮流来的。compact_pointer_[level] 记录了上一次这一层 Compaction 到了哪里,也指定了下一轮 Compaction 从哪里开始。遍历 current_->compaction_level_ 这一层的所有文件,找到第一个 largest 大于 compact_pointer_[level] 的文件,放到 Compaction* c 的 inputs_[0] 中。表示要将这个文件合并到下一层。
如果一轮循环下来没找到,说明所有的文件的 largest 都小于 compact_pointer_[level],也就是这一层所有的 key 都小于 compact_pointer_[level],那就把第一个文件放进去。
1 | Compaction* VersionSet::PickCompaction() { |
对于 seek compaction,是某些具体的文件需要被 compact,所以就不用 compact_pointer_[level],而是把要 Compact 的那个文件加到 c->inputs_[0] 就行。
1 | ... |
对于 Level0,有个特别的处理,因为 Level0 的 sst 是互相重叠的,所以要将所有相互重叠的 sst 都选出来。具体实现参考 GetOverlappingInputs 函数的说明。
1 | ... |
现在已经得到了 c->inputs_[0]。除了 c->inputs_[0] 的情况,否则 c->inputs_[0] 里面都只有一个文件。
通过 SetupOtherInputs 可以计算 c->inputs_[1],也就是 level+1 层有哪些 sst 文件和 inputs_[0] 中的文件重叠。
1 | ... |
Version::SetupOtherInputs
SetupOtherInputs 计算在 Compaction 时,level+1 层上有哪些文件重叠,从而要放到 c->inputs_[1] 上。在这个函数之后,就得到了正确的 c->inputs_ 数组、c->grandparents_ 字段,以及 compact_pointer_ 字段。在这个函数之后,PickCompaction 就结束了,BackgroundCompaction 会执行后面的流程,也就是 DoCompactionWork。
基本的思想是:所有和 level 层有重叠的 level+1 层文件都要参与 Compact。得到这些文件后,再继续看利用这些 level+1 层的文件,能不能 Compact 更多 level 层的文件?
这个函数被 CompactRange 和 PickCompaction 调用,也就是所有的 Major Compaction 逻辑都会走到这里。
GetRange和GetRange2
GetRange 计算 inputs_[0] 或 inputs_[1] 覆盖的区间。通过 smallest 和 largest 返回。
GetRange2 计算 inputs_[0] 和 inputs_[1] 覆盖的区间。
GetRange 很简单,顺序遍历每一个文件,然后更新 smallest 和 largest,这里注意都需要 icmp_.Compare。
1 | void VersionSet::GetRange(const std::vector<FileMetaData*>& inputs, |
GetRange2 也很简单,就直接合并 inputs_[0] 和 inputs_[1] 的内容到一个 vector 里面,然后调用 GetRange。
1 | void VersionSet::GetRange2(const std::vector<FileMetaData*>& inputs1, |
AddBoundaryInputs
AddBoundaryInputs 是一个很重要的函数,是后来加进去的。它关系到Issue 320和PR 339。AddBoundaryInputs 函数也是在那个时候引进的。不过值得注意的是,这个 patch 在2016年就提了,但是2019年才被合进去。只有很少的 Blog 能讲明白这个函数的来龙去脉。
接受的参数:
- level_files 表示当前要处理的 level 中的所有文件
- compaction_files 一般是
c->inputs_[0]
翻译一下 AddBoundaryInputs 这个函数的注释:
- 提取出
compaction_files里面最大的文件 b1,也就是这个 level 中的最大文件。 - 然后在
level_files里面找到一个 b2,满足 b1 和 b2 的 user key 是相等的,这样的 b2 称为 boundary file。
需要将这个 b2 加入到compaction_files,也就是c->inputs_[0]里面,并且更新 largest_key,继续找上界。
如果有两个 SSTable 文件,范围分别是 b1=(l1, u1) 和 b2=(l2, u2),且 user_key(u1) 等于 user_key(l2)。如果只 Compact 文件 b1,不 Compact 文件 b2 到更下面一层的话,在读取 u1 的时候就会出错。因为 b1 在 b2 上层了,所以只会返回 b2 的结果,而永远不会返回 b1 的结果。甚至 b2 的结果可能还是一个较旧的数据,因为根据 Memtable 里面的介绍,Sequence Number 是从新到旧来排序的。
这实际上是在说,user key 跨越多个 SST 文件边界的问题。Issue 320 上提到这个可能在 Snapshot 场景下发生。
1 | void AddBoundaryInputs(const InternalKeyComparator& icmp, |
【Q】看起来,这个函数做的是和 GetOverlappingInputs 一样的事情,他们的区别是什么呢?首先,GetOverlappingInputs 的初心不是扩展边界,而是计算某一层和某个 range 重合的文件,只是对 Level0 要特殊处理一下。其次,这篇文章中进行了解释:
如下图所示,两个 SSTable 中,出现了 user key 相同(都为 key2)但是 Sequence Number 不同的两个 Internal Key。
可以看到 GetOverlappingInputs 的特殊处理关注的是 Level0 上某一个要 Compact 的文件中的所有 key 是否还会出现在其他的 SSTable 文件中。而 AddBoundaryInputs 关注的是某个 Key 的其他版本是否还会出现在其他的 SSTable 中。
【Q】这里引发了第二个疑问,为什么同一层中会出现两个相同 user key 的 Key 呢?我觉得可能因为这个 Key 出现在两个 SSTable 的边界上,所以这个函数叫 AddBoundaryInputs 吧。
其实我觉得更好的设计是想办法让 user key 按照 SST 边界切割。但仔细回顾一下 DoCompactionWork 的实现,似乎是可能没处理完一个 Key,就 ShouldStopBefore 了的。但即使这样,后面的文件里面也不会再写有关这个 user key 的内容了。那么究竟在什么情况下会发生这种情况呢?根据这篇文章中指出 Snapshot 机制会导致“同一层中会出现两个相同 user key 的 Key”这个问题。
【Q】这里引发了第三个疑问,出现了两个 user key,会不会影响读取呢?实际上只要位于同一层就不影响,因为根据 Memtable 里面的介绍,Sequence Number 是从新到旧来排序的。我们的查找方式允许每一次都找到 b1 里面的值,也就是始终是一个最新的数据。
实现
FindLargestKey 用来找一系列文件中最大的 key,如果是空的,则返回 false。否则遍历这些文件,统计出最大的 key。
现在找到了 compaction_files 也就是 c->inputs_[0] 中最大的 key,即 largest_key 了。
然后用 FindSmallestBoundaryFile 在 level_files 中找最小的 b2=(l2, u2),满足 l2 > u1 且 user_key(l2) = user_key(u1)。这里的 u1 就是 largest_key。
如果不存在这样的文件,就退出循环。如果存在这样的文件,那么说明存在 Boundary File,我们要将这个文件加到 compaction_files 里面,然后更新 largest_key 为这个 Boundary File 的 largest,继续搜索。为什么可以直接更新呢?因为找到的 l2 肯定大于 largest_key 了,那么 u2 也就是这里的 largest 肯定更大于了。
1 | ... |
再看一下 FindSmallestBoundaryFile。其实这里有个疑惑,level_files 有可能是无序的么,为什么这里还是线性遍历?
1 | // Finds minimum file b2=(l2, u2) in level file for which l2 > u1 and |
SetupOtherInputs 主体
首先计算 all_start 和 all_limit,也就是整个 Compaction 过程涉及的区间:
AddBoundaryInputs扩充一下c->inputs_[0]。
防止在current_->files_[level]的后续的 SST 文件中还存在相等的 user key。- 用 GetRange 获得 Level N 的 range。
- 用 GetOverlappingInputs,根据 Level N 的 range,计算出 Level N+1 和 Level N 重叠的 SSTable 文件,并放入
c->inputs_[1]。 - 用 GetRange2 计算 Level N 和 Level N+1 合并起来的 range。
1 | void VersionSet::SetupOtherInputs(Compaction* c) { |
然后,如果 Level N+1 和 Level 1 存在重叠,即 c->inputs_[1] 不为空。则:
- 首先用 GetOverlappingInputs 再更新一下
原因是 GetRange2 又一次扩大了 all_start 和 all_limit,需要重新计算一下和level层的 overlap。 - 调用
AddBoundaryInputs处理level层的边界。 - 如果新的边界实际让
c->inputs_[0]变得更大了,新的数据大小在阈值- 重新计算
c->inputs_[1]即 expanded1,如果没有使c->inputs_[1]更大,则拓展 all_start 和 all_limit - 否则就不拓展。也就是说不会再扩展
c->inputs_[0]了。
- 重新计算
为什么这样是安全的呢?我觉得有几点:
- 因为 Compact 之后是到 level+1 层的,所以 level+1 层不存在 boundary 问题。
1 | ... |
下面,设置一下 c->grandparents_ 这个字段。
1 | ... |
记录下一轮的 compact_pointer_。我们在这里立即更新,而不是等到 VersionEdit 被 Apply 的时候更新,这样当 Compaction 失败后,能下次能尝试一个不同的 key range。
- 【Q】什么是
compact_pointer_?
查看PickCompaction函数,它会找到 largest 大于compact_pointer_[level]后的第一个文件。
可以发现,其实每一次要 Compaction 的文件就是通过compact_pointer_指定的。 - 【Q】在这之后,Compaction 会因为什么失败?
1 | ... |
DoCompactionWork的辅助函数
MakeInputIterator
Create an iterator that reads over the compaction inputs for “*c“. The caller should delete the iterator when no longer needed.
分两种情况:
- 如果是 Level0,则将这一层中的所有文件对应的 iterator 加入到 list 中
- 如果是其它层,则创建一个基于这个层的 LevelFileNumIterator + NewTwoLevelIterator
LevelFileNumIterator 用来遍历这一层中的所有的文件。返回每个 entry 的 key 是每个文件的最大的 key,value 是这个文件的一些信息。我想这个迭代器应该要依赖传进来的c->inputs是有序的。
1 | Iterator* VersionSet::MakeInputIterator(Compaction* c) { |
DBImpl::DoCompactionWork
DoCompactionWork 是一般情况下的 Major Compact 过程,来自 BackgroundCompaction 的调用。
那么这个函数做啥呢,不就是个归并排序么?且慢,考虑几个问题:
- 如何处理同一个 user key 有不同 Sequence Number 呢?
目标肯定是只保留最新的。 - 如何兼容 Snapshot
其中 CompactionState 封装了 Compaction。
几个 assert:
- 要压缩的 Level N 层是要有文件的。
- 几个结构是 nullptr。
1 | Status DBImpl::DoCompactionWork(CompactionState* compact) { |
根据文章:
- 如果有 Snapshot,则保留大于 Snapshot SN 的所有 Record,以及在小于 Snapshot SN 的 Record 中,SN 最大的 Record。
在这个函数的后半部分判断是否要删除某个键的时候,会先检查那个键的 SN 要小于等于 smallest_snapshot。从而保证这个键比最老的 Snapshot 还要老,这样才能删掉。 - 如果没 Snapshot,则设置 smallest_snapshot 为 LastSequence。
也就是说可以删除掉所有的旧的 KV。
1 | ... |
我们执行 MakeInputIterator,得到的迭代器可以按照 key 大小遍历所有冲突文件中的每个 KV 对。
1 | ... |
下面这个 while 循环遍历刚才得到的迭代器 input,进行 Major Compaction。
但且慢,每一次前进 input 迭代器前,都需要先检查有没有 Immatable Memtable,如果有的话,就需要先执行 Minor Compaction。这也说明了 Minor Compaction 的优先级更高。
简单再介绍下原子操作:
shutting_down_,采用了 Release-Acquire 内存模型,保证了一定的并行顺序。
如果线程 A Release Store,线程 B Acquire Load,那么线程A中所有在 Release 前的(atomic或者非atomic)写,对线程 B 都可见。has_imm_,采用了 Relaxed 内存模型。
只保证读写的原子性,不保证并发时和其他变量的 Order。因为加锁之后,会再检查一遍imm_是否为空。
【Q】这里有个问题,如果这中间 Minor Compaction 了,这也意味着在某一层可能多了一个 SSTable,它是可能 overlap 的,是不是需要重新计算 range?
1 | ... |
检查当前输出文件(应当位于level+1层)是否与level+2层文件有过多冲突,如果是就要完成当前输出文件,并产生新的输出文件。
1 | ... |
下面就是判断是不是能 drop,也就是和前面计算的 compact->smallest_snapshot 比较。
正常情况下 ParseInternalKey 不会失败,我们跳过这个分支。
1 | ... |
下面这个 if,判断的是 current_user_key 第一次出现的情况。包括处理完上一个 user key,到达下一个 user key,或者刚开始处理第一个 user key 的情况。设置 last_sequence_for_key 为最大的 kMaxSequenceNumber,我们不丢弃这种情况下的 key。
1 | ... |
下面比较 Sequence Number,如果 last_sequence_for_key 都小于 compact->smallest_snapshot 了,那么我这个 key 肯定更小,这是因为Sequence Number是按照降序排列的。对于这种情况,省点事,直接不要了。
1 | ... |
下一个判断复杂点,表示对于特定情况下,一个删除操作也是可以丢掉的。
如果:
- 某个删除操作的版本小于等于
smallest_snapshot
这说明这个 Key 的 Sequence Number 一定小于最小存活的 Snapshot。 - 并且在更高层没有相同的 user key,那么这个删除操作及其之前更早的插入操作可以同时丢弃了
IsBaseLevelForKey 用来判断更高层有没有这个 key 了。
1 | ... |
如果 drop 条件不符合,那么就写入到 compact->current_output() 里面,同时更新 largest。
同时我们关注文件大小,如果超限了,就 FinishCompactionOutputFile。
1 | ... |
截至现在,我们已经遍历完迭代器了。
1 | ... |
更新状态
1 | ... |
下面加锁。所以其实在遍历 input 这个迭代器的时候,是没有在加锁的。InstallCompactionResults 是一个关键过程,它将这次 Compaction 的内容加入到 VersionEdit 里面,并且最终调用LogAndApply。内容包括什么呢?增加和删除的文件:
InstallCompactionResults会调用Compaction::AddInputDeletions,需要删除的文件,包括input_[0]和input_[1]- 向
compact->compaction->edit()中添加compact->outputs中的所有文件
1 | mutex_.Lock(); |
Reference
- https://zhuanlan.zhihu.com/p/34674504
- https://blog.csdn.net/tmshasha/article/details/47703245
- https://zhuanlan.zhihu.com/p/51573929
- https://leveldb-handbook.readthedocs.io/zh/latest/basic.html
- https://blog.lovezhy.cc/2020/08/17/LevelDB%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%EF%BC%88%E4%BA%94%EF%BC%89-%20CURRENT%E5%92%8CManifest/
- https://sf-zhou.github.io/leveldb/leveldb_08_complete_process.html
- http://blog.jcix.top/2018-05-11/leveldb_paths/
- http://bean-li.github.io/leveldb-version/
- https://zhuanlan.zhihu.com/p/46718964
- http://www.hootina.org/blog/articles/leveldb%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/leveldb%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%9019.html
- https://sf-zhou.github.io/leveldb/leveldb_08_complete_process.html
这是一个DB完整执行过程的表述。 - https://izualzhy.cn/leveldb-PickCompaction
解释了GetOverlappingInputs的原理 - http://lerencao.github.io/posts/lsm-tree-compaction-strategy/
- http://www.scylladb.com/2018/01/17/compaction-series-space-amplification/
上面两篇文章介绍STCS和LCS - https://zhuanlan.zhihu.com/p/181498475
图解Compact过程 - https://github.com/facebook/rocksdb/wiki/Compaction
RocksDB对Compaction的讲解 - https://blog.csdn.net/weixin_36145588/article/details/78064777
- https://sf-zhou.github.io/leveldb/leveldb_09_compaction.html
这位同学解释了AddBoundaryInputs的来源 - https://blog.didiyun.com/index.php/2018/11/20/leveldb-compaction/
- https://www.cnblogs.com/cchust/p/6007486.html
介绍了 Compaction 的一些理论 - https://zhuanlan.zhihu.com/p/458198720
也是理论方面的介绍 - https://zhuanlan.zhihu.com/p/141186118
分析了一些读写空间放大的情况 - https://zhuanlan.zhihu.com/p/37003275
对于 Compaction 的总体性的理解

